 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Hierarchical Dialogue Policy Learning for Legal Inquisitive Conversational Agents
May 13, 2026Most existing dialogue systems are user-driven, primarily designed to fulfill user requests. However, in many critical real-world scenarios, a conversational agent must proactively extract information to achieve its own objectives rather than merely respond. To address this gap, we introduce \emph{Inquisitive Conversational Agents (ICAs)} and develop an ICA specifically tailored to U.S. Supreme Court oral arguments. We propose a Dual Hierarchical Reinforcement Learning framework featuring two cooperating RL agents, each with its own policy, to coordinate strategic dialogue management and fine-grained utterance generation. By learning when and how to ask probing questions, the agent emulates judicial questioning patterns and systematically uncovers crucial information to fulfill its legal objectives. Evaluations on a U.S. Supreme Court dataset show that our method outperforms various baselines across multiple metrics. It represents an important first step toward broader high-stakes, domain-specific applications.
YIELD: A Large-Scale Dataset and Evaluation Framework for Information Elicitation Agents
Apr 13, 2026Most conversational agents (CAs) are designed to satisfy user needs through user-driven interactions. However, many real-world settings, such as academic interviewing, judicial proceedings, and journalistic investigations, involve broader institutional decision-making processes and require agents that can elicit information from users. In this paper, we introduce Information Elicitation Agents (IEAs) in which the agent's goal is to elicit information from users to support the agent's institutional or task-oriented objectives. To enable systematic research on this setting, we present YIELD, a 26M-token dataset of 2,281 ethically sourced, human-to-human dialogues. Moreover, we formalize information elicitation as a finite-horizon POMDP and propose novel metrics tailored to IEAs. Pilot experiments on multiple foundation LLMs show that training on YIELD improves their alignment with real elicitation behavior and findings are corroborated by human evaluation. We release YIELD under CC BY 4.0. The dataset, project code, evaluation tools, and fine-tuned model adapters are available at: https://github.com/infosenselab/yield.
FrameRef: A Framing Dataset and Simulation Testbed for Modeling Bounded Rational Information Health
Feb 17, 2026Information ecosystems increasingly shape how people internalize exposure to adverse digital experiences, raising concerns about the long-term consequences for information health. In modern search and recommendation systems, ranking and personalization policies play a central role in shaping such exposure and its long-term effects on users. To study these effects in a controlled setting, we present FrameRef, a large-scale dataset of 1,073,740 systematically reframed claims across five framing dimensions: authoritative, consensus, emotional, prestige, and sensationalist, and propose a simulation-based framework for modeling sequential information exposure and reinforcement dynamics characteristic of ranking and recommendation systems. Within this framework, we construct framing-sensitive agent personas by fine-tuning language models with framing-conditioned loss attenuation, inducing targeted biases while preserving overall task competence. Using Monte Carlo trajectory sampling, we show that small, systematic shifts in acceptance and confidence can compound over time, producing substantial divergence in cumulative information health trajectories. Human evaluation further confirms that FrameRef's generated framings measurably affect human judgment. Together, our dataset and framework provide a foundation for systematic information health research through simulation, complementing and informing responsible human-centered research. We release FrameRef, code, documentation, human evaluation data, and persona adapter models at https://github.com/infosenselab/frameref.
Towards Human-centered Proactive Conversational Agents
Apr 19, 2024



Recent research on proactive conversational agents (PCAs) mainly focuses on improving the system's capabilities in anticipating and planning action sequences to accomplish tasks and achieve goals before users articulate their requests. This perspectives paper highlights the importance of moving towards building human-centered PCAs that emphasize human needs and expectations, and that considers ethical and social implications of these agents, rather than solely focusing on technological capabilities. The distinction between a proactive and a reactive system lies in the proactive system's initiative-taking nature. Without thoughtful design, proactive systems risk being perceived as intrusive by human users. We address the issue by establishing a new taxonomy concerning three key dimensions of human-centered PCAs, namely Intelligence, Adaptivity, and Civility. We discuss potential research opportunities and challenges based on this new taxonomy upon the five stages of PCA system construction. This perspectives paper lays a foundation for the emerging area of conversational information retrieval research and paves the way towards advancing human-centered proactive conversational systems.
