 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Simulate L2-English Dialogue? An Information-Theoretic Analysis of L1-Dependent Biases
Feb 20, 2025This study evaluates Large Language Models' (LLMs) ability to simulate non-native-like English use observed in human second language (L2) learners interfered with by their native first language (L1). In dialogue-based interviews, we prompt LLMs to mimic L2 English learners with specific L1s (e.g., Japanese, Thai, Urdu) across seven languages, comparing their outputs to real L2 learner data. Our analysis examines L1-driven linguistic biases, such as reference word usage and avoidance behaviors, using information-theoretic and distributional density measures. Results show that modern LLMs (e.g., Qwen2.5, LLAMA3.3, DeepseekV3, GPT-4o) replicate L1-dependent patterns observed in human L2 data, with distinct influences from various languages (e.g., Japanese, Korean, and Mandarin significantly affect tense agreement, and Urdu influences noun-verb collocations). Our results reveal the potential of LLMs for L2 dialogue generation and evaluation for future educational applications.
A Survey on Multi-Generative Agent System: Recent Advances and New Frontiers
Dec 23, 2024



Multi-generative agent systems (MGASs) have become a research hotspot since the rise of large language models (LLMs). However, with the continuous influx of new related works, the existing reviews struggle to capture them comprehensively. This paper presents a comprehensive survey of these studies. We first discuss the definition of MGAS, a framework encompassing much of previous work. We provide an overview of the various applications of MGAS in (i) solving complex tasks, (ii) simulating specific scenarios, and (iii) evaluating generative agents. Building on previous studies, we also highlight several challenges and propose future directions for research in this field.
Simulation-Free Hierarchical Latent Policy Planning for Proactive Dialogues
Dec 19, 2024



Recent advancements in proactive dialogues have garnered significant attention, particularly for more complex objectives (e.g. emotion support and persuasion). Unlike traditional task-oriented dialogues, proactive dialogues demand advanced policy planning and adaptability, requiring rich scenarios and comprehensive policy repositories to develop such systems. However, existing approaches tend to rely on Large Language Models (LLMs) for user simulation and online learning, leading to biases that diverge from realistic scenarios and result in suboptimal efficiency. Moreover, these methods depend on manually defined, context-independent, coarse-grained policies, which not only incur high expert costs but also raise concerns regarding their completeness. In our work, we highlight the potential for automatically discovering policies directly from raw, real-world dialogue records. To this end, we introduce a novel dialogue policy planning framework, LDPP. It fully automates the process from mining policies in dialogue records to learning policy planning. Specifically, we employ a variant of the Variational Autoencoder to discover fine-grained policies represented as latent vectors. After automatically annotating the data with these latent policy labels, we propose an Offline Hierarchical Reinforcement Learning (RL) algorithm in the latent space to develop effective policy planning capabilities. Our experiments demonstrate that LDPP outperforms existing methods on two proactive scenarios, even surpassing ChatGPT with only a 1.8-billion-parameter LLM.
Planning Like Human: A Dual-process Framework for Dialogue Planning
Jun 08, 2024

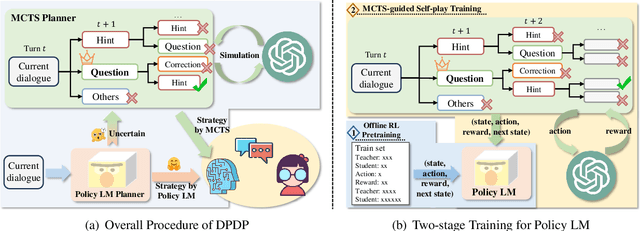

In proactive dialogue, the challenge lies not just in generating responses but in steering conversations toward predetermined goals, a task where Large Language Models (LLMs) typically struggle due to their reactive nature. Traditional approaches to enhance dialogue planning in LLMs, ranging from elaborate prompt engineering to the integration of policy networks, either face efficiency issues or deliver suboptimal performance. Inspired by the dualprocess theory in psychology, which identifies two distinct modes of thinking - intuitive (fast) and analytical (slow), we propose the Dual-Process Dialogue Planning (DPDP) framework. DPDP embodies this theory through two complementary planning systems: an instinctive policy model for familiar contexts and a deliberative Monte Carlo Tree Search (MCTS) mechanism for complex, novel scenarios. This dual strategy is further coupled with a novel two-stage training regimen: offline Reinforcement Learning for robust initial policy model formation followed by MCTS-enhanced on-the-fly learning, which ensures a dynamic balance between efficiency and strategic depth. Our empirical evaluations across diverse dialogue tasks affirm DPDP's superiority in achieving both high-quality dialogues and operational efficiency, outpacing existing methods.
Conversational Recommender System and Large Language Model Are Made for Each Other in E-commerce Pre-sales Dialogue
Oct 23, 2023



