 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSheet as Token: A Graph-Enhanced Representation for Multi-Sheet Spreadsheet Understanding
May 07, 2026Workbook-scale spreadsheet understanding is increasingly important for language-model-based data analysis agents, but remains challenging because relevant information is often distributed across multiple sheets with heterogeneous schemas, layouts, and implicit relationships. Existing retrieval-augmented approaches typically decompose spreadsheets into rows, columns, or blocks to improve scalability; however, such chunk-centric representations can fragment worksheets into isolated text spans and weaken global sheet-level semantics. We propose Sheet as Token, a graph-enhanced framework that treats each worksheet as a unified semantic unit for multi-sheet spreadsheet retrieval. Our method extracts schema-aware records from sheet names, column headers, representative values, and layout features, and encodes each worksheet into a compact dense token. Given a natural-language query, a Graph Retriever constructs a query-specific candidate graph over sheet tokens using semantic, query-conditioned, schema-consistency, and shape-compatibility relations, and composes these channels through a multi-stage graph transformer to retrieve supporting sheet sets. Experiments on a constructed multi-sheet spreadsheet corpus show that sheet-level tokenization learns stable representations, and that graph-enhanced cross-sheet reasoning improves listwise retrieval over a shallow graph baseline with limited additional graph-side computation. These results suggest that sheet-level tokenization is a promising abstraction for scalable multi-sheet spreadsheet understanding.
A Multi-Scale Graph Learning Framework with Temporal Consistency Constraints for Financial Fraud Detection in Transaction Networks under Non-Stationary Conditions
Mar 15, 2026Financial fraud detection in transaction networks involves modeling sparse anomalies, dynamic patterns, and severe class imbalance in the presence of temporal drift in the data. In real-world transaction systems, a suspicious transaction is rarely isolated: rather, legitimate and suspicious transactions are often connected through accounts, intermediaries or through temporal transaction sequences. Attribute-based or randomly partitioned learning pipelines are therefore insufficient to detect relationally structured fraud. STC-MixHop, a graph-based framework combining spatial multi-resolution propagation with lightweight temporal consistency modeling for anomaly and fraud detection in dynamic transaction networks. It integrates three components: a MixHop-inspired multi-scale neighborhood diffusion encoder a multi-scale neighborhood diffusion MixHop-based encoder for learning structural patterns; a spatial-temporal attention module coupling current and preceding graph snapshots to stabilize representations; and a temporally informed self-supervised pretraining strategy exploiting unlabeled transaction interactions to improve representation quality. We evaluate the framework primarily on the PaySim dataset under strict chronological splits, supplementing the analysis with Porto Seguro and FEMA data to probe cross-domain component behavior. Results show that STC-MixHop is competitive among graph methods and achieves strong screening-oriented recall under highly imbalanced conditions. The experiments also reveal an important boundary condition: when node attributes are highly informative, tabular baselines remain difficult to outperform. Graph structure contributes most clearly where hidden relational dependencies are operationally important. These findings support a stability-focused view of graph learning for financial fraud detection.
PROTOCOL: Partial Optimal Transport-enhanced Contrastive Learning for Imbalanced Multi-view Clustering
Jun 14, 2025While contrastive multi-view clustering has achieved remarkable success, it implicitly assumes balanced class distribution. However, real-world multi-view data primarily exhibits class imbalance distribution. Consequently, existing methods suffer performance degradation due to their inability to perceive and model such imbalance. To address this challenge, we present the first systematic study of imbalanced multi-view clustering, focusing on two fundamental problems: i. perceiving class imbalance distribution, and ii. mitigating representation degradation of minority samples. We propose PROTOCOL, a novel PaRtial Optimal TranspOrt-enhanced COntrastive Learning framework for imbalanced multi-view clustering. First, for class imbalance perception, we map multi-view features into a consensus space and reformulate the imbalanced clustering as a partial optimal transport (POT) problem, augmented with progressive mass constraints and weighted KL divergence for class distributions. Second, we develop a POT-enhanced class-rebalanced contrastive learning at both feature and class levels, incorporating logit adjustment and class-sensitive learning to enhance minority sample representations. Extensive experiments demonstrate that PROTOCOL significantly improves clustering performance on imbalanced multi-view data, filling a critical research gap in this field.
ContextQFormer: A New Context Modeling Method for Multi-Turn Multi-Modal Conversations
May 29, 2025


Multi-modal large language models have demonstrated remarkable zero-shot abilities and powerful image-understanding capabilities. However, the existing open-source multi-modal models suffer from the weak capability of multi-turn interaction, especially for long contexts. To address the issue, we first introduce a context modeling module, termed ContextQFormer, which utilizes a memory block to enhance the presentation of contextual information. Furthermore, to facilitate further research, we carefully build a new multi-turn multi-modal dialogue dataset (TMDialog) for pre-training, instruction-tuning, and evaluation, which will be open-sourced lately. Compared with other multi-modal dialogue datasets, TMDialog contains longer conversations, which supports the research of multi-turn multi-modal dialogue. In addition, ContextQFormer is compared with three baselines on TMDialog and experimental results illustrate that ContextQFormer achieves an improvement of 2%-4% in available rate over baselines.
