 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Cocoa Pollinators: A Deep Learning Dataset
Dec 27, 2024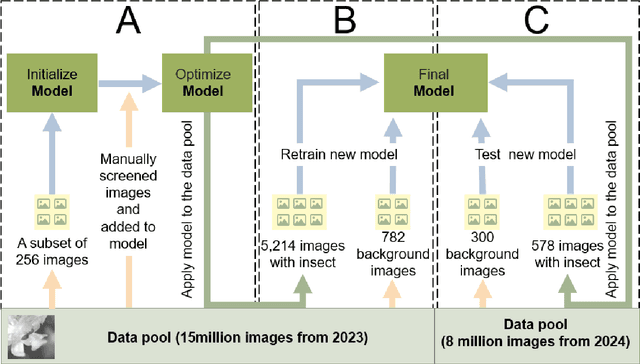
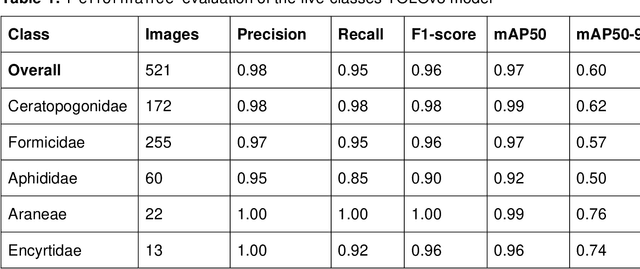

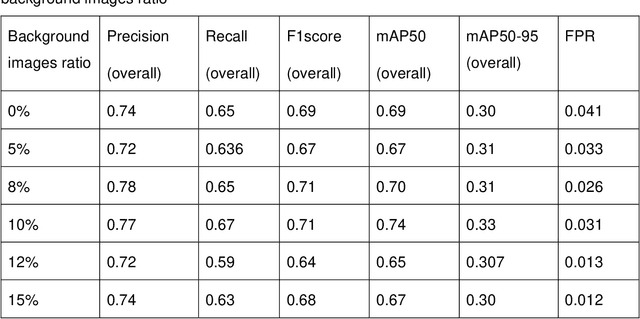
Cocoa is a multi-billion-dollar industry but research on improving yields through pollination remains limited. New embedded hardware and AI-based data analysis is advancing information on cocoa flower visitors, their identity and implications for yields. We present the first cocoa flower visitor dataset containing 5,792 images of Ceratopogonidae, Formicidae, Aphididae, Araneae, and Encyrtidae, and 1,082 background cocoa flower images. This dataset was curated from 23 million images collected over two years by embedded cameras in cocoa plantations in Hainan province, China. We exemplify the use of the dataset with different sizes of YOLOv8 models and by progressively increasing the background image ratio in the training set to identify the best-performing model. The medium-sized YOLOv8 model achieved the best results with 8% background images (F1 Score of 0.71, mAP50 of 0.70). Overall, this dataset is useful to compare the performance of deep learning model architectures on images with low contrast images and difficult detection targets. The data can support future efforts to advance sustainable cocoa production through pollination monitoring projects.
Solving Token Gradient Conflict in Mixture-of-Experts for Large Vision-Language Model
Jun 28, 2024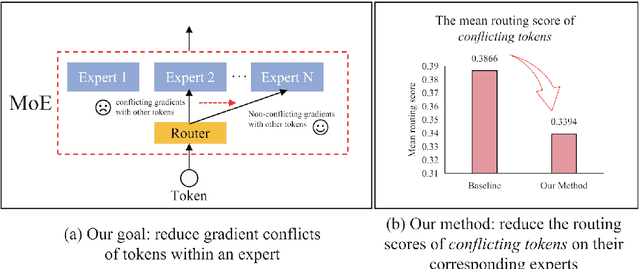
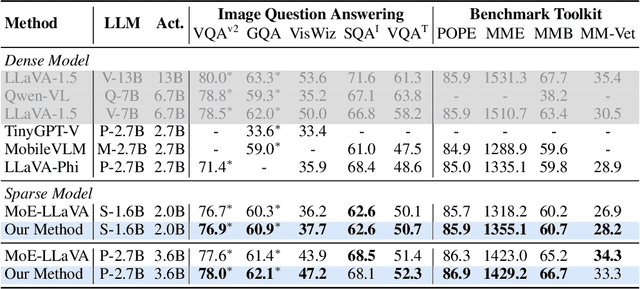
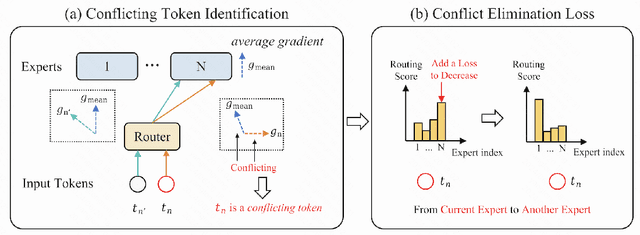
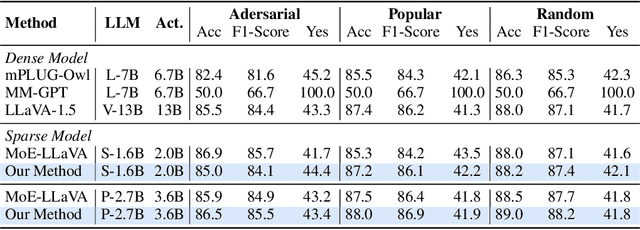
The Mixture-of-Experts (MoE) has gained increasing attention in the study of Large Vision-Language Models (LVLMs). It uses a sparse model to replace the dense model, achieving comparable performance while activating fewer parameters during inference, thus significantly reducing the inference cost. Existing MoE methods in LVLMs encourage different experts to handle different tokens, and thus they employ a router to predict the routing for each token. However, the predictions are based solely on sample features and do not truly reveal the optimization direction of tokens. This can lead to severe optimization conflicts between different tokens within an expert. To address this problem, this paper proposes a novel method based on token-level gradient analysis. Specifically, we first use token-level gradients to identify conflicting tokens in experts. Then, we add a specialized loss tailored to eliminate conflicts among tokens within each expert. Our method can serve as a plug-in for diverse Large Vision-Language Models, and extensive experimental results demonstrate the effectiveness of our method. The code will be publicly available at https://github.com/longrongyang/STGC.