 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextQFormer: A New Context Modeling Method for Multi-Turn Multi-Modal Conversations
May 29, 2025Multi-modal large language models have demonstrated remarkable zero-shot abilities and powerful image-understanding capabilities. However, the existing open-source multi-modal models suffer from the weak capability of multi-turn interaction, especially for long contexts. To address the issue, we first introduce a context modeling module, termed ContextQFormer, which utilizes a memory block to enhance the presentation of contextual information. Furthermore, to facilitate further research, we carefully build a new multi-turn multi-modal dialogue dataset (TMDialog) for pre-training, instruction-tuning, and evaluation, which will be open-sourced lately. Compared with other multi-modal dialogue datasets, TMDialog contains longer conversations, which supports the research of multi-turn multi-modal dialogue. In addition, ContextQFormer is compared with three baselines on TMDialog and experimental results illustrate that ContextQFormer achieves an improvement of 2%-4% in available rate over baselines.
GODBench: A Benchmark for Multimodal Large Language Models in Video Comment Art
May 16, 2025Video Comment Art enhances user engagement by providing creative content that conveys humor, satire, or emotional resonance, requiring a nuanced and comprehensive grasp of cultural and contextual subtleties. Although Multimodal Large Language Models (MLLMs) and Chain-of-Thought (CoT) have demonstrated strong reasoning abilities in STEM tasks (e.g. mathematics and coding), they still struggle to generate creative expressions such as resonant jokes and insightful satire. Moreover, existing benchmarks are constrained by their limited modalities and insufficient categories, hindering the exploration of comprehensive creativity in video-based Comment Art creation. To address these limitations, we introduce GODBench, a novel benchmark that integrates video and text modalities to systematically evaluate MLLMs' abilities to compose Comment Art. Furthermore, inspired by the propagation patterns of waves in physics, we propose Ripple of Thought (RoT), a multi-step reasoning framework designed to enhance the creativity of MLLMs. Extensive experiments reveal that existing MLLMs and CoT methods still face significant challenges in understanding and generating creative video comments. In contrast, RoT provides an effective approach to improve creative composing, highlighting its potential to drive meaningful advancements in MLLM-based creativity. GODBench is publicly available at https://github.com/stan-lei/GODBench-ACL2025.
SeriesBench: A Benchmark for Narrative-Driven Drama Series Understanding
Apr 30, 2025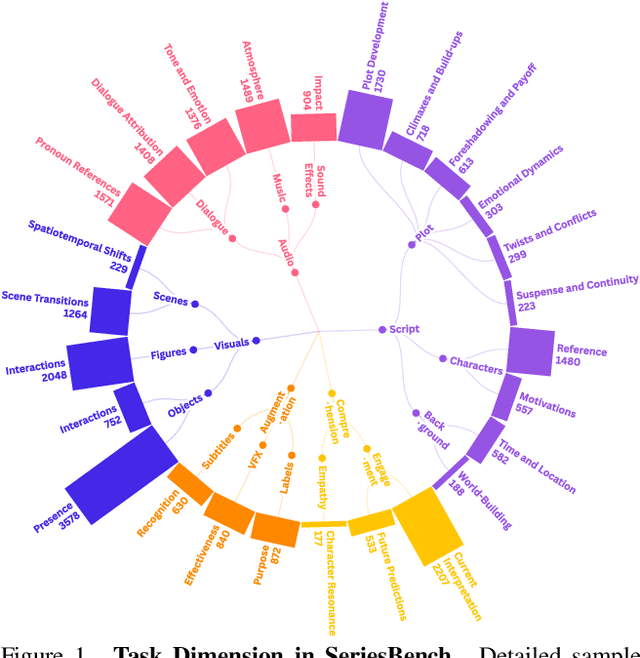

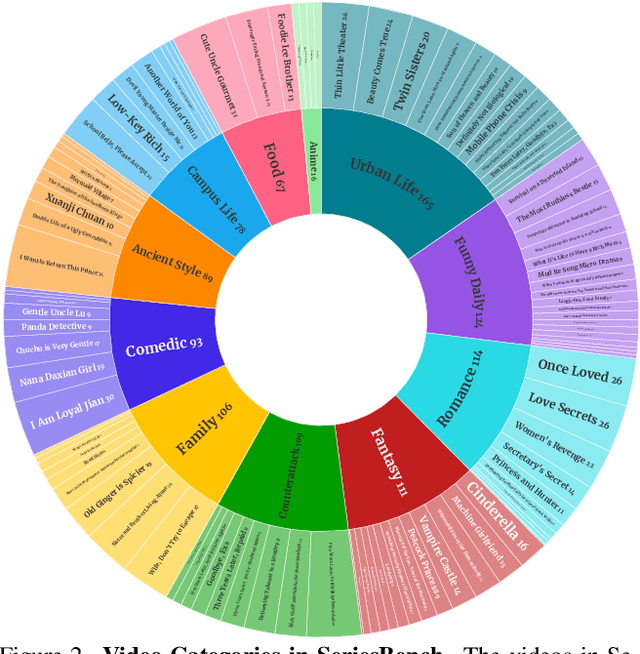
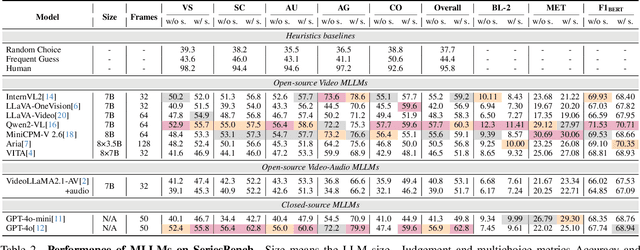
With the rapid development of Multi-modal Large Language Models (MLLMs), an increasing number of benchmarks have been established to evaluate the video understanding capabilities of these models. However, these benchmarks focus on \textbf{standalone} videos and mainly assess ``visual elements'' like human actions and object states. In reality, contemporary videos often encompass complex and continuous narratives, typically presented as a \textbf{series}. To address this challenge, we propose \textbf{SeriesBench}, a benchmark