 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHO-Flow: Generalizable Hand-Object Interaction Generation with Latent Flow Matching
Apr 12, 2026Generating realistic 3D hand-object interactions (HOI) is a fundamental challenge in computer vision and robotics, requiring both temporal coherence and high-fidelity physical plausibility. Existing methods remain limited in their ability to learn expressive motion representations for generation and perform temporal reasoning. In this paper, we present HO-Flow, a framework for synthesizing realistic hand-object motion sequences from texts and canoncial 3D objects. HO-Flow first employs an interaction-aware variational autoencoder to encode sequences of hand and object motions into a unified latent manifold by incorporating hand and object kinematics, enabling the representation to capture rich interaction dynamics. It then leverages a masked flow matching model that combines auto-regressive temporal reasoning with continuous latent generation, improving temporal coherence. To further enhance generalization, HO-Flow predicts object motions relative to the initial frame, enabling effective pre-training on large-scale synthetic data. Experiments on the GRAB, OakInk, and DexYCB benchmarks demonstrate that HO-Flow achieves state-of-the-art performance in both physical plausibility and motion diversity for interaction motion synthesis.
Beyond the Flat Sequence: Hierarchical and Preference-Aware Generative Recommendations
Mar 01, 2026Generative Recommenders (GRs), exemplified by the Hierarchical Sequential Transduction Unit (HSTU), have emerged as a powerful paradigm for modeling long user interaction sequences. However, we observe that their "flat-sequence" assumption overlooks the rich, intrinsic structure of user behavior. This leads to two key limitations: a failure to capture the temporal hierarchy of session-based engagement, and computational inefficiency, as dense attention introduces significant noise that obscures true preference signals within semantically sparse histories, which deteriorates the quality of the learned representations. To this end, we propose a novel framework named HPGR (Hierarchical and Preference-aware Generative Recommender), built upon a two-stage paradigm that injects these crucial structural priors into the model to handle the drawback. Specifically, HPGR comprises two synergistic stages. First, a structure-aware pre-training stage employs a session-based Masked Item Modeling (MIM) objective to learn a hierarchically-informed and semantically rich item representation space. Second, a preference-aware fine-tuning stage leverages these powerful representations to implement a Preference-Guided Sparse Attention mechanism, which dynamically constrains computation to only the most relevant historical items, enhancing both efficiency and signal-to-noise ratio. Empirical experiments on a large-scale proprietary industrial dataset from APPGallery and an online A/B test verify that HPGR achieves state-of-the-art performance over multiple strong baselines, including HSTU and MTGR.
* Accepted to the ACM Web Conference 2026 (WWW '26). 9 pages, 9 figures. Zerui Chen and Heng Chang contributed equally to this work
SafeRBench: A Comprehensive Benchmark for Safety Assessment in Large Reasoning Models
Nov 19, 2025Large Reasoning Models (LRMs) improve answer quality through explicit chain-of-thought, yet this very capability introduces new safety risks: harmful content can be subtly injected, surface gradually, or be justified by misleading rationales within the reasoning trace. Existing safety evaluations, however, primarily focus on output-level judgments and rarely capture these dynamic risks along the reasoning process. In this paper, we present SafeRBench, the first benchmark that assesses LRM safety end-to-end -- from inputs and intermediate reasoning to final outputs. (1) Input Characterization: We pioneer the incorporation of risk categories and levels into input design, explicitly accounting for affected groups and severity, and thereby establish a balanced prompt suite reflecting diverse harm gradients. (2) Fine-Grained Output Analysis: We introduce a micro-thought chunking mechanism to segment long reasoning traces into semantically coherent units, enabling fine-grained evaluation across ten safety dimensions. (3) Human Safety Alignment: We validate LLM-based evaluations against human annotations specifically designed to capture safety judgments. Evaluations on 19 LRMs demonstrate that SafeRBench enables detailed, multidimensional safety assessment, offering insights into risks and protective mechanisms from multiple perspectives.
Probing Latent Knowledge Conflict for Faithful Retrieval-Augmented Generation
Oct 14, 2025Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm to enhance the factuality of Large Language Models (LLMs). However, existing RAG systems often suffer from an unfaithfulness issue, where the model's response contradicts evidence from the retrieved context. Existing approaches to improving contextual faithfulness largely rely on external interventions, such as prompt engineering, decoding constraints, or reward-based fine-tuning. These works treat the LLM as a black box and overlook a crucial question: how does the LLM internally integrate retrieved evidence with its parametric memory, particularly under knowledge conflicts? To address this gap, we conduct a probing-based analysis of hidden-state representations in LLMs and observe three findings: knowledge integration occurs hierarchically, conflicts manifest as latent signals at the sentence level, and irrelevant context is often amplified when aligned with parametric knowledge. Building on these findings, we propose CLEAR (Conflict-Localized and Enhanced Attention for RAG), a framework that (i) decomposes context into fine-grained sentence-level knowledge, (ii) employs hidden-state probing to localize conflicting knowledge, and (iii) introduces conflict-aware fine-tuning to guide the model to accurately integrate retrieved evidence. Extensive experiments across three benchmarks demonstrate that CLEAR substantially improves both accuracy and contextual faithfulness, consistently outperforming strong baselines under diverse conflict conditions. The related resources are available at https://github.com/LinfengGao/CLEAR.
HORT: Monocular Hand-held Objects Reconstruction with Transformers
Mar 27, 2025



