 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastBEV++: Fast by Algorithm, Deployable by Design
Dec 09, 2025The advancement of camera-only Bird's-Eye-View(BEV) perception is currently impeded by a fundamental tension between state-of-the-art performance and on-vehicle deployment tractability. This bottleneck stems from a deep-rooted dependency on computationally prohibitive view transformations and bespoke, platform-specific kernels. This paper introduces FastBEV++, a framework engineered to reconcile this tension, demonstrating that high performance and deployment efficiency can be achieved in unison via two guiding principles: Fast by Algorithm and Deployable by Design. We realize the "Deployable by Design" principle through a novel view transformation paradigm that decomposes the monolithic projection into a standard Index-Gather-Reshape pipeline. Enabled by a deterministic pre-sorting strategy, this transformation is executed entirely with elementary, operator native primitives (e.g Gather, Matrix Multiplication), which eliminates the need for specialized CUDA kernels and ensures fully TensorRT-native portability. Concurrently, our framework is "Fast by Algorithm", leveraging this decomposed structure to seamlessly integrate an end-to-end, depth-aware fusion mechanism. This jointly learned depth modulation, further bolstered by temporal aggregation and robust data augmentation, significantly enhances the geometric fidelity of the BEV representation.Empirical validation on the nuScenes benchmark corroborates the efficacy of our approach. FastBEV++ establishes a new state-of-the-art 0.359 NDS while maintaining exceptional real-time performance, exceeding 134 FPS on automotive-grade hardware (e.g Tesla T4). By offering a solution that is free of custom plugins yet highly accurate, FastBEV++ presents a mature and scalable design philosophy for production autonomous systems. The code is released at: https://github.com/ymlab/advanced-fastbev
Precise Drive with VLM: First Prize Solution for PRCV 2024 Drive LM challenge
Nov 05, 2024



This technical report outlines the methodologies we applied for the PRCV Challenge, focusing on cognition and decision-making in driving scenarios. We employed InternVL-2.0, a pioneering open-source multi-modal model, and enhanced it by refining both the model input and training methodologies. For the input data, we strategically concatenated and formatted the multi-view images. It is worth mentioning that we utilized the coordinates of the original images without transformation. In terms of model training, we initially pre-trained the model on publicly available autonomous driving scenario datasets to bolster its alignment capabilities of the challenge tasks, followed by fine-tuning on the DriveLM-nuscenes Dataset. During the fine-tuning phase, we innovatively modified the loss function to enhance the model's precision in predicting coordinate values. These approaches ensure that our model possesses advanced cognitive and decision-making capabilities in driving scenarios. Consequently, our model achieved a score of 0.6064, securing the first prize on the competition's final results.
Online Electric Vehicle Charging Detection Based on Memory-based Transformer using Smart Meter Data
Aug 06, 2024The growing popularity of Electric Vehicles (EVs) poses unique challenges for grid operators and infrastructure, which requires effectively managing these vehicles' integration into the grid. Identification of EVs charging is essential to electricity Distribution Network Operators (DNOs) for better planning and managing the distribution grid. One critical aspect is the ability to accurately identify the presence of EV charging in the grid. EV charging identification using smart meter readings obtained from behind-the-meter devices is a challenging task that enables effective managing the integration of EVs into the existing power grid. Different from the existing supervised models that require addressing the imbalance problem caused by EVs and non-EVs data, we propose a novel unsupervised memory-based transformer (M-TR) that can run in real-time (online) to detect EVs charging from a streaming smart meter. It dynamically leverages coarse-scale historical information using an M-TR encoder from an extended global temporal window, in conjunction with an M-TR decoder that concentrates on a limited time frame, local window, aiming to capture the fine-scale characteristics of the smart meter data. The M-TR is based on an anomaly detection technique that does not require any prior knowledge about EVs charging profiles, nor it does only require real power consumption data of non-EV users. In addition, the proposed model leverages the power of transfer learning. The M-TR is compared with different state-of-the-art methods and performs better than other unsupervised learning models. The model can run with an excellent execution time of 1.2 sec. for 1-minute smart recordings.