consisting of 105 carefully curated narrative-driven series, covering 28 specialized tasks that require deep narrative understanding. Specifically, we first select a diverse set of drama series spanning various genres. Then, we introduce a novel long-span narrative annotation method, combined with a full-information transformation approach to convert manual annotations into diverse task formats. To further enhance model capacity for detailed analysis of plot structures and character relationships within series, we propose a novel narrative reasoning framework, \textbf{PC-DCoT}. Extensive results on \textbf{SeriesBench} indicate that existing MLLMs still face significant challenges in understanding narrative-driven series, while \textbf{PC-DCoT} enables these MLLMs to achieve performance improvements. Overall, our \textbf{SeriesBench} and \textbf{PC-DCoT} highlight the critical necessity of advancing model capabilities to understand narrative-driven series, guiding the future development of MLLMs. SeriesBench is publicly available at https://github.com/zackhxn/SeriesBench-CVPR2025.
KwaiChat: A Large-Scale Video-Driven Multilingual Mixed-Type Dialogue Corpus
Mar 10, 2025Video-based dialogue systems, such as education assistants, have compelling application value, thereby garnering growing interest. However, the current video-based dialogue systems are limited by their reliance on a single dialogue type, which hinders their versatility in practical applications across a range of scenarios, including question-answering, emotional dialog, etc. In this paper, we identify this challenge as how to generate video-driven multilingual mixed-type dialogues. To mitigate this challenge, we propose a novel task and create a human-to-human video-driven multilingual mixed-type dialogue corpus, termed KwaiChat, containing a total of 93,209 videos and 246,080 dialogues, across 4 dialogue types, 30 domains, 4 languages, and 13 topics. Additionally, we establish baseline models on KwaiChat. An extensive analysis of 7 distinct LLMs on KwaiChat reveals that GPT-4o achieves the best performance but still cannot perform well in this situation even with the help of in-context learning and fine-tuning, which indicates that the task is not trivial and needs further research.
MidMed: Towards Mixed-Type Dialogues for Medical Consultation
Jun 14, 2023



Most medical dialogue systems assume that patients have clear goals (medicine querying, surgical operation querying, etc.) before medical consultation. However, in many real scenarios, due to the lack of medical knowledge, it is usually difficult for patients to determine clear goals with all necessary slots. In this paper, we identify this challenge as how to construct medical consultation dialogue systems to help patients clarify their goals. To mitigate this challenge, we propose a novel task and create a human-to-human mixed-type medical consultation dialogue corpus, termed MidMed, covering five dialogue types: task-oriented dialogue for diagnosis, recommendation, knowledge-grounded dialogue, QA, and chitchat. MidMed covers four departments (otorhinolaryngology, ophthalmology, skin, and digestive system), with 8,175 dialogues. Furthermore, we build baselines on MidMed and propose an instruction-guiding medical dialogue generation framework, termed InsMed, to address this task. Experimental results show the effectiveness of InsMed.