 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALPBench: A Benchmark for Attribution-level Long-term Personal Behavior Understanding
Feb 03, 2026Recent advances in large language models have highlighted their potential for personalized recommendation, where accurately capturing user preferences remains a key challenge. Leveraging their strong reasoning and generalization capabilities, LLMs offer new opportunities for modeling long-term user behavior. To systematically evaluate this, we introduce ALPBench, a Benchmark for Attribution-level Long-term Personal Behavior Understanding. Unlike item-focused benchmarks, ALPBench predicts user-interested attribute combinations, enabling ground-truth evaluation even for newly introduced items. It models preferences from long-term historical behaviors rather than users' explicitly expressed requests, better reflecting enduring interests. User histories are represented as natural language sequences, allowing interpretable, reasoning-based personalization. ALPBench enables fine-grained evaluation of personalization by focusing on the prediction of attribute combinations task that remains highly challenging for current LLMs due to the need to capture complex interactions among multiple attributes and reason over long-term user behavior sequences.
KwaiChat: A Large-Scale Video-Driven Multilingual Mixed-Type Dialogue Corpus
Mar 10, 2025Video-based dialogue systems, such as education assistants, have compelling application value, thereby garnering growing interest. However, the current video-based dialogue systems are limited by their reliance on a single dialogue type, which hinders their versatility in practical applications across a range of scenarios, including question-answering, emotional dialog, etc. In this paper, we identify this challenge as how to generate video-driven multilingual mixed-type dialogues. To mitigate this challenge, we propose a novel task and create a human-to-human video-driven multilingual mixed-type dialogue corpus, termed KwaiChat, containing a total of 93,209 videos and 246,080 dialogues, across 4 dialogue types, 30 domains, 4 languages, and 13 topics. Additionally, we establish baseline models on KwaiChat. An extensive analysis of 7 distinct LLMs on KwaiChat reveals that GPT-4o achieves the best performance but still cannot perform well in this situation even with the help of in-context learning and fine-tuning, which indicates that the task is not trivial and needs further research.
EVLM: An Efficient Vision-Language Model for Visual Understanding
Jul 19, 2024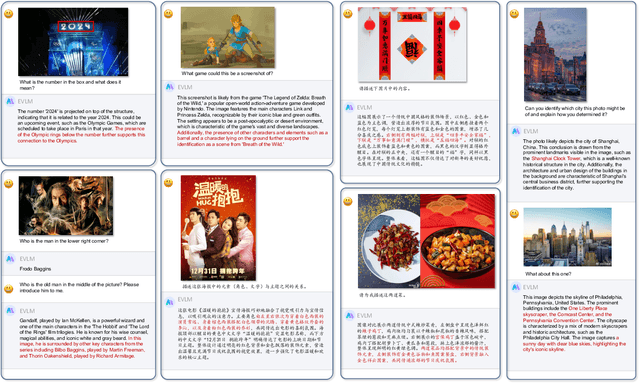
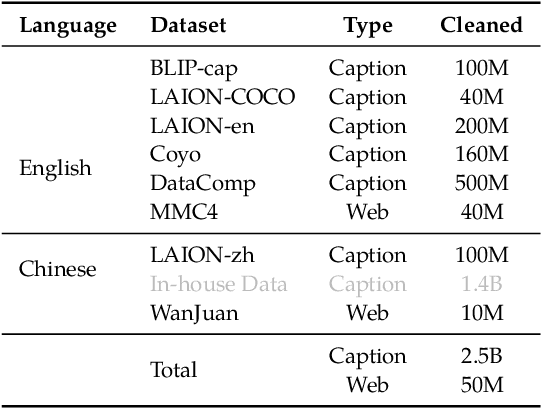
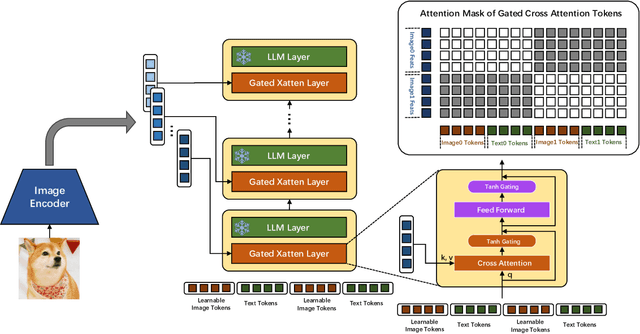

