 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Sub-graph Distillation for Robust Semi-supervised Continual Learning
Dec 27, 2023



Continual learning (CL) has shown promising results and comparable performance to learning at once in a fully supervised manner. However, CL strategies typically require a large number of labeled samples, making their real-life deployment challenging. In this work, we focus on semi-supervised continual learning (SSCL), where the model progressively learns from partially labeled data with unknown categories. We provide a comprehensive analysis of SSCL and demonstrate that unreliable distributions of unlabeled data lead to unstable training and refinement of the progressing stages. This problem severely impacts the performance of SSCL. To address the limitations, we propose a novel approach called Dynamic Sub-Graph Distillation (DSGD) for semi-supervised continual learning, which leverages both semantic and structural information to achieve more stable knowledge distillation on unlabeled data and exhibit robustness against distribution bias. Firstly, we formalize a general model of structural distillation and design a dynamic graph construction for the continual learning progress. Next, we define a structure distillation vector and design a dynamic sub-graph distillation algorithm, which enables end-to-end training and adaptability to scale up tasks. The entire proposed method is adaptable to various CL methods and supervision settings. Finally, experiments conducted on three datasets CIFAR10, CIFAR100, and ImageNet-100, with varying supervision ratios, demonstrate the effectiveness of our proposed approach in mitigating the catastrophic forgetting problem in semi-supervised continual learning scenarios.
Improving Factual Consistency of Text Summarization by Adversarially Decoupling Comprehension and Embellishment Abilities of LLMs
Nov 01, 2023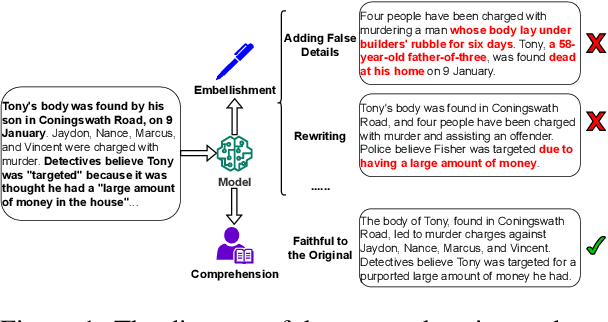
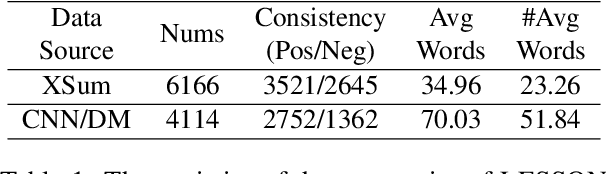
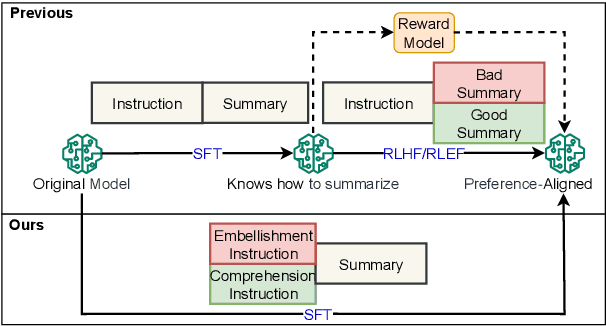
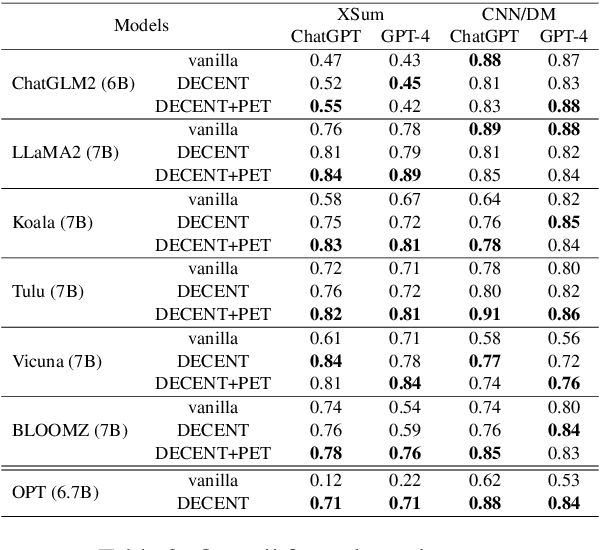
Despite the recent progress in text summarization made by large language models (LLMs), they often generate summaries that are factually inconsistent with original articles, known as "hallucinations" in text generation. Unlike previous small models (e.g., BART, T5), current LLMs make fewer silly mistakes but more sophisticated ones, such as imposing cause and effect, adding false details, and overgeneralizing, etc. These hallucinations are challenging to detect through traditional methods, which poses great challenges for improving the factual consistency of text summarization. In this paper, we propose an adversarially DEcoupling method to disentangle the Comprehension and EmbellishmeNT abilities of LLMs (DECENT). Furthermore, we adopt a probing-based parameter-efficient technique to cover the shortage of sensitivity for true and false in the training process of LLMs. In this way, LLMs are less confused about embellishing and understanding, thus can execute the instructions more accurately and have enhanced abilities to distinguish hallucinations. Experimental results show that DECENT significantly improves the reliability of text summarization based on LLMs.
