 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINDGAMES: A Live Arena for Evaluating Social and Strategic Reasoning in Multi-Agent LLMs
May 28, 2026Large language models (LLMs) are increasingly deployed as interactive agents, yet their capacity for social and strategic reasoning over extended interaction remains poorly understood. Existing evaluations rely on static vignettes or single-game benchmarks that cannot capture the sustained, multi-faceted reasoning that real-world multi-agent settings demand. We introduce Mindgames, a multi-game arena and evaluation platform for LLM agents that operationalizes complementary reasoning demands relevant to ``theory of mind'': belief attribution under hidden information, opponent modeling through repeated strategic interaction, cooperative inference under knowledge asymmetries, and sustained deception in social deduction. Built on TextArena, Mindgames provides a unified interaction interface, TrueSkill-based rating, and full trajectory logging across four game environments. We instantiate Mindgames through a 2025 competition cycle hosted at a major AI conference, which assessed 944 submitted agents from 76 teams across four games: Colonel Blotto, Iterated Prisoner's Dilemma, Codenames, and Secret Mafia. Our analysis surfaces both agent-level and evaluation-level limitations: brittle rule adherence remains a major bottleneck, top-performing systems repeatedly rely on explicit structural scaffolding, and leaderboard validity differs sharply across environments. In particular, failure-heavy environments can reward robustness to opponent errors as much as strategic ability, with Secret Mafia exhibiting a pronounced error-survival confound in this cycle. We release a dataset of 29,571 multi-agent games with turn-level observations, actions, and rewards, together with MG-Ref, a deterministic offline tournament protocol that scores new agents against a frozen reference pool of top-ranked, low-error Stage~II submissions under the same error-attribution lens used in this analysis.
Simulation-Free Hierarchical Latent Policy Planning for Proactive Dialogues
Dec 19, 2024



Recent advancements in proactive dialogues have garnered significant attention, particularly for more complex objectives (e.g. emotion support and persuasion). Unlike traditional task-oriented dialogues, proactive dialogues demand advanced policy planning and adaptability, requiring rich scenarios and comprehensive policy repositories to develop such systems. However, existing approaches tend to rely on Large Language Models (LLMs) for user simulation and online learning, leading to biases that diverge from realistic scenarios and result in suboptimal efficiency. Moreover, these methods depend on manually defined, context-independent, coarse-grained policies, which not only incur high expert costs but also raise concerns regarding their completeness. In our work, we highlight the potential for automatically discovering policies directly from raw, real-world dialogue records. To this end, we introduce a novel dialogue policy planning framework, LDPP. It fully automates the process from mining policies in dialogue records to learning policy planning. Specifically, we employ a variant of the Variational Autoencoder to discover fine-grained policies represented as latent vectors. After automatically annotating the data with these latent policy labels, we propose an Offline Hierarchical Reinforcement Learning (RL) algorithm in the latent space to develop effective policy planning capabilities. Our experiments demonstrate that LDPP outperforms existing methods on two proactive scenarios, even surpassing ChatGPT with only a 1.8-billion-parameter LLM.
SPEED: Streaming Partition and Parallel Acceleration for Temporal Interaction Graph Embedding
Sep 11, 2023



Temporal Interaction Graphs (TIGs) are widely employed to model intricate real-world systems such as financial systems and social networks. To capture the dynamism and interdependencies of nodes, existing TIG embedding models need to process edges sequentially and chronologically. However, this requirement prevents it from being processed in parallel and struggle to accommodate burgeoning data volumes to GPU. Consequently, many large-scale temporal interaction graphs are confined to CPU processing. Furthermore, a generalized GPU scaling and acceleration approach remains unavailable. To facilitate large-scale TIGs' implementation on GPUs for acceleration, we introduce a novel training approach namely Streaming Edge Partitioning and Parallel Acceleration for Temporal Interaction Graph Embedding (SPEED). The SPEED is comprised of a Streaming Edge Partitioning Component (SEP) which addresses space overhead issue by assigning fewer nodes to each GPU, and a Parallel Acceleration Component (PAC) which enables simultaneous training of different sub-graphs, addressing time overhead issue. Our method can achieve a good balance in computing resources, computing time, and downstream task performance. Empirical validation across 7 real-world datasets demonstrates the potential to expedite training speeds by a factor of up to 19.29x. Simultaneously, resource consumption of a single-GPU can be diminished by up to 69%, thus enabling the multiple GPU-based training and acceleration encompassing millions of nodes and billions of edges. Furthermore, our approach also maintains its competitiveness in downstream tasks.