In the field of multi-modal language models, the majority of methods are built on an architecture similar to LLaVA. These models use a single-layer ViT feature as a visual prompt, directly feeding it into the language models alongside textual tokens. However, when dealing with long sequences of visual signals or inputs such as videos, the self-attention mechanism of language models can lead to significant computational overhead. Additionally, using single-layer ViT features makes it challenging for large language models to perceive visual signals fully. This paper proposes an efficient multi-modal language model to minimize computational costs while enabling the model to perceive visual signals as comprehensively as possible. Our method primarily includes: (1) employing cross-attention to image-text interaction similar to Flamingo. (2) utilize hierarchical ViT features. (3) introduce the Mixture of Experts (MoE) mechanism to enhance model effectiveness. Our model achieves competitive scores on public multi-modal benchmarks and performs well in tasks such as image captioning and video captioning.
Solving Token Gradient Conflict in Mixture-of-Experts for Large Vision-Language Model
Jun 28, 2024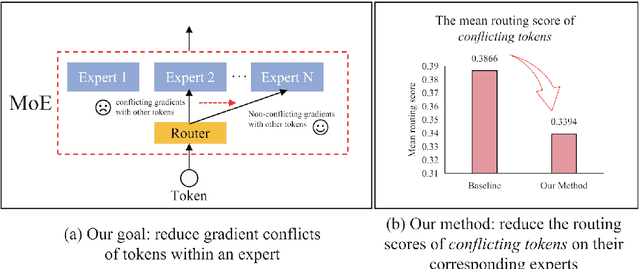
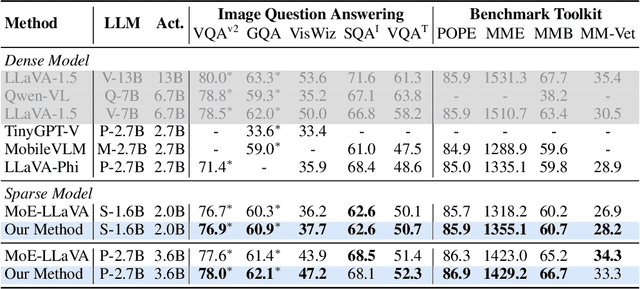
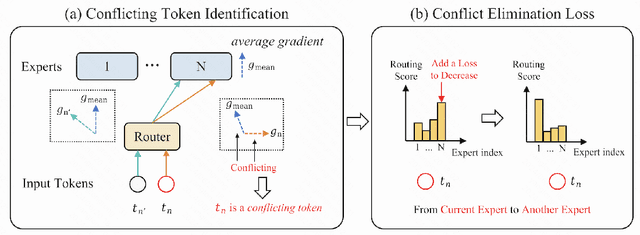
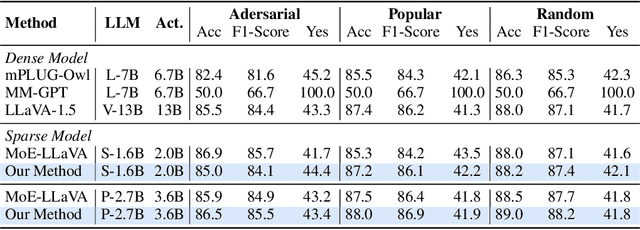
The Mixture-of-Experts (MoE) has gained increasing attention in the study of Large Vision-Language Models (LVLMs). It uses a sparse model to replace the dense model, achieving comparable performance while activating fewer parameters during inference, thus significantly reducing the inference cost. Existing MoE methods in LVLMs encourage different experts to handle different tokens, and thus they employ a router to predict the routing for each token. However, the predictions are based solely on sample features and do not truly reveal the optimization direction of tokens. This can lead to severe optimization conflicts between different tokens within an expert. To address this problem, this paper proposes a novel method based on token-level gradient analysis. Specifically, we first use token-level gradients to identify conflicting tokens in experts. Then, we add a specialized loss tailored to eliminate conflicts among tokens within each expert. Our method can serve as a plug-in for diverse Large Vision-Language Models, and extensive experimental results demonstrate the effectiveness of our method. The code will be publicly available at https://github.com/longrongyang/STGC.
A Unified Model for Video Understanding and Knowledge Embedding with Heterogeneous Knowledge Graph Dataset
Nov 19, 2022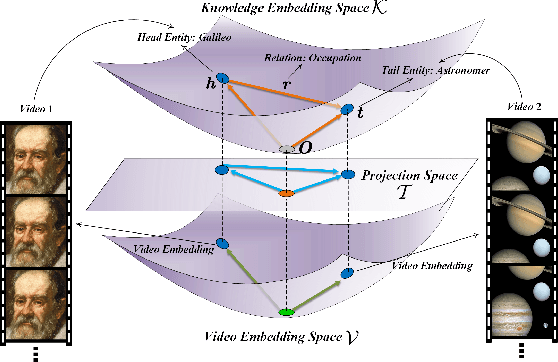
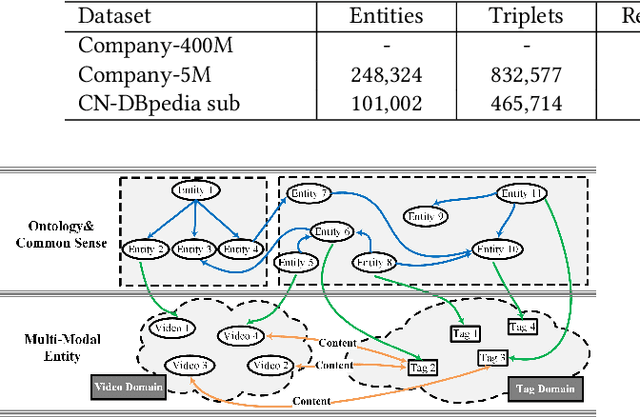
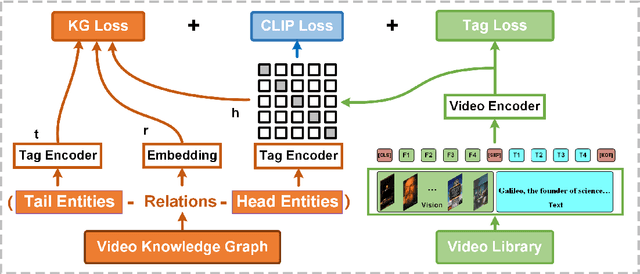