GODBench: A Benchmark for Multimodal Large Language Models in Video Comment Art
May 16, 2025Video Comment Art enhances user engagement by providing creative content that conveys humor, satire, or emotional resonance, requiring a nuanced and comprehensive grasp of cultural and contextual subtleties. Although Multimodal Large Language Models (MLLMs) and Chain-of-Thought (CoT) have demonstrated strong reasoning abilities in STEM tasks (e.g. mathematics and coding), they still struggle to generate creative expressions such as resonant jokes and insightful satire. Moreover, existing benchmarks are constrained by their limited modalities and insufficient categories, hindering the exploration of comprehensive creativity in video-based Comment Art creation. To address these limitations, we introduce GODBench, a novel benchmark that integrates video and text modalities to systematically evaluate MLLMs' abilities to compose Comment Art. Furthermore, inspired by the propagation patterns of waves in physics, we propose Ripple of Thought (RoT), a multi-step reasoning framework designed to enhance the creativity of MLLMs. Extensive experiments reveal that existing MLLMs and CoT methods still face significant challenges in understanding and generating creative video comments. In contrast, RoT provides an effective approach to improve creative composing, highlighting its potential to drive meaningful advancements in MLLM-based creativity. GODBench is publicly available at https://github.com/stan-lei/GODBench-ACL2025.
SeriesBench: A Benchmark for Narrative-Driven Drama Series Understanding
Apr 30, 2025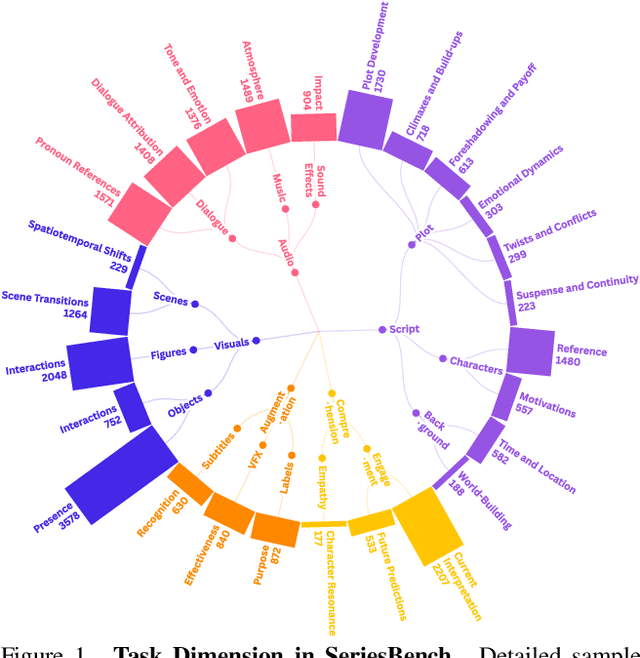

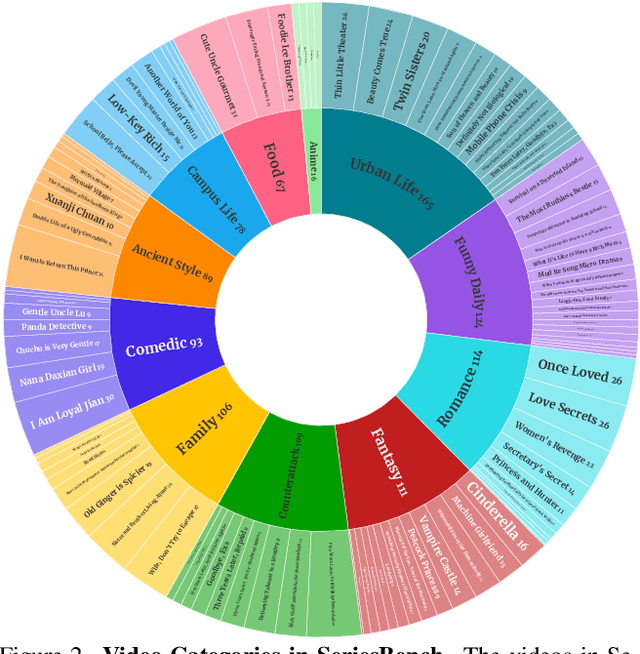
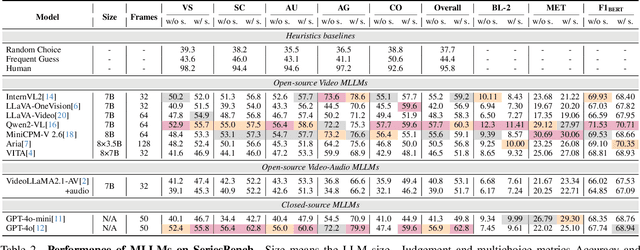
With the rapid development of Multi-modal Large Language Models (MLLMs), an increasing number of benchmarks have been established to evaluate the video understanding capabilities of these models. However, these benchmarks focus on \textbf{standalone} videos and mainly assess ``visual elements'' like human actions and object states. In reality, contemporary videos often encompass complex and continuous narratives, typically presented as a \textbf{series}. To address this challenge, we propose \textbf{SeriesBench}, a benchmark consisting of 105 carefully curated narrative-driven series, covering 28 specialized tasks that require deep narrative understanding. Specifically, we first select a diverse set of drama series spanning various genres. Then, we introduce a novel long-span narrative annotation method, combined with a full-information transformation approach to convert manual annotations into diverse task formats. To further enhance model capacity for detailed analysis of plot structures and character relationships within series, we propose a novel narrative reasoning framework, \textbf{PC-DCoT}. Extensive results on \textbf{SeriesBench} indicate that existing MLLMs still face significant challenges in understanding narrative-driven series, while \textbf{PC-DCoT} enables these MLLMs to achieve performance improvements. Overall, our \textbf{SeriesBench} and \textbf{PC-DCoT} highlight the critical necessity of advancing model capabilities to understand narrative-driven series, guiding the future development of MLLMs. SeriesBench is publicly available at https://github.com/zackhxn/SeriesBench-CVPR2025.