RDGSL: Dynamic Graph Representation Learning with Structure Learning
Sep 05, 2023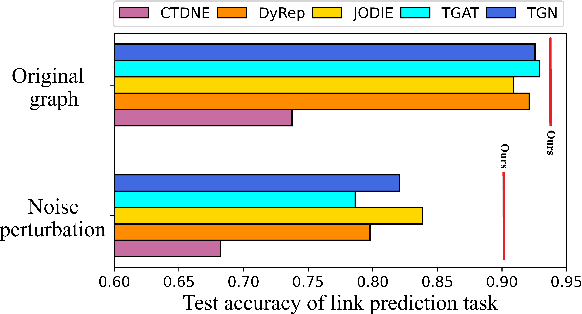

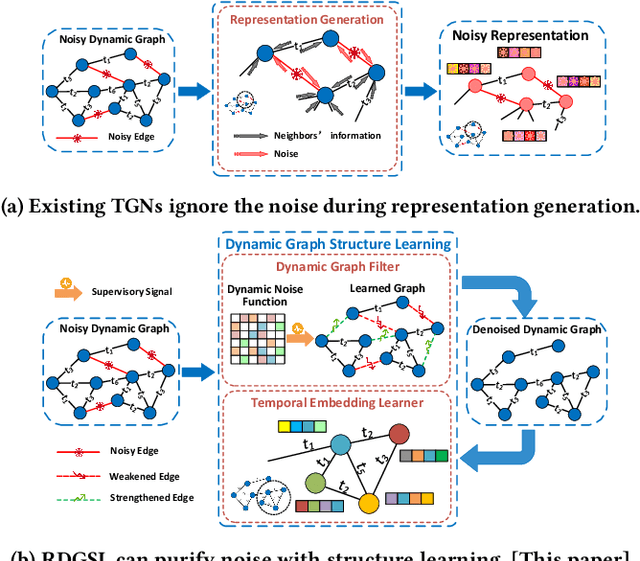
Temporal Graph Networks (TGNs) have shown remarkable performance in learning representation for continuous-time dynamic graphs. However, real-world dynamic graphs typically contain diverse and intricate noise. Noise can significantly degrade the quality of representation generation, impeding the effectiveness of TGNs in downstream tasks. Though structure learning is widely applied to mitigate noise in static graphs, its adaptation to dynamic graph settings poses two significant challenges. i) Noise dynamics. Existing structure learning methods are ill-equipped to address the temporal aspect of noise, hampering their effectiveness in such dynamic and ever-changing noise patterns. ii) More severe noise. Noise may be introduced along with multiple interactions between two nodes, leading to the re-pollution of these nodes and consequently causing more severe noise compared to static graphs. In this paper, we present RDGSL, a representation learning method in continuous-time dynamic graphs. Meanwhile, we propose dynamic graph structure learning, a novel supervisory signal that empowers RDGSL with the ability to effectively combat noise in dynamic graphs. To address the noise dynamics issue, we introduce the Dynamic Graph Filter, where we innovatively propose a dynamic noise function that dynamically captures both current and historical noise, enabling us to assess the temporal aspect of noise and generate a denoised graph. We further propose the Temporal Embedding Learner to tackle the challenge of more severe noise, which utilizes an attention mechanism to selectively turn a blind eye to noisy edges and hence focus on normal edges, enhancing the expressiveness for representation generation that remains resilient to noise. Our method demonstrates robustness towards downstream tasks, resulting in up to 5.1% absolute AUC improvement in evolving classification versus the second-best baseline.
