 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexically-Accelerated Dense Retrieval
Jul 31, 2023Retrieval approaches that score documents based on learned dense vectors (i.e., dense retrieval) rather than lexical signals (i.e., conventional retrieval) are increasingly popular. Their ability to identify related documents that do not necessarily contain the same terms as those appearing in the user's query (thereby improving recall) is one of their key advantages. However, to actually achieve these gains, dense retrieval approaches typically require an exhaustive search over the document collection, making them considerably more expensive at query-time than conventional lexical approaches. Several techniques aim to reduce this computational overhead by approximating the results of a full dense retriever. Although these approaches reasonably approximate the top results, they suffer in terms of recall -- one of the key advantages of dense retrieval. We introduce 'LADR' (Lexically-Accelerated Dense Retrieval), a simple-yet-effective approach that improves the efficiency of existing dense retrieval models without compromising on retrieval effectiveness. LADR uses lexical retrieval techniques to seed a dense retrieval exploration that uses a document proximity graph. We explore two variants of LADR: a proactive approach that expands the search space to the neighbors of all seed documents, and an adaptive approach that selectively searches the documents with the highest estimated relevance in an iterative fashion. Through extensive experiments across a variety of dense retrieval models, we find that LADR establishes a new dense retrieval effectiveness-efficiency Pareto frontier among approximate k nearest neighbor techniques. Further, we find that when tuned to take around 8ms per query in retrieval latency on our hardware, LADR consistently achieves both precision and recall that are on par with an exhaustive search on standard benchmarks.
Sentiment Progression based Searching and Indexing of Literary Textual Artefacts
Jun 16, 2021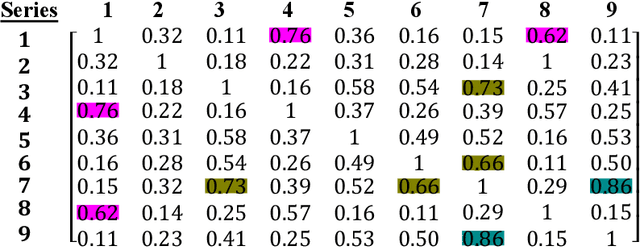
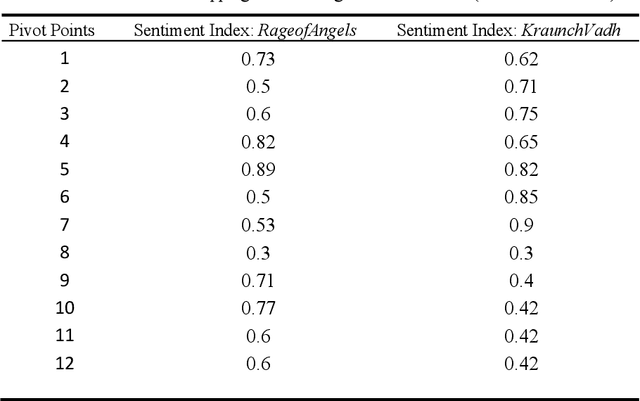
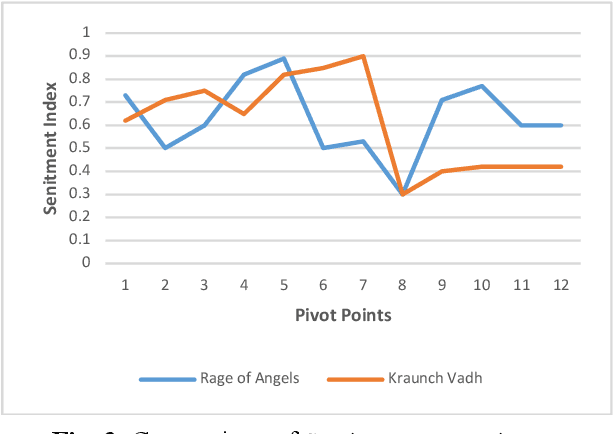
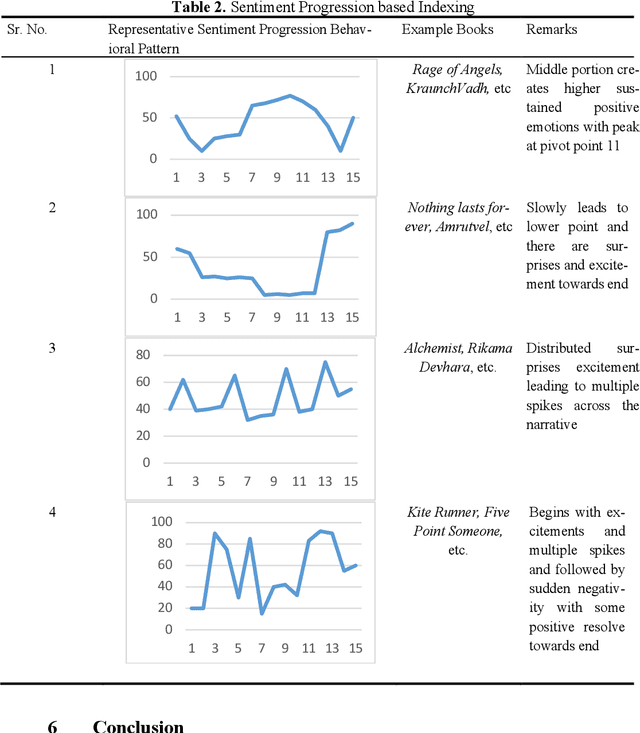