SEINE: SEgment-based Indexing for NEural information retrieval
Nov 27, 2023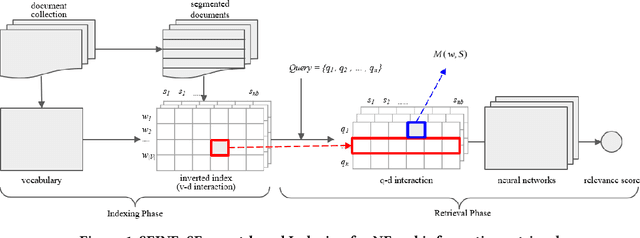
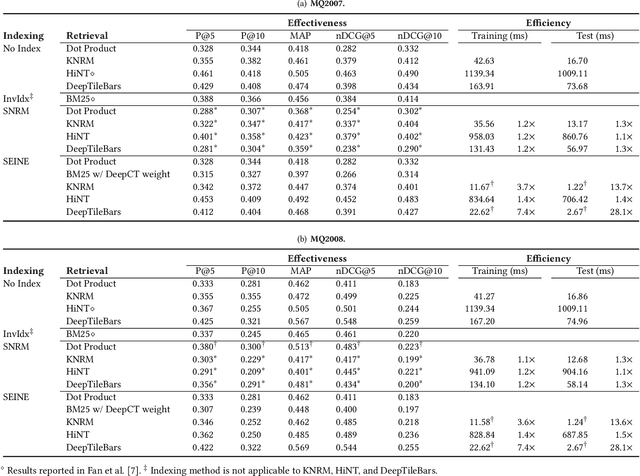
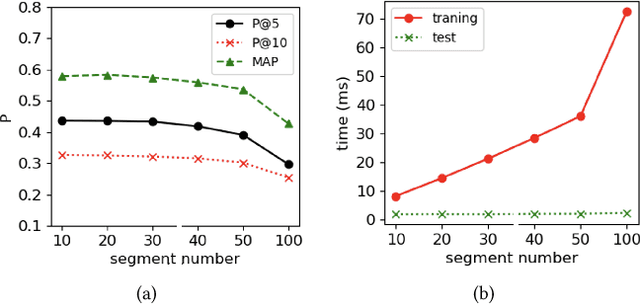
Many early neural Information Retrieval (NeurIR) methods are re-rankers that rely on a traditional first-stage retriever due to expensive query time computations. Recently, representation-based retrievers have gained much attention, which learns query representation and document representation separately, making it possible to pre-compute document representations offline and reduce the workload at query time. Both dense and sparse representation-based retrievers have been explored. However, these methods focus on finding the representation that best represents a text (aka metric learning) and the actual retrieval function that is responsible for similarity matching between query and document is kept at a minimum by using dot product. One drawback is that unlike traditional term-level inverted index, the index formed by these embeddings cannot be easily re-used by another retrieval method. Another drawback is that keeping the interaction at minimum hurts retrieval effectiveness. On the contrary, interaction-based retrievers are known for their better retrieval effectiveness. In this paper, we propose a novel SEgment-based Neural Indexing method, SEINE, which provides a general indexing framework that can flexibly support a variety of interaction-based neural retrieval methods. We emphasize on a careful decomposition of common components in existing neural retrieval methods and propose to use segment-level inverted index to store the atomic query-document interaction values. Experiments on LETOR MQ2007 and MQ2008 datasets show that our indexing method can accelerate multiple neural retrieval methods up to 28-times faster without sacrificing much effectiveness.
