 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Agentic Intelligence for Materials Science
Jan 29, 2026The convergence of artificial intelligence and materials science presents a transformative opportunity, but achieving true acceleration in discovery requires moving beyond task-isolated, fine-tuned models toward agentic systems that plan, act, and learn across the full discovery loop. This survey advances a unique pipeline-centric view that spans from corpus curation and pretraining, through domain adaptation and instruction tuning, to goal-conditioned agents interfacing with simulation and experimental platforms. Unlike prior reviews, we treat the entire process as an end-to-end system to be optimized for tangible discovery outcomes rather than proxy benchmarks. This perspective allows us to trace how upstream design choices-such as data curation and training objectives-can be aligned with downstream experimental success through effective credit assignment. To bridge communities and establish a shared frame of reference, we first present an integrated lens that aligns terminology, evaluation, and workflow stages across AI and materials science. We then analyze the field through two focused lenses: From the AI perspective, the survey details LLM strengths in pattern recognition, predictive analytics, and natural language processing for literature mining, materials characterization, and property prediction; from the materials science perspective, it highlights applications in materials design, process optimization, and the acceleration of computational workflows via integration with external tools (e.g., DFT, robotic labs). Finally, we contrast passive, reactive approaches with agentic design, cataloging current contributions while motivating systems that pursue long-horizon goals with autonomy, memory, and tool use. This survey charts a practical roadmap towards autonomous, safety-aware LLM agents aimed at discovering novel and useful materials.
Video-BrowseComp: Benchmarking Agentic Video Research on Open Web
Dec 28, 2025The evolution of autonomous agents is redefining information seeking, transitioning from passive retrieval to proactive, open-ended web research. However, while textual and static multimodal agents have seen rapid progress, a significant modality gap remains in processing the web's most dynamic modality: video. Existing video benchmarks predominantly focus on passive perception, feeding curated clips to models without requiring external retrieval. They fail to evaluate agentic video research, which necessitates actively interrogating video timelines, cross-referencing dispersed evidence, and verifying claims against the open web. To bridge this gap, we present \textbf{Video-BrowseComp}, a challenging benchmark comprising 210 questions tailored for open-web agentic video reasoning. Unlike prior benchmarks, Video-BrowseComp enforces a mandatory dependency on temporal visual evidence, ensuring that answers cannot be derived solely through text search but require navigating video timelines to verify external claims. Our evaluation of state-of-the-art models reveals a critical bottleneck: even advanced search-augmented models like GPT-5.1 (w/ Search) achieve only 15.24\% accuracy. Our analysis reveals that these models largely rely on textual proxies, excelling in metadata-rich domains (e.g., TV shows with plot summaries) but collapsing in metadata-sparse, dynamic environments (e.g., sports, gameplay) where visual grounding is essential. As the first open-web video research benchmark, Video-BrowseComp advances the field beyond passive perception toward proactive video reasoning.
UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist
Nov 11, 2025While specialized AI models excel at isolated video tasks like generation or understanding, real-world applications demand complex, iterative workflows that combine these capabilities. To bridge this gap, we introduce UniVA, an open-source, omni-capable multi-agent framework for next-generation video generalists that unifies video understanding, segmentation, editing, and generation into cohesive workflows. UniVA employs a Plan-and-Act dual-agent architecture that drives a highly automated and proactive workflow: a planner agent interprets user intentions and decomposes them into structured video-processing steps, while executor agents execute these through modular, MCP-based tool servers (for analysis, generation, editing, tracking, etc.). Through a hierarchical multi-level memory (global knowledge, task context, and user-specific preferences), UniVA sustains long-horizon reasoning, contextual continuity, and inter-agent communication, enabling interactive and self-reflective video creation with full traceability. This design enables iterative and any-conditioned video workflows (e.g., text/image/video-conditioned generation $\rightarrow$ multi-round editing $\rightarrow$ object segmentation $\rightarrow$ compositional synthesis) that were previously cumbersome to achieve with single-purpose models or monolithic video-language models. We also introduce UniVA-Bench, a benchmark suite of multi-step video tasks spanning understanding, editing, segmentation, and generation, to rigorously evaluate such agentic video systems. Both UniVA and UniVA-Bench are fully open-sourced, aiming to catalyze research on interactive, agentic, and general-purpose video intelligence for the next generation of multimodal AI systems. (https://univa.online/)
Overconfidence in LLM-as-a-Judge: Diagnosis and Confidence-Driven Solution
Aug 08, 2025Large Language Models (LLMs) are widely used as automated judges, where practical value depends on both accuracy and trustworthy, risk-aware judgments. Existing approaches predominantly focus on accuracy, overlooking the necessity of well-calibrated confidence, which is vital for adaptive and reliable evaluation pipelines. In this work, we advocate a shift from accuracy-centric evaluation to confidence-driven, risk-aware LLM-as-a-Judge systems, emphasizing the necessity of well-calibrated confidence for trustworthy and adaptive evaluation. We systematically identify the **Overconfidence Phenomenon** in current LLM-as-a-Judges, where predicted confidence significantly overstates actual correctness, undermining reliability in practical deployment. To quantify this phenomenon, we introduce **TH-Score**, a novel metric measuring confidence-accuracy alignment. Furthermore, we propose **LLM-as-a-Fuser**, an ensemble framework that transforms LLMs into reliable, risk-aware evaluators. Extensive experiments demonstrate that our approach substantially improves calibration and enables adaptive, confidence-driven evaluation pipelines, achieving superior reliability and accuracy compared to existing baselines.
