 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCM-Eval: An Expert-Level Dynamic and Extensible Benchmark for Traditional Chinese Medicine
Nov 10, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in modern medicine, yet their application in Traditional Chinese Medicine (TCM) remains severely limited by the absence of standardized benchmarks and the scarcity of high-quality training data. To address these challenges, we introduce TCM-Eval, the first dynamic and extensible benchmark for TCM, meticulously curated from national medical licensing examinations and validated by TCM experts. Furthermore, we construct a large-scale training corpus and propose Self-Iterative Chain-of-Thought Enhancement (SI-CoTE) to autonomously enrich question-answer pairs with validated reasoning chains through rejection sampling, establishing a virtuous cycle of data and model co-evolution. Using this enriched training data, we develop ZhiMingTang (ZMT), a state-of-the-art LLM specifically designed for TCM, which significantly exceeds the passing threshold for human practitioners. To encourage future research and development, we release a public leaderboard, fostering community engagement and continuous improvement.
GUIDE: A Guideline-Guided Dataset for Instructional Video Comprehension
Jun 26, 2024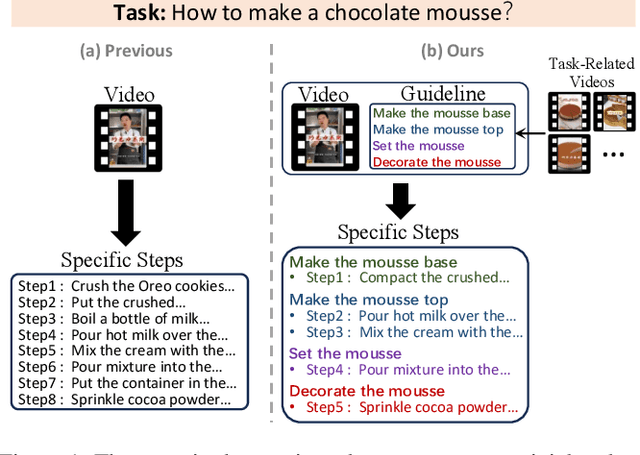

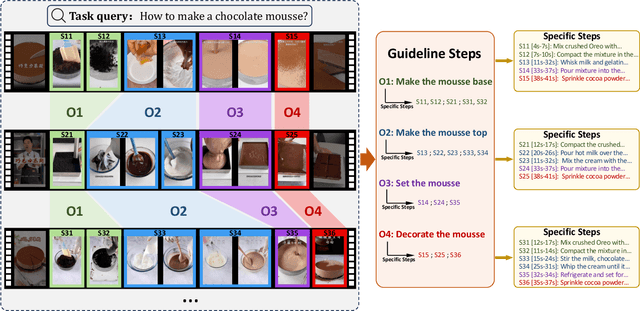

There are substantial instructional videos on the Internet, which provide us tutorials for completing various tasks. Existing instructional video datasets only focus on specific steps at the video level, lacking experiential guidelines at the task level, which can lead to beginners struggling to learn new tasks due to the lack of relevant experience. Moreover, the specific steps without guidelines are trivial and unsystematic, making it difficult to provide a clear tutorial. To address these problems, we present the GUIDE (Guideline-Guided) dataset, which contains 3.5K videos of 560 instructional tasks in 8 domains related to our daily life. Specifically, we annotate each instructional task with a guideline, representing a common pattern shared by all task-related videos. On this basis, we annotate systematic specific steps, including their associated guideline steps, specific step descriptions and timestamps. Our proposed benchmark consists of three sub-tasks to evaluate comprehension ability of models: (1) Step Captioning: models have to generate captions for specific steps from videos. (2) Guideline Summarization: models have to mine the common pattern in task-related videos and summarize a guideline from them. (3) Guideline-Guided Captioning: models have to generate captions for specific steps under the guide of guideline. We evaluate plenty of foundation models with GUIDE and perform in-depth analysis. Given the diversity and practicality of GUIDE, we believe that it can be used as a better benchmark for instructional video comprehension.
KwaiAgents: Generalized Information-seeking Agent System with Large Language Models
Dec 08, 2023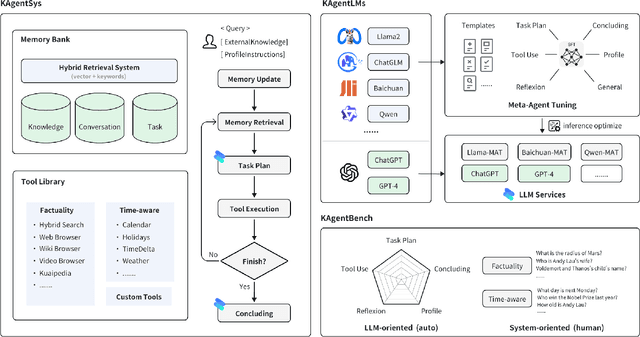

