 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Axis RCCL: Representation-Complete Convergent Learning for Organic Chemical Space
Dec 17, 2025
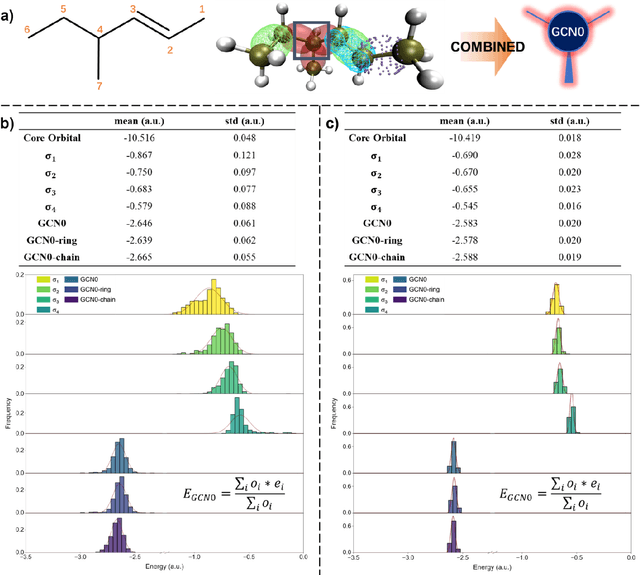


Machine learning is profoundly reshaping molecular and materials modeling; however, given the vast scale of chemical space (10^30-10^60), it remains an open scientific question whether models can achieve convergent learning across this space. We introduce a Dual-Axis Representation-Complete Convergent Learning (RCCL) strategy, enabled by a molecular representation that integrates graph convolutional network (GCN) encoding of local valence environments, grounded in modern valence bond theory, together with no-bridge graph (NBG) encoding of ring/cage topologies, providing a quantitative measure of chemical-space coverage. This framework formalizes representation completeness, establishing a principled basis for constructing datasets that support convergent learning for large models. Guided by this RCCL framework, we develop the FD25 dataset, systematically covering 13,302 local valence units and 165,726 ring/cage topologies, achieving near-complete combinatorial coverage of organic molecules with H/C/N/O/F elements. Graph neural networks trained on FD25 exhibit representation-complete convergent learning and strong out-of-distribution generalization, with an overall prediction error of approximately 1.0 kcal/mol MAE across external benchmarks. Our results establish a quantitative link between molecular representation, structural completeness, and model generalization, providing a foundation for interpretable, transferable, and data-efficient molecular intelligence.
CA-Edit: Causality-Aware Condition Adapter for High-Fidelity Local Facial Attribute Editing
Dec 18, 2024



For efficient and high-fidelity local facial attribute editing, most existing editing methods either require additional fine-tuning for different editing effects or tend to affect beyond the editing regions. Alternatively, inpainting methods can edit the target image region while preserving external areas. However, current inpainting methods still suffer from the generation misalignment with facial attributes description and the loss of facial skin details. To address these challenges, (i) a novel data utilization strategy is introduced to construct datasets consisting of attribute-text-image triples from a data-driven perspective, (ii) a Causality-Aware Condition Adapter is proposed to enhance the contextual causality modeling of specific details, which encodes the skin details from the original image while preventing conflicts between these cues and textual conditions. In addition, a Skin Transition Frequency Guidance technique is introduced for the local modeling of contextual causality via sampling guidance driven by low-frequency alignment. Extensive quantitative and qualitative experiments demonstrate the effectiveness of our method in boosting both fidelity and editability for localized attribute editing. The code is available at https://github.com/connorxian/CA-Edit.
PainterNet: Adaptive Image Inpainting with Actual-Token Attention and Diverse Mask Control
Dec 02, 2024



Recently, diffusion models have exhibited superior performance in the area of image inpainting. Inpainting methods based on diffusion models can usually generate realistic, high-quality image content for masked areas. However, due to the limitations of diffusion models, existing methods typically encounter problems in terms of semantic consistency between images and text, and the editing habits of users. To address these issues, we present PainterNet, a plugin that can be flexibly embedded into various diffusion models. To generate image content in the masked areas that highly aligns with the user input prompt, we proposed local prompt input, Attention Control Points (ACP), and Actual-Token Attention Loss (ATAL) to enhance the model's focus on local areas. Additionally, we redesigned the MASK generation algorithm in training and testing dataset to simulate the user's habit of applying MASK, and introduced a customized new training dataset, PainterData, and a benchmark dataset, PainterBench. Our extensive experimental analysis exhibits that PainterNet surpasses existing state-of-the-art models in key metrics including image quality and global/local text consistency.
Precise Drive with VLM: First Prize Solution for PRCV 2024 Drive LM challenge
Nov 05, 2024



This technical report outlines the methodologies we applied for the PRCV Challenge, focusing on cognition and decision-making in driving scenarios. We employed InternVL-2.0, a pioneering open-source multi-modal model, and enhanced it by refining both the model input and training methodologies. For the input data, we strategically concatenated and formatted the multi-view images. It is worth mentioning that we utilized the coordinates of the original images without transformation. In terms of model training, we initially pre-trained the model on publicly available autonomous driving scenario datasets to bolster its alignment capabilities of the challenge tasks, followed by fine-tuning on the DriveLM-nuscenes Dataset. During the fine-tuning phase, we innovatively modified the loss function to enhance the model's precision in predicting coordinate values. These approaches ensure that our model possesses advanced cognitive and decision-making capabilities in driving scenarios. Consequently, our model achieved a score of 0.6064, securing the first prize on the competition's final results.