Simulating Before Planning: Constructing Intrinsic User World Model for User-Tailored Dialogue Policy Planning
Apr 18, 2025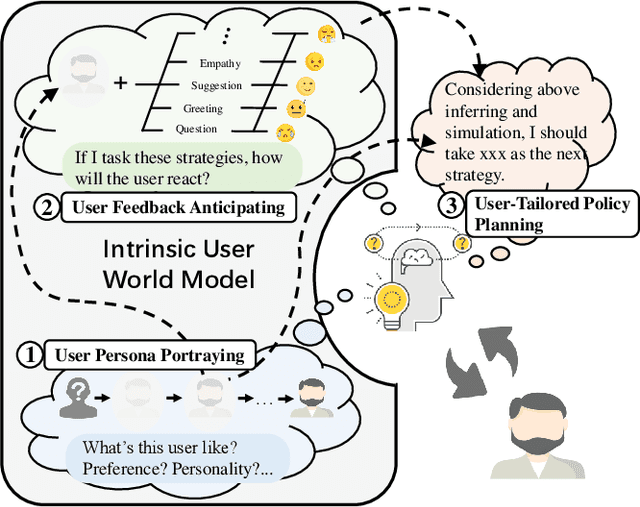
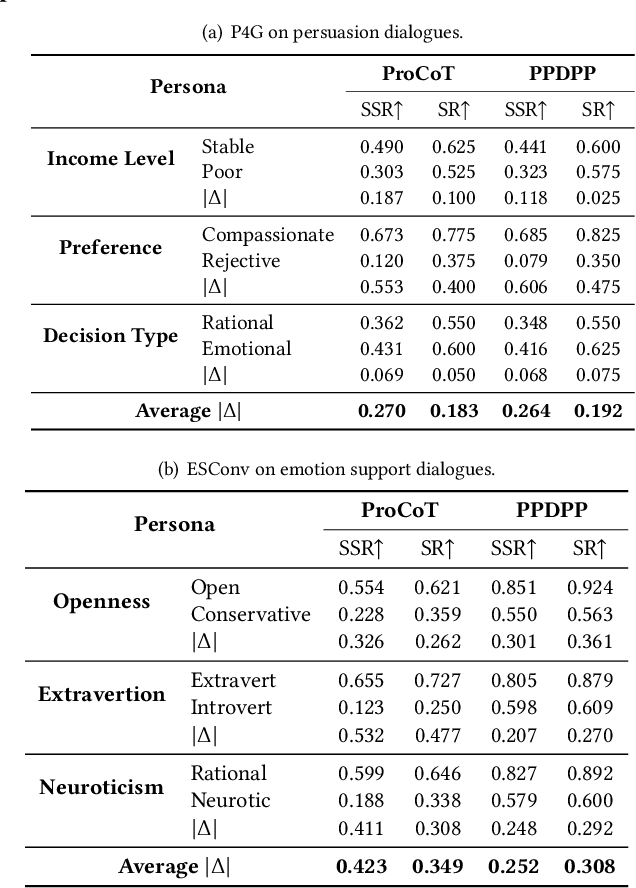
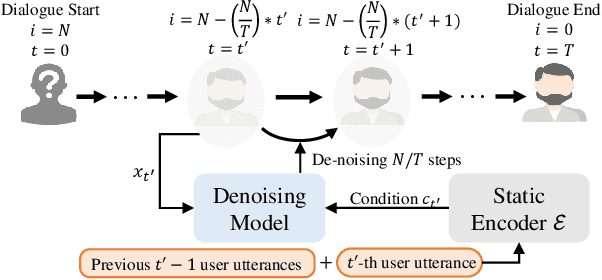
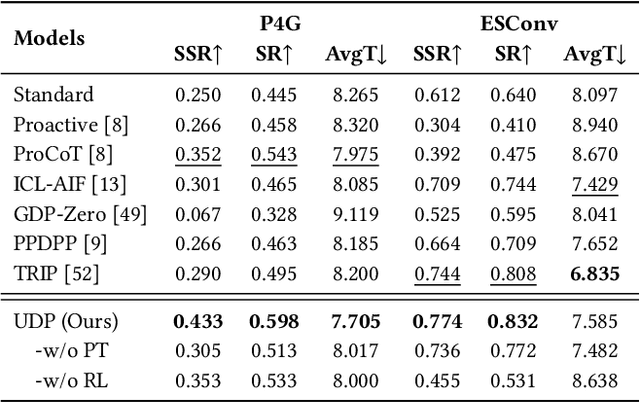
Recent advancements in dialogue policy planning have emphasized optimizing system agent policies to achieve predefined goals, focusing on strategy design, trajectory acquisition, and efficient training paradigms. However, these approaches often overlook the critical role of user characteristics, which are essential in real-world scenarios like conversational search and recommendation, where interactions must adapt to individual user traits such as personality, preferences, and goals. To address this gap, we first conduct a comprehensive study utilizing task-specific user personas to systematically assess dialogue policy planning under diverse user behaviors. By leveraging realistic user profiles for different tasks, our study reveals significant limitations in existing approaches, highlighting the need for user-tailored dialogue policy planning. Building on this foundation, we present the User-Tailored Dialogue Policy Planning (UDP) framework, which incorporates an Intrinsic User World Model to model user traits and feedback. UDP operates in three stages: (1) User Persona Portraying, using a diffusion model to dynamically infer user profiles; (2) User Feedback Anticipating, leveraging a Brownian Bridge-inspired anticipator to predict user reactions; and (3) User-Tailored Policy Planning, integrating these insights to optimize response strategies. To ensure robust performance, we further propose an active learning approach that prioritizes challenging user personas during training. Comprehensive experiments on benchmarks, including collaborative and non-collaborative settings, demonstrate the effectiveness of UDP in learning user-specific dialogue strategies. Results validate the protocol's utility and highlight UDP's robustness, adaptability, and potential to advance user-centric dialogue systems.