Literary artefacts are generally indexed and searched based on titles, meta data and keywords over the years. This searching and indexing works well when user/reader already knows about that particular creative textual artefact or document. This indexing and search hardly takes into account interest and emotional makeup of readers and its mapping to books. When a person is looking for a literary textual artefact, he/she might be looking for not only information but also to seek the joy of reading. In case of literary artefacts, progression of emotions across the key events could prove to be the key for indexing and searching. In this paper, we establish clusters among literary artefacts based on computational relationships among sentiment progressions using intelligent text analysis. We have created a database of 1076 English titles + 20 Marathi titles and also used database http://www.cs.cmu.edu/~dbamman/booksummaries.html with 16559 titles and their summaries. We have proposed Sentiment Progression based Indexing for searching and recommending books. This can be used to create personalized clusters of book titles of interest to readers. The analysis clearly suggests better searching and indexing when we are targeting book lovers looking for a particular type of book or creative artefact. This indexing and searching can find many real-life applications for recommending books.
High-Quality Diversification for Task-Oriented Dialogue Systems
Jun 09, 2021
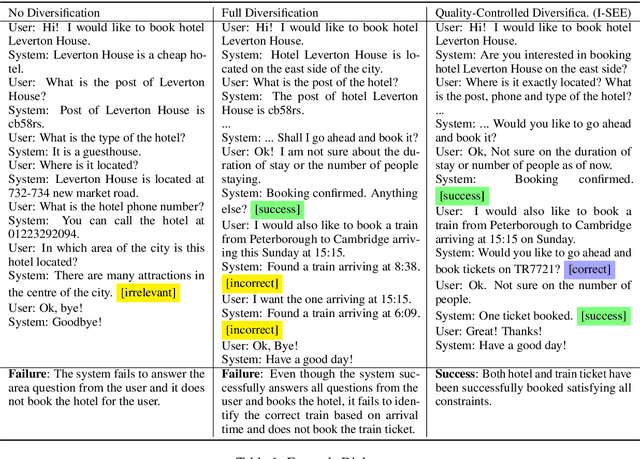

Many task-oriented dialogue systems use deep reinforcement learning (DRL) to learn policies that respond to the user appropriately and complete the tasks successfully. Training DRL agents with diverse dialogue trajectories prepare them well for rare user requests and unseen situations. One effective diversification method is to let the agent interact with a diverse set of learned user models. However, trajectories created by these artificial user models may contain generation errors, which can quickly propagate into the agent's policy. It is thus important to control the quality of the diversification and resist the noise. In this paper, we propose a novel dialogue diversification method for task-oriented dialogue systems trained in simulators. Our method, Intermittent Short Extension Ensemble (I-SEE), constrains the intensity to interact with an ensemble of diverse user models and effectively controls the quality of the diversification. Evaluations on the Multiwoz dataset show that I-SEE successfully boosts the performance of several state-of-the-art DRL dialogue agents.