Clustering-based Multitasking Deep Neural Network for Solar Photovoltaics Power Generation Prediction
May 09, 2024The increasing installation of Photovoltaics (PV) cells leads to more generation of renewable energy sources (RES), but results in increased uncertainties of energy scheduling. Predicting PV power generation is important for energy management and dispatch optimization in smart grid. However, the PV power generation data is often collected across different types of customers (e.g., residential, agricultural, industrial, and commercial) while the customer information is always de-identified. This often results in a forecasting model trained with all PV power generation data, allowing the predictor to learn various patterns through intra-model self-learning, instead of constructing a separate predictor for each customer type. In this paper, we propose a clustering-based multitasking deep neural network (CM-DNN) framework for PV power generation prediction. K-means is applied to cluster the data into different customer types. For each type, a deep neural network (DNN) is employed and trained until the accuracy cannot be improved. Subsequently, for a specified customer type (i.e., the target task), inter-model knowledge transfer is conducted to enhance its training accuracy. During this process, source task selection is designed to choose the optimal subset of tasks (excluding the target customer), and each selected source task uses a coefficient to determine the amount of DNN model knowledge (weights and biases) transferred to the aimed prediction task. The proposed CM-DNN is tested on a real-world PV power generation dataset and its superiority is demonstrated by comparing the prediction performance on training the dataset with a single model without clustering.
RuDi: Explaining Behavior Sequence Models by Automatic Statistics Generation and Rule Distillation
Aug 16, 2022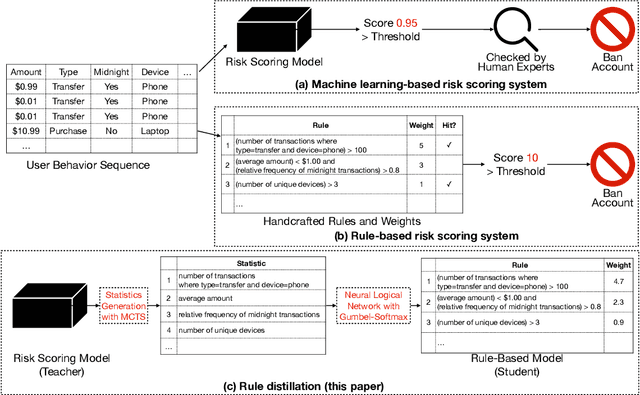
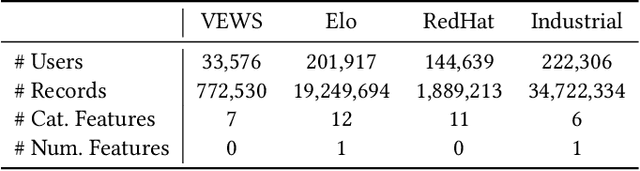
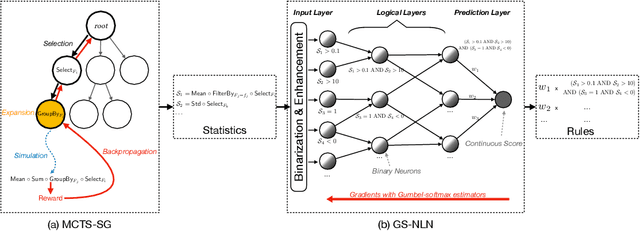
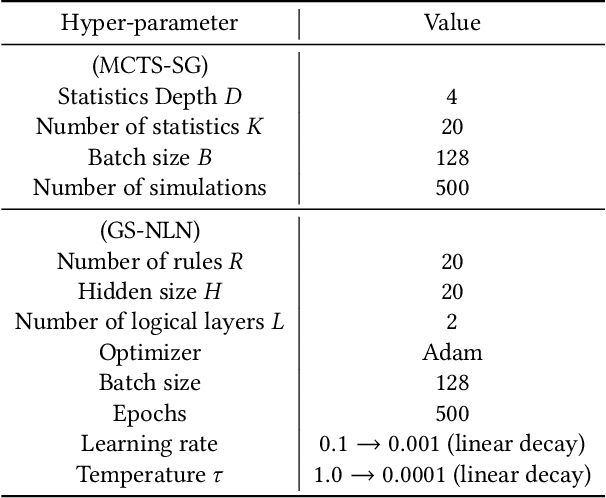
Risk scoring systems have been widely deployed in many applications, which assign risk scores to users according to their behavior sequences. Though many deep learning methods with sophisticated designs have achieved promising results, the black-box nature hinders their applications due to fairness, explainability, and compliance consideration. Rule-based systems are considered reliable in these sensitive scenarios. However, building a rule system is labor-intensive. Experts need to find