 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Evaluation Protocol and Benchmarking Results for Extendable Cross-media Retrieval
Paper and Code
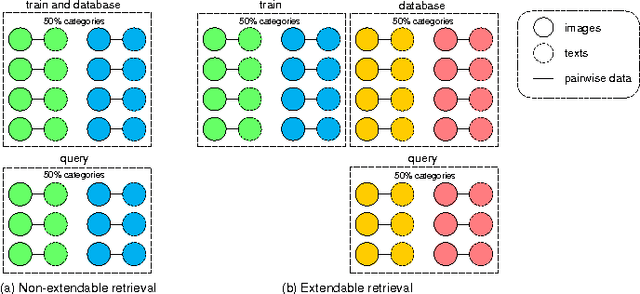


This paper proposes a new evaluation protocol for cross-media retrieval which better fits the real-word applications. Both image-text and text-image retrieval modes are considered. Traditionally, class labels in the training and testing sets are identical. That is, it is usually assumed that the query falls into some pre-defined classes. However, in practice, the content of a query image/text may vary extensively, and the retrieval system does not necessarily know in advance the class label of a query. Considering the inconsistency between the real-world applications and laboratory assumptions, we think that the existing protocol that works under identical train/test classes can be modified and improved. This work is dedicated to addressing this problem by considering the protocol under an extendable scenario, \ie, the training and testing classes do not overlap. We provide extensive benchmarking results obtained by the existing protocol and the proposed new protocol on several commonly used datasets. We demonstrate a noticeable performance drop when the testing classes are unseen during training. Additionally, a trivial solution, \ie, directly using the predicted class label for cross-media retrieval, is tested. We show that the trivial solution is very competitive in traditional non-extendable retrieval, but becomes less so under the new settings. The train/test split, evaluation code, and benchmarking results are publicly available on our website.