KwaiChat: A Large-Scale Video-Driven Multilingual Mixed-Type Dialogue Corpus
Mar 10, 2025Video-based dialogue systems, such as education assistants, have compelling application value, thereby garnering growing interest. However, the current video-based dialogue systems are limited by their reliance on a single dialogue type, which hinders their versatility in practical applications across a range of scenarios, including question-answering, emotional dialog, etc. In this paper, we identify this challenge as how to generate video-driven multilingual mixed-type dialogues. To mitigate this challenge, we propose a novel task and create a human-to-human video-driven multilingual mixed-type dialogue corpus, termed KwaiChat, containing a total of 93,209 videos and 246,080 dialogues, across 4 dialogue types, 30 domains, 4 languages, and 13 topics. Additionally, we establish baseline models on KwaiChat. An extensive analysis of 7 distinct LLMs on KwaiChat reveals that GPT-4o achieves the best performance but still cannot perform well in this situation even with the help of in-context learning and fine-tuning, which indicates that the task is not trivial and needs further research.
Deep Learning-Powered Classification of Thoracic Diseases in Chest X-Rays
Jan 24, 2025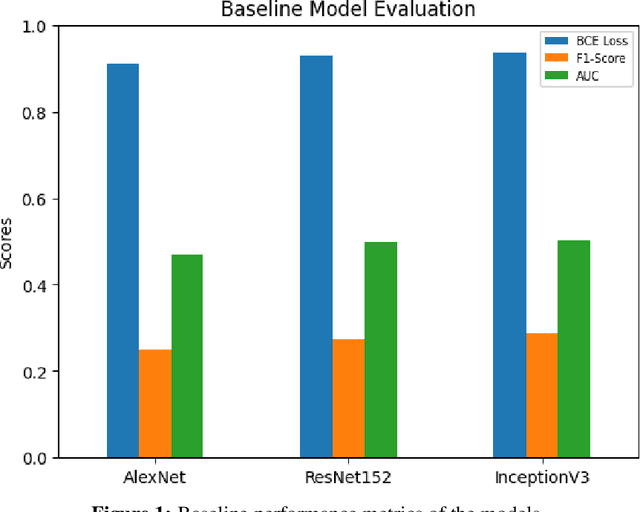
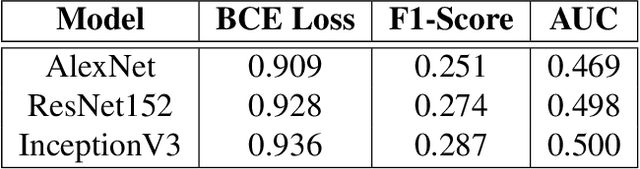
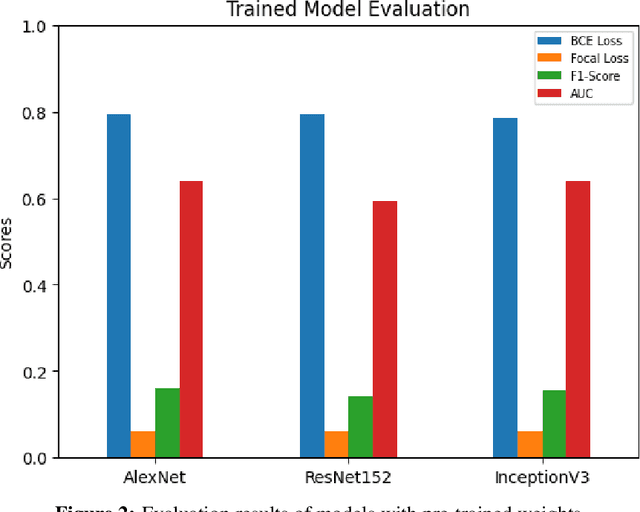
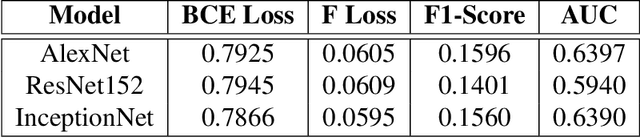
Chest X-rays play a pivotal role in diagnosing respiratory diseases such as pneumonia, tuberculosis, and COVID-19, which are prevalent and present unique diagnostic challenges due to overlapping visual features and variability in image quality. Severe class imbalance and the complexity of medical images hinder automated analysis. This study leverages deep learning techniques, including transfer learning on pre-trained models (AlexNet, ResNet, and InceptionNet), to enhance disease detection and classification. By fine-tuning these models and incorporating focal loss to address class imbalance, significant performance improvements were achieved. Grad-CAM visualizations further enhance model interpretability, providing insights into clinically relevant regions influencing predictions. The InceptionV3 model, for instance, achieved a 28% improvement in AUC and a 15% increase in F1-Score. These findings highlight the potential of deep learning to improve diagnostic workflows and support clinical decision-making.
Optimizing Mixture-of-Experts Inference Time Combining Model Deployment and Communication Scheduling
Oct 22, 2024