Video understanding is an important task in short video business platforms and it has a wide application in video recommendation and classification. Most of the existing video understanding works only focus on the information that appeared within the video content, including the video frames, audio and text. However, introducing common sense knowledge from the external Knowledge Graph (KG) dataset is essential for video understanding when referring to the content which is less relevant to the video. Owing to the lack of video knowledge graph dataset, the work which integrates video understanding and KG is rare. In this paper, we propose a heterogeneous dataset that contains the multi-modal video entity and fruitful common sense relations. This dataset also provides multiple novel video inference tasks like the Video-Relation-Tag (VRT) and Video-Relation-Video (VRV) tasks. Furthermore, based on this dataset, we propose an end-to-end model that jointly optimizes the video understanding objective with knowledge graph embedding, which can not only better inject factual knowledge into video understanding but also generate effective multi-modal entity embedding for KG. Comprehensive experiments indicate that combining video understanding embedding with factual knowledge benefits the content-based video retrieval performance. Moreover, it also helps the model generate better knowledge graph embedding which outperforms traditional KGE-based methods on VRT and VRV tasks with at least 42.36% and 17.73% improvement in HITS@10.
Real-time End-to-End Video Text Spotter with Contrastive Representation Learning
Jul 18, 2022



Video text spotting(VTS) is the task that requires simultaneously detecting, tracking and recognizing text in the video. Existing video text spotting methods typically develop sophisticated pipelines and multiple models, which is not friend for real-time applications. Here we propose a real-time end-to-end video text spotter with Contrastive Representation learning (CoText). Our contributions are three-fold: 1) CoText simultaneously address the three tasks (e.g., text detection, tracking, recognition) in a real-time end-to-end trainable framework. 2) With contrastive learning, CoText models long-range dependencies and learning temporal information across multiple frames. 3) A simple, lightweight architecture is designed for effective and accurate performance, including GPU-parallel detection post-processing, CTC-based recognition head with Masked RoI. Extensive experiments show the superiority of our method. Especially, CoText achieves an video text spotting IDF1 of 72.0% at 41.0 FPS on ICDAR2015video, with 10.5% and 32.0 FPS improvement the previous best method. The code can be found at github.com/weijiawu/CoText.
Contrastive Learning of Semantic and Visual Representations for Text Tracking
Dec 30, 2021



Semantic representation is of great benefit to the video text tracking(VTT) task that requires simultaneously classifying, detecting, and tracking texts in the video. Most existing approaches tackle this task by appearance similarity in continuous frames, while ignoring the abundant semantic features. In this paper, we explore to robustly track video text with contrastive learning of semantic and visual representations. Correspondingly, we present an end-to-end video text tracker with Semantic and Visual Representations(SVRep), which detects and tracks texts by exploiting the visual and semantic relationships between different texts in a video sequence. Besides, with a light-weight architecture, SVRep achieves state-of-the-art performance while maintaining competitive inference speed. Specifically, with a backbone of ResNet-18, SVRep achieves an ${\rm ID_{F1}}$ of $\textbf{65.9\%}$, running at $\textbf{16.7}$ FPS, on the ICDAR2015(video) dataset with $\textbf{8.6\%}$ improvement than the previous state-of-the-art methods.
Consistency Regularization for Deep Face Anti-Spoofing
Nov 25, 2021



Face anti-spoofing (FAS) plays a crucial role in securing face recognition systems. Empirically, given an image, a model with more consistent output on different views of this image usually performs better, as shown in Fig.1. Motivated by this exciting observation, we conjecture that encouraging feature consistency of different views may be a promising way to boost FAS models. In this paper, we explore this way thoroughly by enhancing both Embedding-level and Prediction-level Consistency Regularization (EPCR) in FAS. Specifically, at the embedding-level, we design a dense similarity loss to maximize the similarities between all positions of two intermediate feature maps in a self-supervised fashion; while at the prediction-level, we optimize the mean square error between the predictions of two views. Notably, our EPCR is free of annotations and can directly integrate into semi-supervised learning schemes. Considering different application scenarios, we further design five diverse semi-supervised protocols to measure semi-supervised FAS techniques. We conduct extensive experiments to show that EPCR can significantly improve the performance of several supervised and semi-supervised tasks on benchmark datasets. The codes and protocols will be released at https://github.com/clks-wzz/EPCR.