Simulation-Free Hierarchical Latent Policy Planning for Proactive Dialogues
Dec 19, 2024



Recent advancements in proactive dialogues have garnered significant attention, particularly for more complex objectives (e.g. emotion support and persuasion). Unlike traditional task-oriented dialogues, proactive dialogues demand advanced policy planning and adaptability, requiring rich scenarios and comprehensive policy repositories to develop such systems. However, existing approaches tend to rely on Large Language Models (LLMs) for user simulation and online learning, leading to biases that diverge from realistic scenarios and result in suboptimal efficiency. Moreover, these methods depend on manually defined, context-independent, coarse-grained policies, which not only incur high expert costs but also raise concerns regarding their completeness. In our work, we highlight the potential for automatically discovering policies directly from raw, real-world dialogue records. To this end, we introduce a novel dialogue policy planning framework, LDPP. It fully automates the process from mining policies in dialogue records to learning policy planning. Specifically, we employ a variant of the Variational Autoencoder to discover fine-grained policies represented as latent vectors. After automatically annotating the data with these latent policy labels, we propose an Offline Hierarchical Reinforcement Learning (RL) algorithm in the latent space to develop effective policy planning capabilities. Our experiments demonstrate that LDPP outperforms existing methods on two proactive scenarios, even surpassing ChatGPT with only a 1.8-billion-parameter LLM.