Sequencing Matters: A Generate-Retrieve-Generate Model for Building Conversational Agents
Nov 16, 2023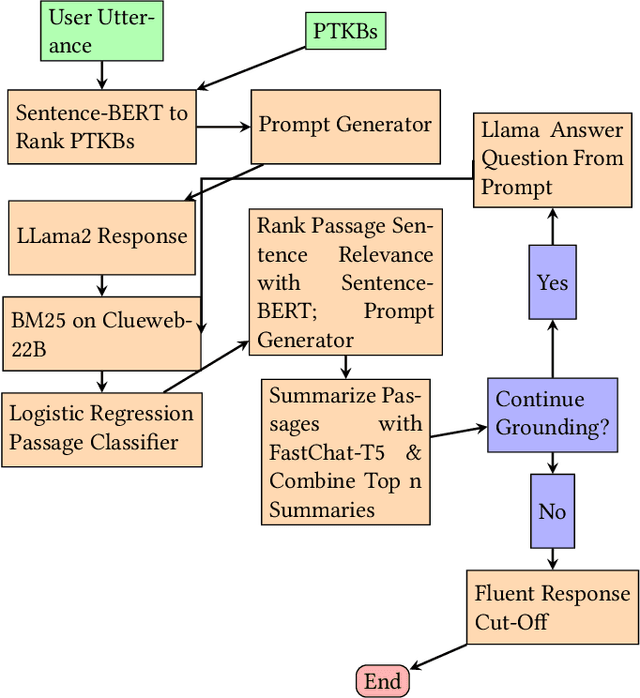
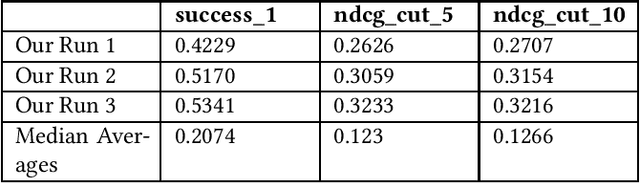


This paper contains what the Georgetown InfoSense group has done in regard to solving the challenges presented by TREC iKAT 2023. Our submitted runs outperform the median runs by a significant margin, exhibiting superior performance in nDCG across various cut numbers and in overall success rate. Our approach uses a Generate-Retrieve-Generate method, which we've found to greatly outpace Retrieve-Then-Generate approaches for the purposes of iKAT. Our solution involves the use of Large Language Models (LLMs) for initial answers, answer grounding by BM25, passage quality filtering by logistic regression, and answer generation by LLMs again. We leverage several purpose-built Language Models, including BERT, Chat-based, and text-to-transfer-based models, for text understanding, classification, generation, and summarization. The official results of the TREC evaluation contradict our initial self-evaluation, which may suggest that a decrease in the reliance on our retrieval and classification methods is better. Nonetheless, our findings suggest that the sequence of involving these different components matters, where we see an essentiality of using LLMs before using search engines.
GazBy: Gaze-Based BERT Model to Incorporate Human Attention in Neural Information Retrieval
Jul 04, 2022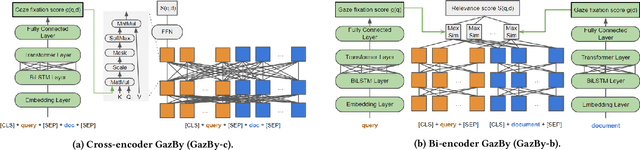
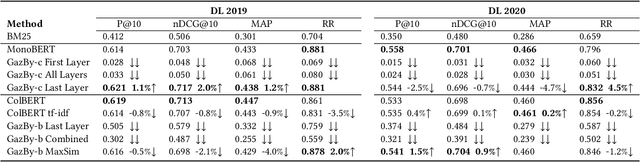
This paper is interested in investigating whether human gaze signals can be leveraged to improve state-of-the-art search engine performance and how to incorporate this new input signal marked by human attention into existing neural retrieval models. In this paper, we propose GazBy ({\bf Gaz}e-based {\bf B}ert model for document relevanc{\bf y}), a light-weight joint model that integrates human gaze fixation estimation into transformer models to predict document relevance, incorporating more nuanced information about cognitive processing into information retrieval (IR). We evaluate our model on the Text Retrieval Conference (TREC) Deep Learning (DL) 2019 and 2020 Tracks. Our experiments show encouraging results and illustrate the effective and ineffective entry points for using human gaze to help with transformer-based neural retrievers. With the rise of virtual reality (VR) and augmented reality (AR), human gaze data will become more available. We hope this work serves as a first step exploring using gaze signals in modern neural search engines.