Reconstructing hand-held objects in 3D from monocular images remains a significant challenge in computer vision. Most existing approaches rely on implicit 3D representations, which produce overly smooth reconstructions and are time-consuming to generate explicit 3D shapes. While more recent methods directly reconstruct point clouds with diffusion models, the multi-step denoising makes high-resolution reconstruction inefficient. To address these limitations, we propose a transformer-based model to efficiently reconstruct dense 3D point clouds of hand-held objects. Our method follows a coarse-to-fine strategy, first generating a sparse point cloud from the image and progressively refining it into a dense representation using pixel-aligned image features. To enhance reconstruction accuracy, we integrate image features with 3D hand geometry to jointly predict the object point cloud and its pose relative to the hand. Our model is trained end-to-end for optimal performance. Experimental results on both synthetic and real datasets demonstrate that our method achieves state-of-the-art accuracy with much faster inference speed, while generalizing well to in-the-wild images.
Simulation-Free Hierarchical Latent Policy Planning for Proactive Dialogues
Dec 19, 2024



Recent advancements in proactive dialogues have garnered significant attention, particularly for more complex objectives (e.g. emotion support and persuasion). Unlike traditional task-oriented dialogues, proactive dialogues demand advanced policy planning and adaptability, requiring rich scenarios and comprehensive policy repositories to develop such systems. However, existing approaches tend to rely on Large Language Models (LLMs) for user simulation and online learning, leading to biases that diverge from realistic scenarios and result in suboptimal efficiency. Moreover, these methods depend on manually defined, context-independent, coarse-grained policies, which not only incur high expert costs but also raise concerns regarding their completeness. In our work, we highlight the potential for automatically discovering policies directly from raw, real-world dialogue records. To this end, we introduce a novel dialogue policy planning framework, LDPP. It fully automates the process from mining policies in dialogue records to learning policy planning. Specifically, we employ a variant of the Variational Autoencoder to discover fine-grained policies represented as latent vectors. After automatically annotating the data with these latent policy labels, we propose an Offline Hierarchical Reinforcement Learning (RL) algorithm in the latent space to develop effective policy planning capabilities. Our experiments demonstrate that LDPP outperforms existing methods on two proactive scenarios, even surpassing ChatGPT with only a 1.8-billion-parameter LLM.
GUIDE: A Guideline-Guided Dataset for Instructional Video Comprehension
Jun 26, 2024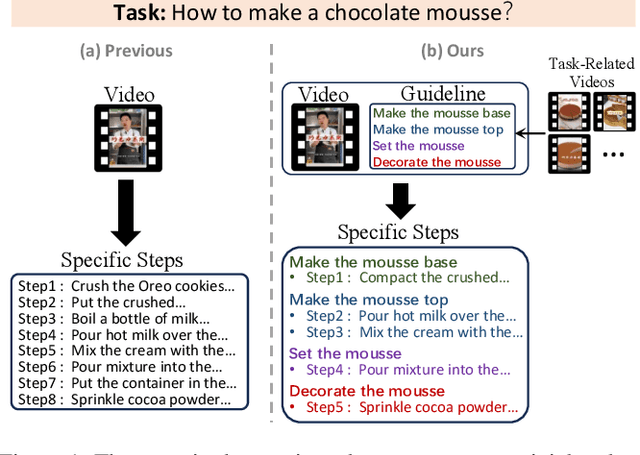