E-commerce pre-sales dialogue aims to understand and elicit user needs and preferences for the items they are seeking so as to provide appropriate recommendations. Conversational recommender systems (CRSs) learn user representation and provide accurate recommendations based on dialogue context, but rely on external knowledge. Large language models (LLMs) generate responses that mimic pre-sales dialogues after fine-tuning, but lack domain-specific knowledge for accurate recommendations. Intuitively, the strengths of LLM and CRS in E-commerce pre-sales dialogues are complementary, yet no previous work has explored this. This paper investigates the effectiveness of combining LLM and CRS in E-commerce pre-sales dialogues, proposing two collaboration methods: CRS assisting LLM and LLM assisting CRS. We conduct extensive experiments on a real-world dataset of Ecommerce pre-sales dialogues. We analyze the impact of two collaborative approaches with two CRSs and two LLMs on four tasks of Ecommerce pre-sales dialogue. We find that collaborations between CRS and LLM can be very effective in some cases.
U-NEED: A Fine-grained Dataset for User Needs-Centric E-commerce Conversational Recommendation
May 05, 2023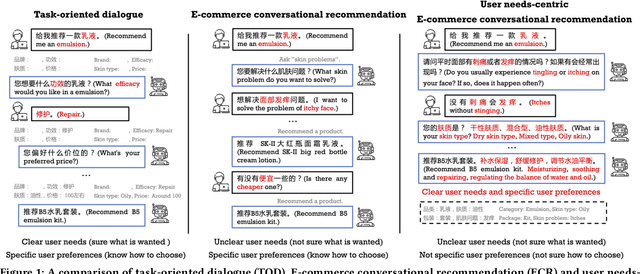
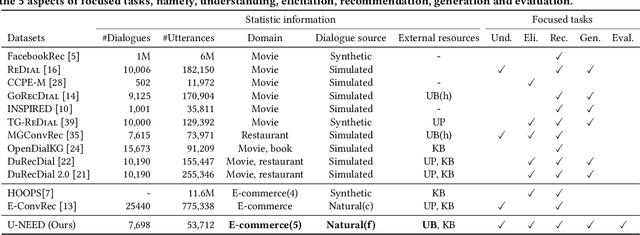
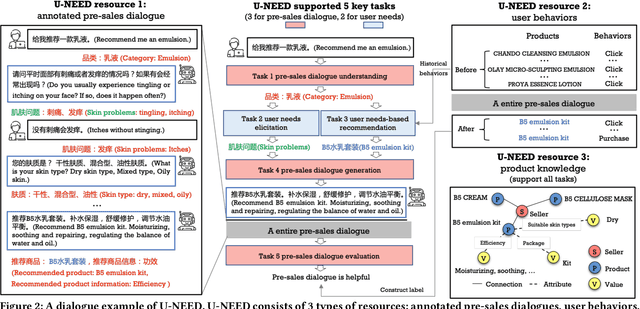
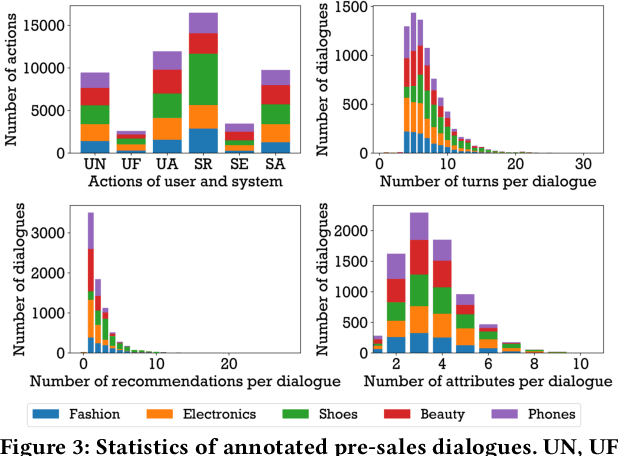
Conversational recommender systems (CRSs) aim to understand the information needs and preferences expressed in a dialogue to recommend suitable items to the user. Most of the existing conversational recommendation datasets are synthesized or simulated with crowdsourcing, which has a large gap with real-world scenarios. To bridge the gap, previous work contributes a dataset E-ConvRec, based on pre-sales dialogues between users and customer service staff in E-commerce scenarios. However, E-ConvRec only supplies coarse-grained annotations and general tasks for making recommendations in pre-sales dialogues. Different from that, we use real user needs as a clue to explore the E-commerce conversational recommendation in complex pre-sales dialogues, namely user needs-centric E-commerce conversational recommendation (UNECR). In this paper, we construct a user needs-centric E-commerce conversational recommendation dataset (U-NEED) from real-world E-commerce scenarios. U-NEED consists of 3 types of resources: (i) 7,698 fine-grained annotated pre-sales dialogues in 5 top categories (ii) 333,879 user behaviors and (iii) 332,148 product knowledge tuples. To facilitate the research of UNECR, we propose 5 critical tasks: (i) pre-sales dialogue understanding (ii) user needs elicitation (iii) user needs-based recommendation (iv) pre-sales dialogue generation and (v) pre-sales dialogue evaluation. We establish baseline methods and evaluation metrics for each task. We report experimental results of 5 tasks on U-NEED. We also report results in 3 typical categories. Experimental results indicate that the challenges of UNECR in various categories are different.