Incorporating Voice Instructions in Model-Based Reinforcement Learning for Self-Driving Cars
Jun 21, 2022
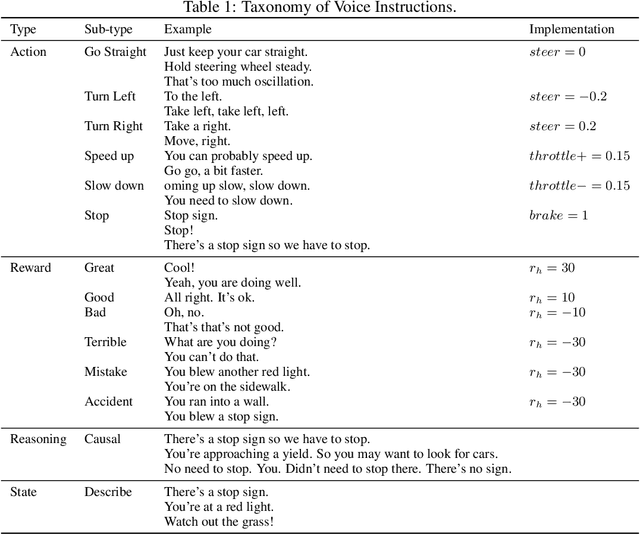
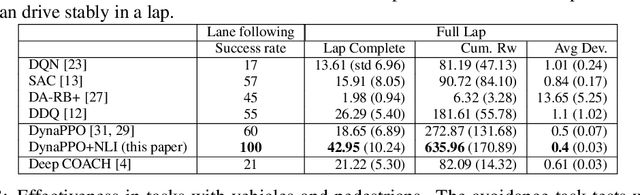
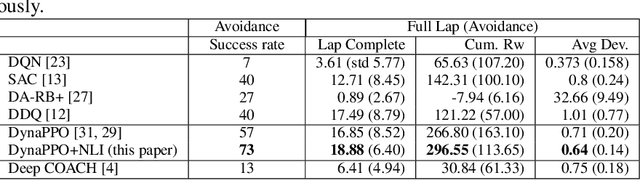
This paper presents a novel approach that supports natural language voice instructions to guide deep reinforcement learning (DRL) algorithms when training self-driving cars. DRL methods are popular approaches for autonomous vehicle (AV) agents. However, most existing methods are sample- and time-inefficient and lack a natural communication channel with the human expert. In this paper, how new human drivers learn from human coaches motivates us to study new ways of human-in-the-loop learning and a more natural and approachable training interface for the agents. We propose incorporating natural language voice instructions (NLI) in model-based deep reinforcement learning to train self-driving cars. We evaluate the proposed method together with a few state-of-the-art DRL methods in the CARLA simulator. The results show that NLI can help ease the training process and significantly boost the agents' learning speed.
Feature Modulation to Improve Struggle Detection in Web Search: A Psychological Approach
Dec 09, 2021
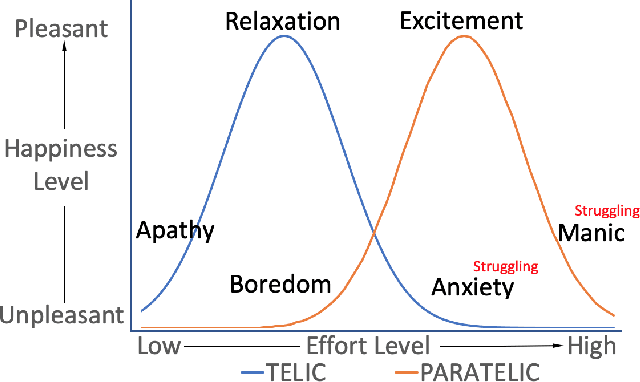
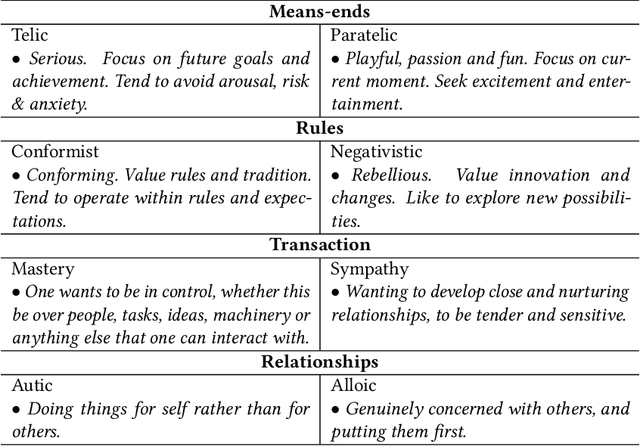
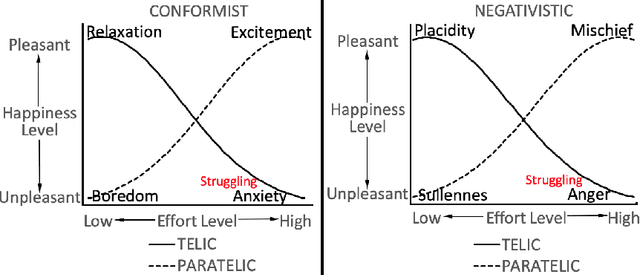
Searcher struggle is important feedback to Web search engines. Existing Web search struggle detection methods rely on effort-based features to identify the struggling moments. Their underlying assumption is that the more effort a user spends, the more struggling the user may be. However, recent studies have suggested this simple association might be incorrect. This paper proposes a new feature modulation method for struggle detection and refers to the