 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Model for Video Understanding and Knowledge Embedding with Heterogeneous Knowledge Graph Dataset
Paper and Code
Nov 19, 2022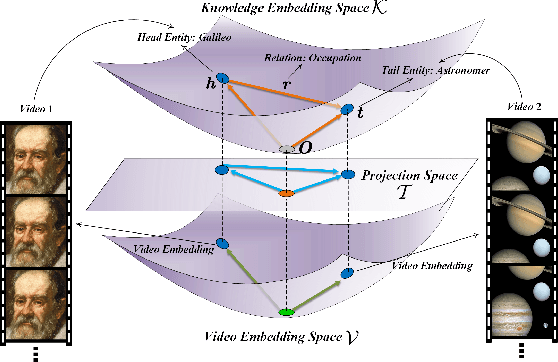
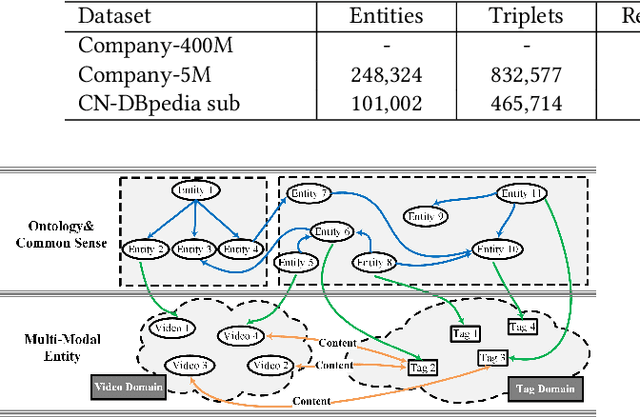
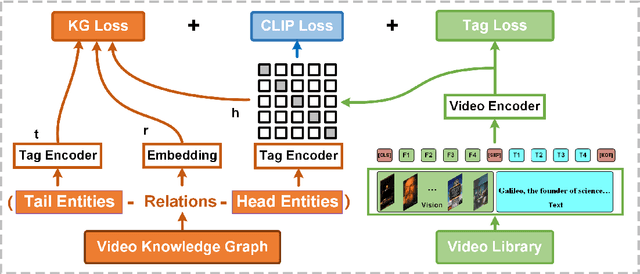

Video understanding is an important task in short video business platforms and it has a wide application in video recommendation and classification. Most of the existing video understanding works only focus on the information that appeared within the video content, including the video frames, audio and text. However, introducing common sense knowledge from the external Knowledge Graph (KG) dataset is essential for video understanding when referring to the content which is less relevant to the video. Owing to the lack of video knowledge graph dataset, the work which integrates video understanding and KG is rare. In this paper, we propose a heterogeneous dataset that contains the multi-modal video entity and fruitful common sense relations. This dataset also provides multiple novel video inference tasks like the Video-Relation-Tag (VRT) and Video-Relation-Video (VRV) tasks. Furthermore, based on this dataset, we propose an end-to-end model that jointly optimizes the video understanding objective with knowledge graph embedding, which can not only better inject factual knowledge into video understanding but also generate effective multi-modal entity embedding for KG. Comprehensive experiments indicate that combining video understanding embedding with factual knowledge benefits the content-based video retrieval performance. Moreover, it also helps the model generate better knowledge graph embedding which outperforms traditional KGE-based methods on VRT and VRV tasks with at least 42.36% and 17.73% improvement in HITS@10.