A Survey of Ontology Expansion for Conversational Understanding
Oct 19, 2024



In the rapidly evolving field of conversational AI, Ontology Expansion (OnExp) is crucial for enhancing the adaptability and robustness of conversational agents. Traditional models rely on static, predefined ontologies, limiting their ability to handle new and unforeseen user needs. This survey paper provides a comprehensive review of the state-of-the-art techniques in OnExp for conversational understanding. It categorizes the existing literature into three main areas: (1) New Intent Discovery, (2) New Slot-Value Discovery, and (3) Joint OnExp. By examining the methodologies, benchmarks, and challenges associated with these areas, we highlight several emerging frontiers in OnExp to improve agent performance in real-world scenarios and discuss their corresponding challenges. This survey aspires to be a foundational reference for researchers and practitioners, promoting further exploration and innovation in this crucial domain.
Grounding is All You Need? Dual Temporal Grounding for Video Dialog
Oct 08, 2024
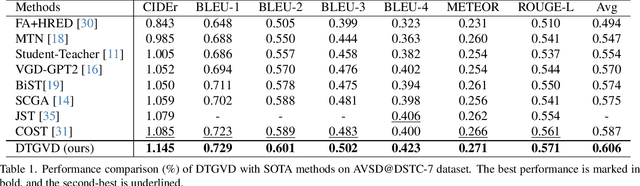
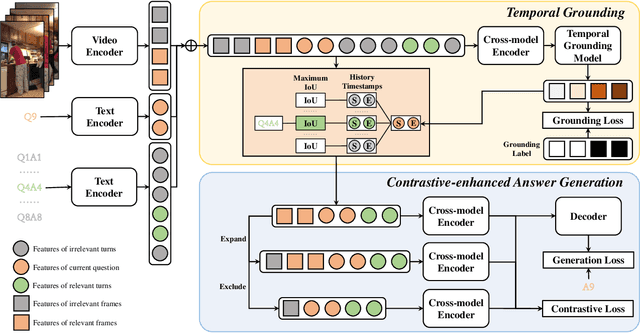

In the realm of video dialog response generation, the understanding of video content and the temporal nuances of conversation history are paramount. While a segment of current research leans heavily on large-scale pretrained visual-language models and often overlooks temporal dynamics, another delves deep into spatial-temporal relationships within videos but demands intricate object trajectory pre-extractions and sidelines dialog temporal dynamics. This paper introduces the Dual Temporal Grounding-enhanced Video Dialog model (DTGVD), strategically designed to merge the strengths of both dominant approaches. It emphasizes dual temporal relationships by predicting dialog turn-specific temporal regions, filtering video content accordingly, and grounding responses in both video and dialog contexts. One standout feature of DTGVD is its heightened attention to chronological interplay. By recognizing and acting upon the dependencies between different dialog turns, it captures more nuanced conversational dynamics. To further bolster the alignment between video and dialog temporal dynamics, we've implemented a list-wise contrastive learning strategy. Within this framework, accurately grounded turn-clip pairings are designated as positive samples, while less precise pairings are categorized as negative. This refined classification is then funneled into our holistic end-to-end response generation mechanism. Evaluations using AVSD@DSTC-7 and AVSD@DSTC-8 datasets underscore the superiority of our methodology.
PCQPR: Proactive Conversational Question Planning with Reflection
Oct 02, 2024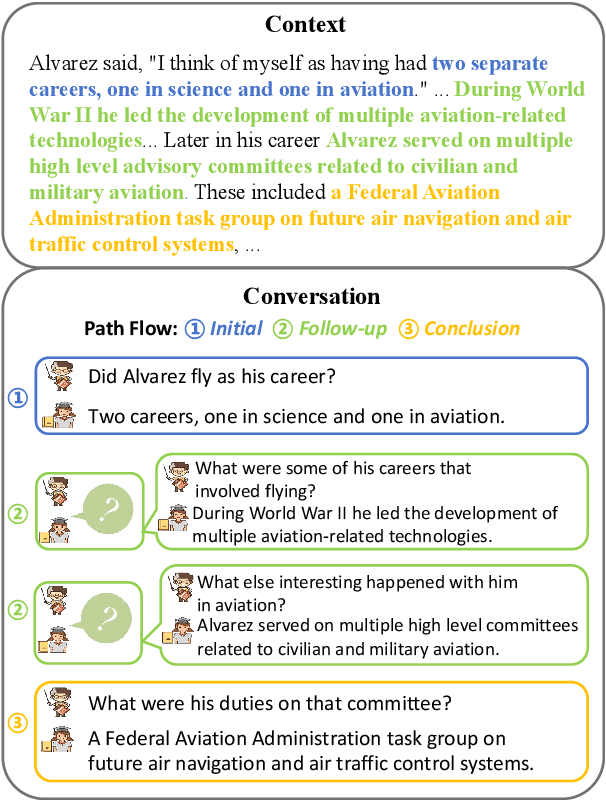
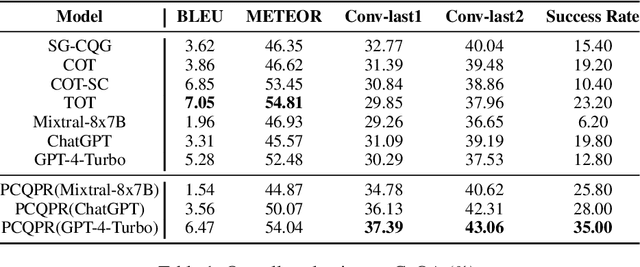
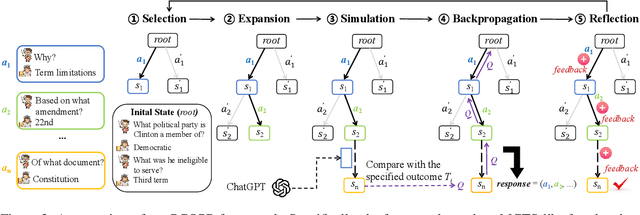
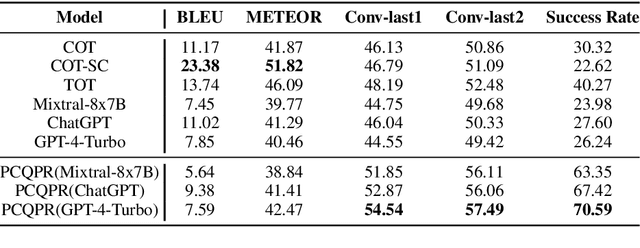