reversal theory in psychology. The reversal theory (RT) points out that instead of having a static personality trait, people constantly switch between opposite psychological states, complicating the relationship between the efforts they spend and the level of frustration they feel. Supported by the theory, our method modulates the effort-based features based on RT's bi-modal arousal model. Evaluations on week-long Web search logs confirm that the proposed method can statistically significantly improve state-of-the-art struggle detection methods.
High-Quality Diversification for Task-Oriented Dialogue Systems
Jun 09, 2021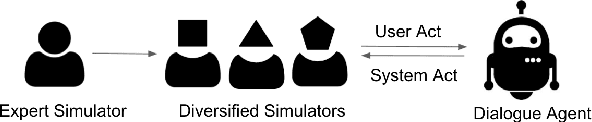
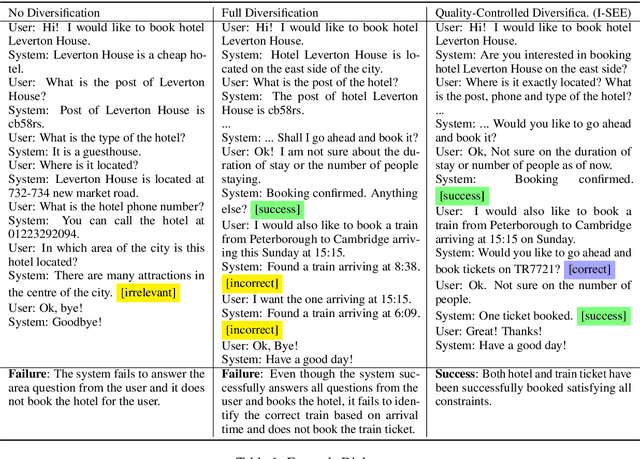
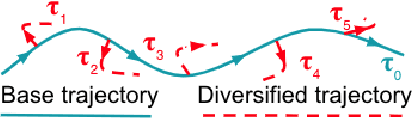

Many task-oriented dialogue systems use deep reinforcement learning (DRL) to learn policies that respond to the user appropriately and complete the tasks successfully. Training DRL agents with diverse dialogue trajectories prepare them well for rare user requests and unseen situations. One effective diversification method is to let the agent interact with a diverse set of learned user models. However, trajectories created by these artificial user models may contain generation errors, which can quickly propagate into the agent's policy. It is thus important to control the quality of the diversification and resist the noise. In this paper, we propose a novel dialogue diversification method for task-oriented dialogue systems trained in simulators. Our method, Intermittent Short Extension Ensemble (I-SEE), constrains the intensity to interact with an ensemble of diverse user models and effectively controls the quality of the diversification. Evaluations on the Multiwoz dataset show that I-SEE successfully boosts the performance of several state-of-the-art DRL dialogue agents.