informative statistics from user behavior sequences, design rules based on statistics and assign weights to each rule. In this paper, we bridge the gap between effective but black-box models and transparent rule models. We propose a two-stage method, RuDi, that distills the knowledge of black-box teacher models into rule-based student models. We design a Monte Carlo tree search-based statistics generation method that can provide a set of informative statistics in the first stage. Then statistics are composed into logical rules with our proposed neural logical networks by mimicking the outputs of teacher models. We evaluate RuDi on three real-world public datasets and an industrial dataset to demonstrate its effectiveness.
Multi-task Optimization Based Co-training for Electricity Consumption Prediction
May 31, 2022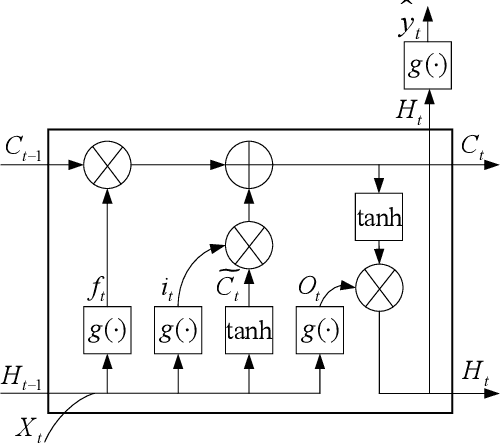



Real-world electricity consumption prediction may involve different tasks, e.g., prediction for different time steps ahead or different geo-locations. These tasks are often solved independently without utilizing some common problem-solving knowledge that could be extracted and shared among these tasks to augment the performance of solving each task. In this work, we propose a multi-task optimization (MTO) based co-training (MTO-CT) framework, where the models for solving different tasks are co-trained via an MTO paradigm in which solving each task may benefit from the knowledge gained from when solving some other tasks to help its solving process. MTO-CT leverages long short-term memory (LSTM) based model as the predictor where the knowledge is represented via connection weights and biases. In MTO-CT, an inter-task knowledge transfer module is designed to transfer knowledge between different tasks, where the most helpful source tasks are selected by using the probability matching and stochastic universal selection, and evolutionary operations like mutation and crossover are performed for reusing the knowledge from selected source tasks in a target task. We use electricity consumption data from five states in Australia to design two sets of tasks at different scales: a) one-step ahead prediction for each state (five tasks) and b) 6-step, 12-step, 18-step, and 24-step ahead prediction for each state (20 tasks). The performance of MTO-CT is evaluated on solving each of these two sets of tasks in comparison to solving each task in the set independently without knowledge sharing under the same settings, which demonstrates the superiority of MTO-CT in terms of prediction accuracy.