Conversational Question Generation (CQG) enhances the interactivity of conversational question-answering systems in fields such as education, customer service, and entertainment. However, traditional CQG, focusing primarily on the immediate context, lacks the conversational foresight necessary to guide conversations toward specified conclusions. This limitation significantly restricts their ability to achieve conclusion-oriented conversational outcomes. In this work, we redefine the CQG task as Conclusion-driven Conversational Question Generation (CCQG) by focusing on proactivity, not merely reacting to the unfolding conversation but actively steering it towards a conclusion-oriented question-answer pair. To address this, we propose a novel approach, called Proactive Conversational Question Planning with self-Refining (PCQPR). Concretely, by integrating a planning algorithm inspired by Monte Carlo Tree Search (MCTS) with the analytical capabilities of large language models (LLMs), PCQPR predicts future conversation turns and continuously refines its questioning strategies. This iterative self-refining mechanism ensures the generation of contextually relevant questions strategically devised to reach a specified outcome. Our extensive evaluations demonstrate that PCQPR significantly surpasses existing CQG methods, marking a paradigm shift towards conclusion-oriented conversational question-answering systems.
* Accepted by EMNLP 2024 Main
Retrieval Augmented Generation for Dynamic Graph Modeling
Aug 26, 2024



Dynamic graph modeling is crucial for analyzing evolving patterns in various applications. Existing approaches often integrate graph neural networks with temporal modules or redefine dynamic graph modeling as a generative sequence task. However, these methods typically rely on isolated historical contexts of the target nodes from a narrow perspective, neglecting occurrences of similar patterns or relevant cases associated with other nodes. In this work, we introduce the Retrieval-Augmented Generation for Dynamic Graph Modeling (RAG4DyG) framework, which leverages guidance from contextually and temporally analogous examples to broaden the perspective of each node. This approach presents two critical challenges: (1) How to identify and retrieve high-quality demonstrations that are contextually and temporally analogous to dynamic graph samples? (2) How can these demonstrations be effectively integrated to improve dynamic graph modeling? To address these challenges, we propose RAG4DyG, which enriches the understanding of historical contexts by retrieving and learning from contextually and temporally pertinent demonstrations. Specifically, we employ a time- and context-aware contrastive learning module to identify and retrieve relevant cases for each query sequence. Moreover, we design a graph fusion strategy to integrate the retrieved cases, thereby augmenting the inherent historical contexts for improved prediction. Extensive experiments on real-world datasets across different domains demonstrate the effectiveness of RAG4DyG for dynamic graph modeling.