iLoRE: Dynamic Graph Representation with Instant Long-term Modeling and Re-occurrence Preservation
Sep 05, 2023



Continuous-time dynamic graph modeling is a crucial task for many real-world applications, such as financial risk management and fraud detection. Though existing dynamic graph modeling methods have achieved satisfactory results, they still suffer from three key limitations, hindering their scalability and further applicability. i) Indiscriminate updating. For incoming edges, existing methods would indiscriminately deal with them, which may lead to more time consumption and unexpected noisy information. ii) Ineffective node-wise long-term modeling. They heavily rely on recurrent neural networks (RNNs) as a backbone, which has been demonstrated to be incapable of fully capturing node-wise long-term dependencies in event sequences. iii) Neglect of re-occurrence patterns. Dynamic graphs involve the repeated occurrence of neighbors that indicates their importance, which is disappointedly neglected by existing methods. In this paper, we present iLoRE, a novel dynamic graph modeling method with instant node-wise Long-term modeling and Re-occurrence preservation. To overcome the indiscriminate updating issue, we introduce the Adaptive Short-term Updater module that will automatically discard the useless or noisy edges, ensuring iLoRE's effectiveness and instant ability. We further propose the Long-term Updater to realize more effective node-wise long-term modeling, where we innovatively propose the Identity Attention mechanism to empower a Transformer-based updater, bypassing the limited effectiveness of typical RNN-dominated designs. Finally, the crucial re-occurrence patterns are also encoded into a graph module for informative representation learning, which will further improve the expressiveness of our method. Our experimental results on real-world datasets demonstrate the effectiveness of our iLoRE for dynamic graph modeling.
Flexible Differentially Private Vertical Federated Learning with Adaptive Feature Embeddings
Jul 26, 2023



The emergence of vertical federated learning (VFL) has stimulated concerns about the imperfection in privacy protection, as shared feature embeddings may reveal sensitive information under privacy attacks. This paper studies the delicate equilibrium between data privacy and task utility goals of VFL under differential privacy (DP). To address the generality issue of prior arts, this paper advocates a flexible and generic approach that decouples the two goals and addresses them successively. Specifically, we initially derive a rigorous privacy guarantee by applying norm clipping on shared feature embeddings, which is applicable across various datasets and models. Subsequently, we demonstrate that task utility can be optimized via adaptive adjustments on the scale and distribution of feature embeddings in an accuracy-appreciative way, without compromising established DP mechanisms. We concretize our observation into the proposed VFL-AFE framework, which exhibits effectiveness against privacy attacks and the capacity to retain favorable task utility, as substantiated by extensive experiments.
TIGER: Temporal Interaction Graph Embedding with Restarts
Feb 16, 2023



Temporal interaction graphs (TIGs), consisting of sequences of timestamped interaction events, are prevalent in fields like e-commerce and social networks. To better learn dynamic node embeddings that vary over time, researchers have proposed a series of temporal graph neural networks for TIGs. However, due to the entangled temporal and structural dependencies, existing methods have to process the sequence of events chronologically and consecutively to ensure node representations are up-to-date. This prevents existing models from parallelization and reduces their flexibility in industrial applications. To tackle the above challenge, in this paper, we propose TIGER, a TIG embedding model that can restart at any timestamp. We introduce a restarter module that generates surrogate representations acting as the warm initialization of node representations. By restarting from multiple timestamps simultaneously, we divide the sequence into multiple chunks and naturally enable the parallelization of the model. Moreover, in contrast to previous models that utilize a single memory unit, we introduce a dual memory module to better exploit neighborhood information and alleviate the staleness problem. Extensive experiments on four public datasets and one industrial dataset are conducted, and the results verify both the effectiveness and the efficiency of our work.