Evolutionary Ensemble Learning for Multivariate Time Series Prediction
Aug 22, 2021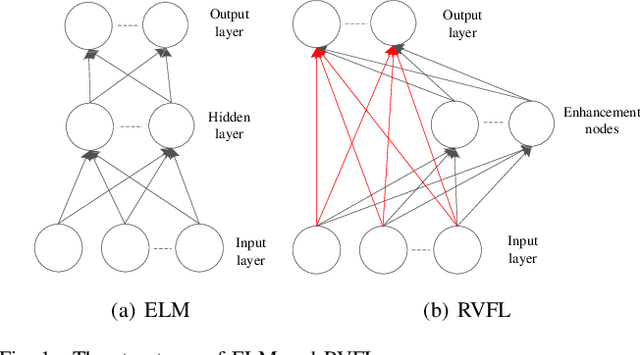
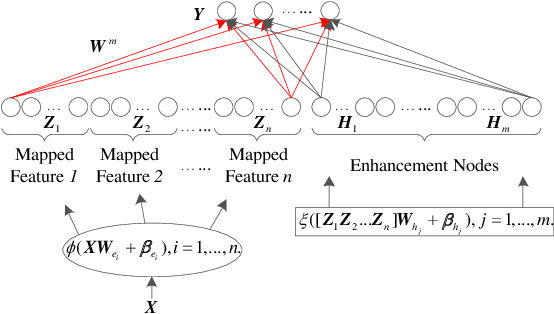
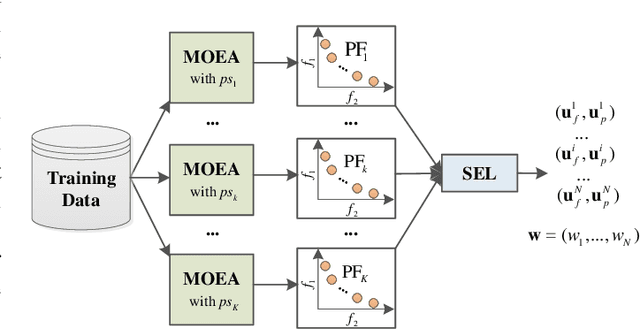
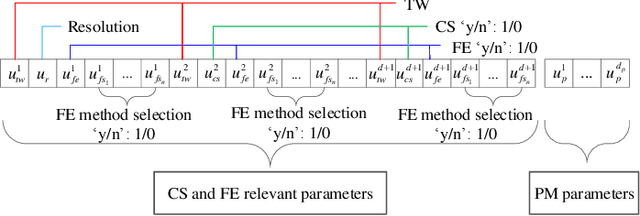
Multivariate time series (MTS) prediction plays a key role in many fields such as finance, energy and transport, where each individual time series corresponds to the data collected from a certain data source, so-called channel. A typical pipeline of building an MTS prediction model (PM) consists of selecting a subset of channels among all available ones, extracting features from the selected channels, and building a PM based on the extracted features, where each component involves certain optimization tasks, i.e., selection of channels, feature extraction (FE) methods, and PMs as well as configuration of the selected FE method and PM. Accordingly, pursuing the best prediction performance corresponds to optimizing the pipeline by solving all of its involved optimization problems. This is a non-trivial task due to the vastness of the solution space. Different from most of the existing works which target at optimizing certain components of the pipeline, we propose a novel evolutionary ensemble learning framework to optimize the entire pipeline in a holistic manner. In this framework, a specific pipeline is encoded as a candidate solution and a multi-objective evolutionary algorithm is applied under different population sizes to produce multiple Pareto optimal sets (POSs). Finally, selective ensemble learning is designed to choose the optimal subset of solutions from the POSs and combine them to yield final prediction by using greedy sequential selection and least square methods. We implement the proposed framework and evaluate our implementation on two real-world applications, i.e., electricity consumption prediction and air quality prediction. The performance comparison with state-of-the-art techniques demonstrates the superiority of the proposed approach.