Computational Psychology to Embed Emotions into News or Advertisements to Increase Reader Affinity
Oct 14, 2019

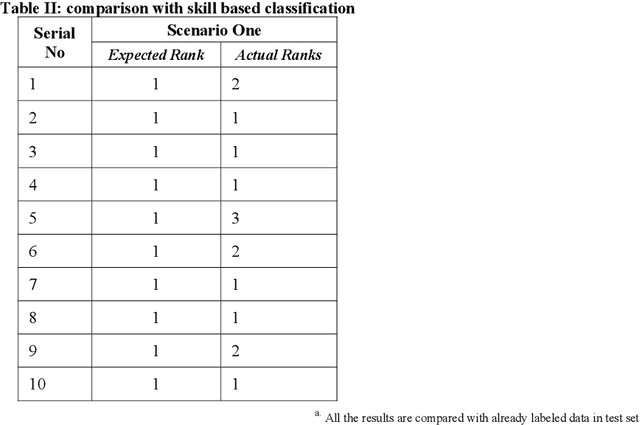
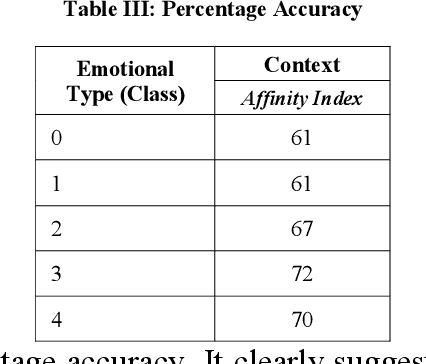
Readers take decisions about going through the complete news based on many factors. The emotional impact of the news title on reader is one of the most important factors. Cognitive ergonomics tries to strike the balance between work, product and environment with human needs and capabilities. The utmost need to integrate emotions in the news as well as advertisements cannot be denied. The idea is that news or advertisement should be able to engage the reader on emotional and behavioral platform. While achieving this objective there is need to learn about reader behavior and use computational psychology while presenting as well as writing news or advertisements. This paper based on Machine Learning, tries to map behavior of the reader with the news/advertisements and also provide inputs for affective value for building personalized news or advertisements presentations. The affective value of the news is determined and news artifacts are mapped to reader. The algorithm suggests the most suitable news for readers while understanding emotional traits required for personalization. This work can be used to improve reader satisfaction through embedding emotions in the reading material and prioritizing news presentations. It can be used to map personal reading material range, personalized programs and ranking programs, advertisements with reference to individuals.
Cultural association based on machine learning for team formation
Aug 01, 2019

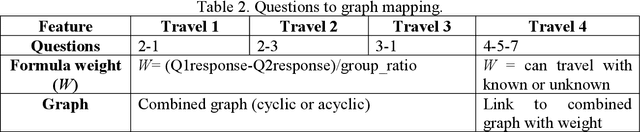

Culture is core to human civilization, and is essential for human intellectual achievements in social context. Culture also influences how humans work together, perform particular task and overall lifestyle and dealing with other groups of civilization. Thus, culture is concerned with establishing shared ideas, particularly those playing a key role in success. Does it impact on how two individuals can work together in achieving certain goals? In this paper, we establish a means to derive cultural association and map it to culturally mediated success. Human interactions with the environment are typically in the form of expressions. Association between culture and behavior produce similar beliefs which lead to common principles and actions, while cultural similarity as a set of common expressions and responses. To measure cultural association among different candidates, we propose the use of a Graphical Association Method (GAM). The behaviors of candidates are captured through series of expressions and represented in the graphical form. The association among corresponding node and core nodes is used for the same. Our approach provides a number of interesting results and promising avenues for future applications.