As machine learning models scale in size and complexity, their computational requirements become a significant barrier. Mixture-of-Experts (MoE) models alleviate this issue by selectively activating relevant experts. Despite this, MoE models are hindered by high communication overhead from all-to-all operations, low GPU utilization due to the synchronous communication constraint, and complications from heterogeneous GPU environments. This paper presents Aurora, which optimizes both model deployment and all-to-all communication scheduling to address these challenges in MoE inference. Aurora achieves minimal communication times by strategically ordering token transmissions in all-to-all communications. It improves GPU utilization by colocating experts from different models on the same device, avoiding the limitations of synchronous all-to-all communication. We analyze Aurora's optimization strategies theoretically across four common GPU cluster settings: exclusive vs. colocated models on GPUs, and homogeneous vs. heterogeneous GPUs. Aurora provides optimal solutions for three cases, and for the remaining NP-hard scenario, it offers a polynomial-time sub-optimal solution with only a 1.07x degradation from the optimal. Aurora is the first approach to minimize MoE inference time via optimal model deployment and communication scheduling across various scenarios. Evaluations demonstrate that Aurora significantly accelerates inference, achieving speedups of up to 2.38x in homogeneous clusters and 3.54x in heterogeneous environments. Moreover, Aurora enhances GPU utilization by up to 1.5x compared to existing methods.
HiDiff: Hybrid Diffusion Framework for Medical Image Segmentation
Jul 03, 2024

Medical image segmentation has been significantly advanced with the rapid development of deep learning (DL) techniques. Existing DL-based segmentation models are typically discriminative; i.e., they aim to learn a mapping from the input image to segmentation masks. However, these discriminative methods neglect the underlying data distribution and intrinsic class characteristics, suffering from unstable feature space. In this work, we propose to complement discriminative segmentation methods with the knowledge of underlying data distribution from generative models. To that end, we propose a novel hybrid diffusion framework for medical image segmentation, termed HiDiff, which can synergize the strengths of existing discriminative segmentation models and new generative diffusion models. HiDiff comprises two key components: discriminative segmentor and diffusion refiner. First, we utilize any conventional trained segmentation models as discriminative segmentor, which can provide a segmentation mask prior for diffusion refiner. Second, we propose a novel binary Bernoulli diffusion model (BBDM) as the diffusion refiner, which can effectively, efficiently, and interactively refine the segmentation mask by modeling the underlying data distribution. Third, we train the segmentor and BBDM in an alternate-collaborative manner to mutually boost each other. Extensive experimental results on abdomen organ, brain tumor, polyps, and retinal vessels segmentation datasets, covering four widely-used modalities, demonstrate the superior performance of HiDiff over existing medical segmentation algorithms, including the state-of-the-art transformer- and diffusion-based ones. In addition, HiDiff excels at segmenting small objects and generalizing to new datasets. Source codes are made available at https://github.com/takimailto/HiDiff.