RuDi: Explaining Behavior Sequence Models by Automatic Statistics Generation and Rule Distillation
Aug 16, 2022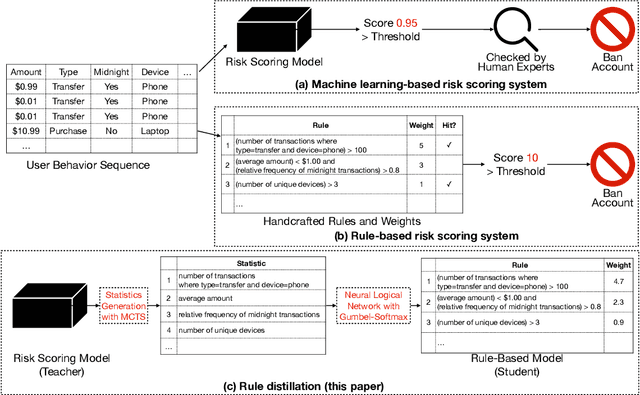
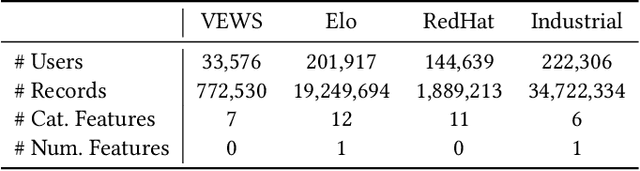
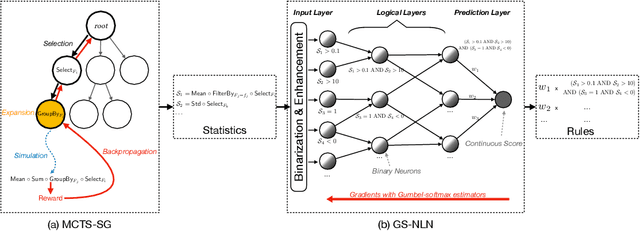
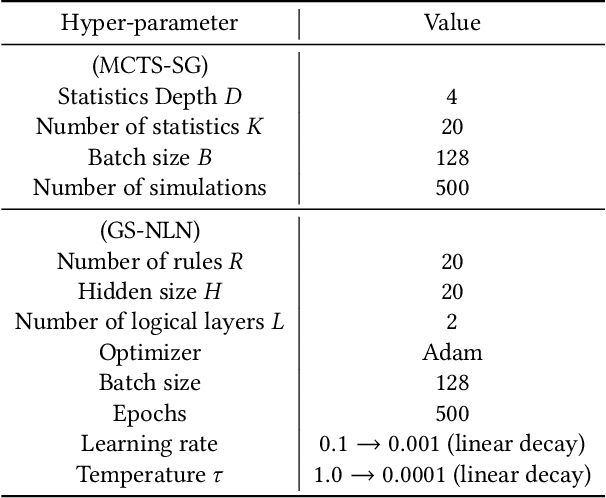
Risk scoring systems have been widely deployed in many applications, which assign risk scores to users according to their behavior sequences. Though many deep learning methods with sophisticated designs have achieved promising results, the black-box nature hinders their applications due to fairness, explainability, and compliance consideration. Rule-based systems are considered reliable in these sensitive scenarios. However, building a rule system is labor-intensive. Experts need to find informative statistics from user behavior sequences, design rules based on statistics and assign weights to each rule. In this paper, we bridge the gap between effective but black-box models and transparent rule models. We propose a two-stage method, RuDi, that distills the knowledge of black-box teacher models into rule-based student models. We design a Monte Carlo tree search-based statistics generation method that can provide a set of informative statistics in the first stage. Then statistics are composed into logical rules with our proposed neural logical networks by mimicking the outputs of teacher models. We evaluate RuDi on three real-world public datasets and an industrial dataset to demonstrate its effectiveness.