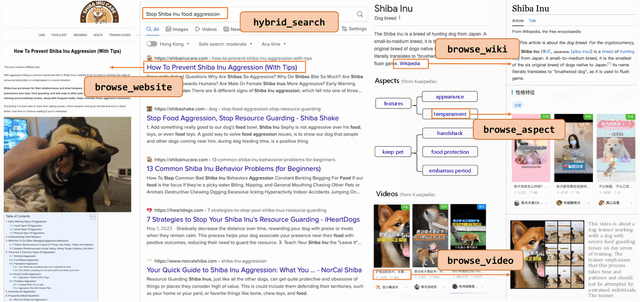

Driven by curiosity, humans have continually sought to explore and understand the world around them, leading to the invention of various tools to satiate this inquisitiveness. Despite not having the capacity to process and memorize vast amounts of information in their brains, humans excel in critical thinking, planning, reflection, and harnessing available tools to interact with and interpret the world, enabling them to find answers efficiently. The recent advancements in large language models (LLMs) suggest that machines might also possess the aforementioned human-like capabilities, allowing them to exhibit powerful abilities even with a constrained parameter count. In this paper, we introduce KwaiAgents, a generalized information-seeking agent system based on LLMs. Within KwaiAgents, we propose an agent system that employs LLMs as its cognitive core, which is capable of understanding a user's query, behavior guidelines, and referencing external documents. The agent can also update and retrieve information from its internal memory, plan and execute actions using a time-aware search-browse toolkit, and ultimately provide a comprehensive response. We further investigate the system's performance when powered by LLMs less advanced than GPT-4, and introduce the Meta-Agent Tuning (MAT) framework, designed to ensure even an open-sourced 7B or 13B model performs well among many agent systems. We exploit both benchmark and human evaluations to systematically validate these capabilities. Extensive experiments show the superiority of our agent system compared to other autonomous agents and highlight the enhanced generalized agent-abilities of our fine-tuned LLMs.
A Unified Model for Video Understanding and Knowledge Embedding with Heterogeneous Knowledge Graph Dataset
Nov 19, 2022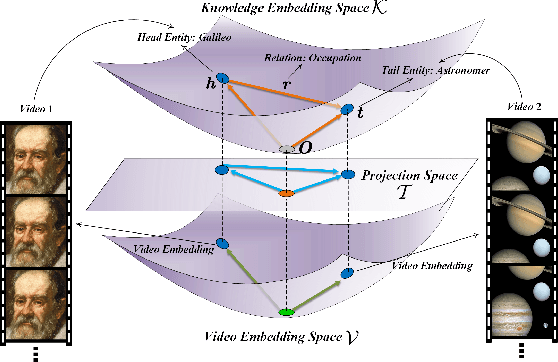
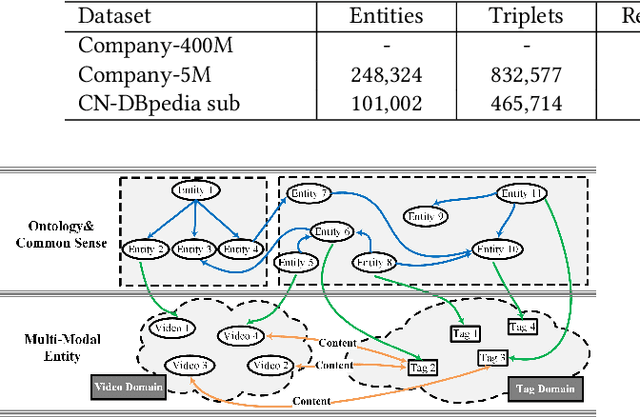
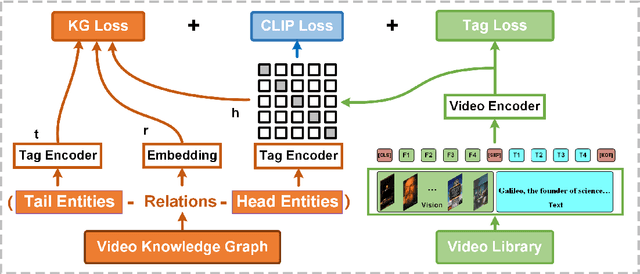

