 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Reinforcement Learning Training Experiences in Interactive Information Retrieval
Paper and Code
Jun 05, 2020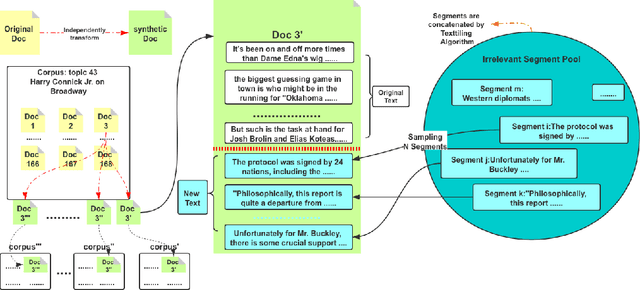
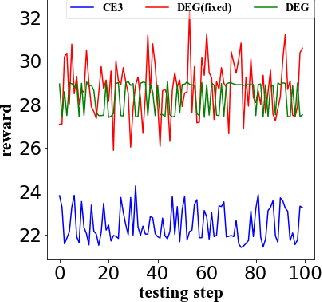
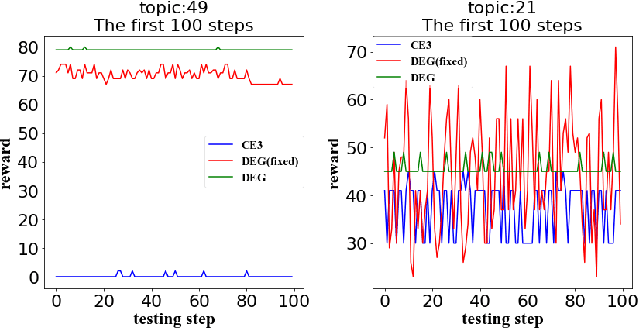
Interactive Information Retrieval (IIR) and Reinforcement Learning (RL) share many commonalities, including an agent who learns while interacts, a long-term and complex goal, and an algorithm that explores and adapts. To successfully apply RL methods to IIR, one challenge is to obtain sufficient relevance labels to train the RL agents, which are infamously known as sample inefficient. However, in a text corpus annotated for a given query, it is not the relevant documents but the irrelevant documents that predominate. This would cause very unbalanced training experiences for the agent and prevent it from learning any policy that is effective. Our paper addresses this issue by using domain randomization to synthesize more relevant documents for the training. Our experimental results on the Text REtrieval Conference (TREC) Dynamic Domain (DD) 2017 Track show that the proposed method is able to boost an RL agent's learning effectiveness by 22\% in dealing with unseen situations.