U-NEED: A Fine-grained Dataset for User Needs-Centric E-commerce Conversational Recommendation
May 05, 2023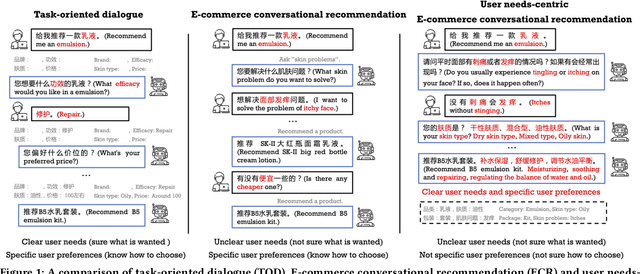
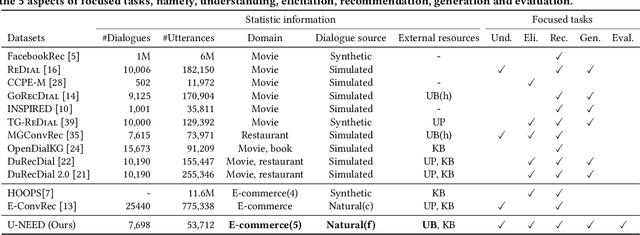
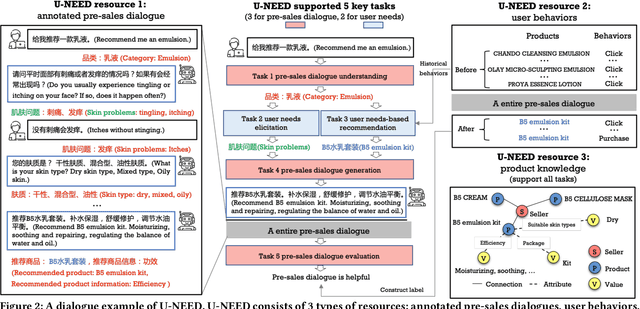
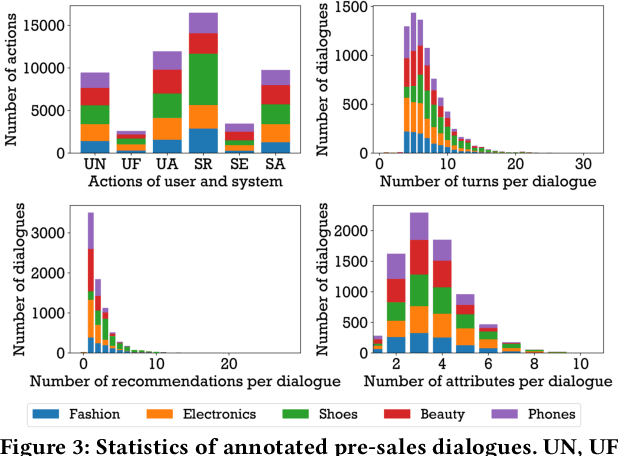
Conversational recommender systems (CRSs) aim to understand the information needs and preferences expressed in a dialogue to recommend suitable items to the user. Most of the existing conversational recommendation datasets are synthesized or simulated with crowdsourcing, which has a large gap with real-world scenarios. To bridge the gap, previous work contributes a dataset E-ConvRec, based on pre-sales dialogues between users and customer service staff in E-commerce scenarios. However, E-ConvRec only supplies coarse-grained annotations and general tasks for making recommendations in pre-sales dialogues. Different from that, we use real user needs as a clue to explore the E-commerce conversational recommendation in complex pre-sales dialogues, namely user needs-centric E-commerce conversational recommendation (UNECR). In this paper, we construct a user needs-centric E-commerce conversational recommendation dataset (U-NEED) from real-world E-commerce scenarios. U-NEED consists of 3 types of resources: (i) 7,698 fine-grained annotated pre-sales dialogues in 5 top categories (ii) 333,879 user behaviors and (iii) 332,148 product knowledge tuples. To facilitate the research of UNECR, we propose 5 critical tasks: (i) pre-sales dialogue understanding (ii) user needs elicitation (iii) user needs-based recommendation (iv) pre-sales dialogue generation and (v) pre-sales dialogue evaluation. We establish baseline methods and evaluation metrics for each task. We report experimental results of 5 tasks on U-NEED. We also report results in 3 typical categories. Experimental results indicate that the challenges of UNECR in various categories are different.