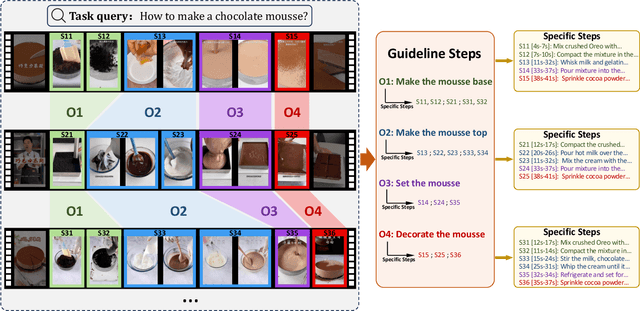

There are substantial instructional videos on the Internet, which provide us tutorials for completing various tasks. Existing instructional video datasets only focus on specific steps at the video level, lacking experiential guidelines at the task level, which can lead to beginners struggling to learn new tasks due to the lack of relevant experience. Moreover, the specific steps without guidelines are trivial and unsystematic, making it difficult to provide a clear tutorial. To address these problems, we present the GUIDE (Guideline-Guided) dataset, which contains 3.5K videos of 560 instructional tasks in 8 domains related to our daily life. Specifically, we annotate each instructional task with a guideline, representing a common pattern shared by all task-related videos. On this basis, we annotate systematic specific steps, including their associated guideline steps, specific step descriptions and timestamps. Our proposed benchmark consists of three sub-tasks to evaluate comprehension ability of models: (1) Step Captioning: models have to generate captions for specific steps from videos. (2) Guideline Summarization: models have to mine the common pattern in task-related videos and summarize a guideline from them. (3) Guideline-Guided Captioning: models have to generate captions for specific steps under the guide of guideline. We evaluate plenty of foundation models with GUIDE and perform in-depth analysis. Given the diversity and practicality of GUIDE, we believe that it can be used as a better benchmark for instructional video comprehension.
Planning Like Human: A Dual-process Framework for Dialogue Planning
Jun 08, 2024

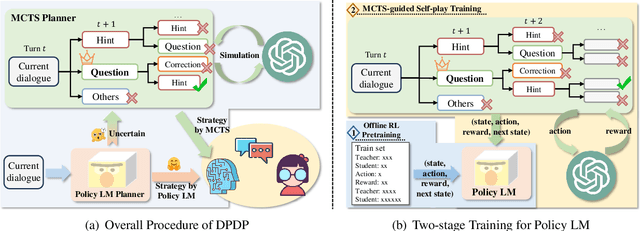

In proactive dialogue, the challenge lies not just in generating responses but in steering conversations toward predetermined goals, a task where Large Language Models (LLMs) typically struggle due to their reactive nature. Traditional approaches to enhance dialogue planning in LLMs, ranging from elaborate prompt engineering to the integration of policy networks, either face efficiency issues or deliver suboptimal performance. Inspired by the dualprocess theory in psychology, which identifies two distinct modes of thinking - intuitive (fast) and analytical (slow), we propose the Dual-Process Dialogue Planning (DPDP) framework. DPDP embodies this theory through two complementary planning systems: an instinctive policy model for familiar contexts and a deliberative Monte Carlo Tree Search (MCTS) mechanism for complex, novel scenarios. This dual strategy is further coupled with a novel two-stage training regimen: offline Reinforcement Learning for robust initial policy model formation followed by MCTS-enhanced on-the-fly learning, which ensures a dynamic balance between efficiency and strategic depth. Our empirical evaluations across diverse dialogue tasks affirm DPDP's superiority in achieving both high-quality dialogues and operational efficiency, outpacing existing methods.
ViViDex: Learning Vision-based Dexterous Manipulation from Human Videos
Apr 24, 2024



In this work, we aim to learn a unified vision-based policy for a multi-fingered robot hand to manipulate different objects in diverse poses. Though prior work has demonstrated that human videos can benefit policy learning, performance improvement has been limited by physically implausible trajectories extracted from videos. Moreover, reliance on privileged object information such as ground-truth object states further limits the applicability in realistic scenarios. To address these limitations, we propose a new framework ViViDex to improve vision-based policy learning from human videos. It first uses reinforcement learning with trajectory guided rewards to train state-based policies for each video, obtaining both visually natural and physically plausible trajectories from the video. We then rollout successful episodes from state-based policies and train a unified visual policy without using any privileged information. A coordinate transformation method is proposed to significantly boost the performance. We evaluate our method on three dexterous manipulation tasks and demonstrate a large improvement over state-of-the-art algorithms.
Learning Explicit Contact for Implicit Reconstruction of Hand-held Objects from Monocular Images
May 31, 2023Reconstructing hand-held objects from monocular RGB images is an appealing yet challenging task. In this task, contacts between hands and objects provide important cues for recovering the 3D geometry of the hand-held objects. Though recent works have employed implicit functions to achieve impressive progress, they ignore formulating contacts in their frameworks, which results in producing less realistic object meshes. In this work, we explore how to model contacts in an explicit way to benefit the implicit reconstruction of hand-held objects. Our method consists of two components: explicit contact prediction and implicit shape reconstruction. In the first part, we propose a new subtask of directly estimating 3D hand-object contacts from a single image. The part-level and vertex-level graph-based transformers are cascaded and jointly learned in a coarse-to-fine manner for more accurate contact probabilities. In the second part, we introduce a novel method to diffuse estimated contact states from the hand mesh surface to nearby 3D space and leverage diffused contact probabilities to construct the implicit neural representation for the manipulated object. Benefiting from estimating the interaction patterns between the hand and the object, our method can reconstruct more realistic object meshes, especially for object parts that are in contact with hands. Extensive experiments on challenging benchmarks show that the proposed method outperforms the current state of the arts by a great margin.