DELTA: A DEep learning based Language Technology plAtform
Aug 02, 2019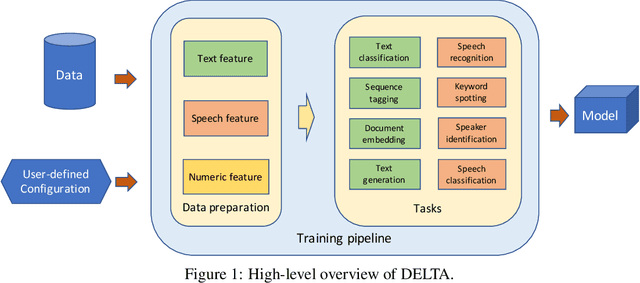
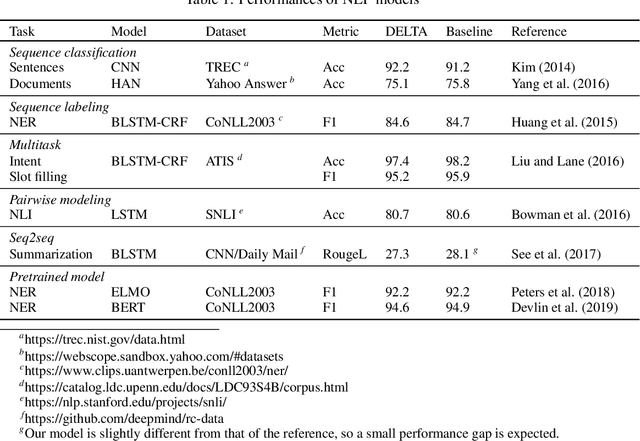
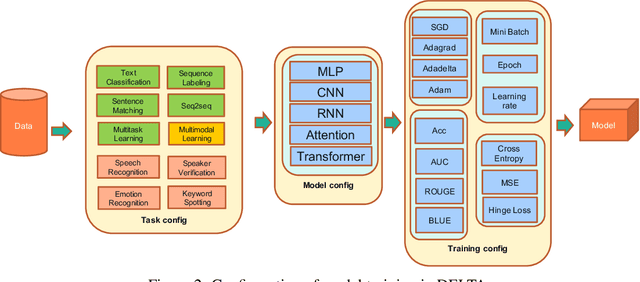
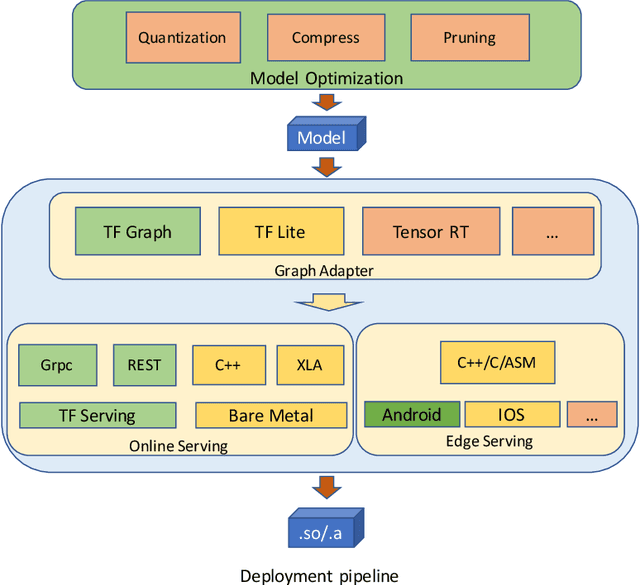
In this paper we present DELTA, a deep learning based language technology platform. DELTA is an end-to-end platform designed to solve industry level natural language and speech processing problems. It integrates most popular neural network models for training as well as comprehensive deployment tools for production. DELTA aims to provide easy and fast experiences for using, deploying, and developing natural language processing and speech models for both academia and industry use cases. We demonstrate the reliable performance with DELTA on several natural language processing and speech tasks, including text classification, named entity recognition, natural language inference, speech recognition, speaker verification, etc. DELTA has been used for developing several state-of-the-art algorithms for publications and delivering real production to serve millions of users.