TransBoost: A Boosting-Tree Kernel Transfer Learning Algorithm for Improving Financial Inclusion
Dec 16, 2021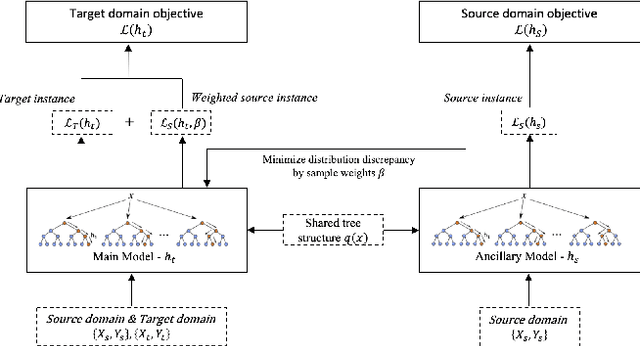
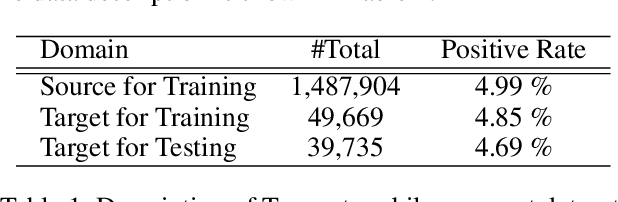
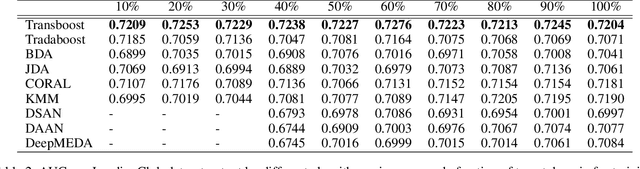
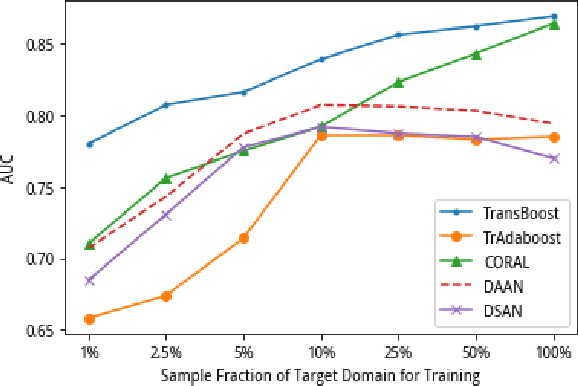
The prosperity of mobile and financial technologies has bred and expanded various kinds of financial products to a broader scope of people, which contributes to advocating financial inclusion. It has non-trivial social benefits of diminishing financial inequality. However, the technical challenges in individual financial risk evaluation caused by the distinct characteristic distribution and limited credit history of new users, as well as the inexperience of newly-entered companies in handling complex data and obtaining accurate labels, impede further promoting financial inclusion. To tackle these challenges, this paper develops a novel transfer learning algorithm (i.e., TransBoost) that combines the merits of tree-based models and kernel methods. The TransBoost is designed with a parallel tree structure and efficient weights updating mechanism with theoretical guarantee, which enables it to excel in tackling real-world data with high dimensional features and sparsity in $O(n)$ time complexity. We conduct extensive experiments on two public datasets and a unique large-scale dataset from Tencent Mobile Payment. The results show that the TransBoost outperforms other state-of-the-art benchmark transfer learning algorithms in terms of prediction accuracy with superior efficiency, shows stronger robustness to data sparsity, and provides meaningful model interpretation. Besides, given a financial risk level, the TransBoost enables financial service providers to serve the largest number of users including those who would otherwise be excluded by other algorithms. That is, the TransBoost improves financial inclusion.