Video understanding is an important task in short video business platforms and it has a wide application in video recommendation and classification. Most of the existing video understanding works only focus on the information that appeared within the video content, including the video frames, audio and text. However, introducing common sense knowledge from the external Knowledge Graph (KG) dataset is essential for video understanding when referring to the content which is less relevant to the video. Owing to the lack of video knowledge graph dataset, the work which integrates video understanding and KG is rare. In this paper, we propose a heterogeneous dataset that contains the multi-modal video entity and fruitful common sense relations. This dataset also provides multiple novel video inference tasks like the Video-Relation-Tag (VRT) and Video-Relation-Video (VRV) tasks. Furthermore, based on this dataset, we propose an end-to-end model that jointly optimizes the video understanding objective with knowledge graph embedding, which can not only better inject factual knowledge into video understanding but also generate effective multi-modal entity embedding for KG. Comprehensive experiments indicate that combining video understanding embedding with factual knowledge benefits the content-based video retrieval performance. Moreover, it also helps the model generate better knowledge graph embedding which outperforms traditional KGE-based methods on VRT and VRV tasks with at least 42.36% and 17.73% improvement in HITS@10.
BigCilin: An Automatic Chinese Open-domain Knowledge Graph with Fine-grained Hypernym-Hyponym Relations
Nov 07, 2022


This paper presents BigCilin, the first Chinese open-domain knowledge graph with fine-grained hypernym-hyponym re-lations which are extracted automatically from multiple sources for Chinese named entities. With the fine-grained hypernym-hyponym relations, BigCilin owns flexible semantic hierarchical structure. Since the hypernym-hyponym paths are automati-cally generated and one entity may have several senses, we provide a path disambi-guation solution to map a hypernym-hyponym path of one entity to its one sense on the condition that the path and the sense express the same meaning. In order to conveniently access our BigCilin Knowle-dge graph, we provide web interface in two ways. One is that it supports querying any Chinese named entity and browsing the extracted hypernym-hyponym paths surro-unding the query entity. The other is that it gives a top-down browsing view to illust-rate the overall hierarchical structure of our BigCilin knowledge graph over some sam-pled entities.
Kuaipedia: a Large-scale Multi-modal Short-video Encyclopedia
Nov 03, 2022Online encyclopedias, such as Wikipedia, have been well-developed and researched in the last two decades. One can find any attributes or other information of a wiki item on a wiki page edited by a community of volunteers. However, the traditional text, images and tables can hardly express some aspects of an wiki item. For example, when we talk about ``Shiba Inu'', one may care more about ``How to feed it'' or ``How to train it not to protect its food''. Currently, short-video platforms have become a hallmark in the online world. Whether you're on TikTok, Instagram, Kuaishou, or YouTube Shorts, short-video apps have changed how we consume and create content today. Except for producing short videos for entertainment, we can find more and more authors sharing insightful knowledge widely across all walks of life. These short videos, which we call knowledge videos, can easily express any aspects (e.g. hair or how-to-feed) consumers want to know about an item (e.g. Shiba Inu), and they can be systematically analyzed and organized like an online encyclopedia. In this paper, we propose Kuaipedia, a large-scale multi-modal encyclopedia consisting of items, aspects, and short videos lined to them, which was extracted from billions of videos of Kuaishou (Kwai), a well-known short-video platform in China. We first collected items from multiple sources and mined user-centered aspects from millions of users' queries to build an item-aspect tree. Then we propose a new task called ``multi-modal item-aspect linking'' as an expansion of ``entity linking'' to link short videos into item-aspect pairs and build the whole short-video encyclopedia. Intrinsic evaluations show that our encyclopedia is of large scale and highly accurate. We also conduct sufficient extrinsic experiments to show how Kuaipedia can help fundamental applications such as entity typing and entity linking.