 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVikingMem: A Memory Base Management System for Stateful LLM-based Applications
May 28, 2026Large Language Models have revolutionized interactive applications; however, their finite context windows pose a critical data management challenge for maintaining stateful, long-term interactions. Existing memory approaches often rely on simplistic extraction methods that lead to incomplete memories or use rigid, single-purpose memory extraction prompts tailored to a single use case, such as chatbots. Consequently, they lack generalizability and perform poorly across diverse downstream tasks. To bridge this gap, we introduce the Memory Base, a novel data management paradigm for managing the persistent state of long-term interactions. It is characterized by three core principles: selective extraction of high-value memories from raw information streams; inherent statefulness and evolution, where memory content is progressively summarized, corrected, and temporally weighted to prioritize recent interactions; and a generalizable abstraction paradigm designed for robust transferability across diverse applications, including education, recommendation, and agent memory. Building on this foundation, we present VikingMem, an end-to-end Memory Base Management System implemented on the VikingDB vector engine. VikingMem materializes this paradigm through interconnected event and entity abstractions. It features event-centric memory extraction to selectively handle complex information streams, while entities are dynamically updated by events to achieve stateful evolution. Using temporal compression via a topic-wise timeline and time-weighted recall, the system progressively produces high-level summary memories, prioritizes recent items, and compresses and fades older ones. Extensive evaluations on long-term memory benchmarks demonstrate that VikingMem outperformes baselines by up to 30% in memory retrieval effectiveness while maintaining the low latency essential for interactive applications.
Hierarchical Visual Agent: Managing Contexts in Joint Image-Text Space for Advanced Chart Reasoning
May 05, 2026Advanced chart question answering requires both precise perception of small visual elements and multi-step reasoning across several subplots. While existing MLLMs are strong at understanding single plots, they often struggle with multi-step reasoning across multiple subplots. We propose HierVA, a hierarchical visual agent framework for chart reasoning that iteratively constructs and updates a working context in a joint image--text space. A high-level manager generates plans and maintains a compact context containing only key information, while specialized workers perform reasoning, gather evidence, and return results. In particular, the agent maintains separate visual and textual contexts, using a zoom-in tool to restrict the visual context. Experiments on the CharXiv reasoning subset demonstrate consistent improvements over strong multimodal baselines, and ablation studies verify that hierarchical architecture, scoped visual context, and distilled context contribute complementary gains.
STORM: End-to-End Referring Multi-Object Tracking in Videos
Apr 12, 2026Referring multi-object tracking (RMOT) is a task of associating all the objects in a video that semantically match with given textual queries or referring expressions. Existing RMOT approaches decompose object grounding and tracking into separated modules and exhibit limited performance due to the scarcity of training videos, ambiguous annotations, and restricted domains. In this work, we introduce STORM, an end-to-end MLLM that jointly performs grounding and tracking within a unified framework, eliminating external detectors and enabling coherent reasoning over appearance, motion, and language. To improve data efficiency, we propose a task-composition learning (TCL) strategy that decomposes RMOT into image grounding and object tracking, allowing STORM to leverage data-rich sub-tasks and learn structured spatial--temporal reasoning. We further construct STORM-Bench, a new RMOT dataset with accurate trajectories and diverse, unambiguous referring expressions generated through a bottom-up annotation pipeline. Extensive experiments show that STORM achieves state-of-the-art performance on image grounding, single-object tracking, and RMOT benchmarks, demonstrating strong generalization and robust spatial--temporal grounding in complex real-world scenarios. STORM-Bench is released at https://github.com/amazon-science/storm-referring-multi-object-grounding.
When Rules Fall Short: Agent-Driven Discovery of Emerging Content Issues in Short Video Platforms
Jan 14, 2026Trends on short-video platforms evolve at a rapid pace, with new content issues emerging every day that fall outside the coverage of existing annotation policies. However, traditional human-driven discovery of emerging issues is too slow, which leads to delayed updates of annotation policies and poses a major challenge for effective content governance. In this work, we propose an automatic issue discovery method based on multimodal LLM agents. Our approach automatically recalls short videos containing potential new issues and applies a two-stage clustering strategy to group them, with each cluster corresponding to a newly discovered issue. The agent then generates updated annotation policies from these clusters, thereby extending coverage to these emerging issues. Our agent has been deployed in the real system. Both offline and online experiments demonstrate that this agent-based method significantly improves the effectiveness of emerging-issue discovery (with an F1 score improvement of over 20%) and enhances the performance of subsequent issue governance (reducing the view count of problematic videos by approximately 15%). More importantly, compared to manual issue discovery, it greatly reduces time costs and substantially accelerates the iteration of annotation policies.
PosBridge: Multi-View Positional Embedding Transplant for Identity-Aware Image Editing
Aug 24, 2025Localized subject-driven image editing aims to seamlessly integrate user-specified objects into target scenes. As generative models continue to scale, training becomes increasingly costly in terms of memory and computation, highlighting the need for training-free and scalable editing frameworks.To this end, we propose PosBridge an efficient and flexible framework for inserting custom objects. A key component of our method is positional embedding transplant, which guides the diffusion model to faithfully replicate the structural characteristics of reference objects.Meanwhile, we introduce the Corner Centered Layout, which concatenates reference images and the background image as input to the FLUX.1-Fill model. During progressive denoising, positional embedding transplant is applied to guide the noise distribution in the target region toward that of the reference object. In this way, Corner Centered Layout effectively directs the FLUX.1-Fill model to synthesize identity-consistent content at the desired location. Extensive experiments demonstrate that PosBridge outperforms mainstream baselines in structural consistency, appearance fidelity, and computational efficiency, showcasing its practical value and potential for broad adoption.
MMMG: A Massive, Multidisciplinary, Multi-Tier Generation Benchmark for Text-to-Image Reasoning
Jun 12, 2025In this paper, we introduce knowledge image generation as a new task, alongside the Massive Multi-Discipline Multi-Tier Knowledge-Image Generation Benchmark (MMMG) to probe the reasoning capability of image generation models. Knowledge images have been central to human civilization and to the mechanisms of human learning--a fact underscored by dual-coding theory and the picture-superiority effect. Generating such images is challenging, demanding multimodal reasoning that fuses world knowledge with pixel-level grounding into clear explanatory visuals. To enable comprehensive evaluation, MMMG offers 4,456 expert-validated (knowledge) image-prompt pairs spanning 10 disciplines, 6 educational levels, and diverse knowledge formats such as charts, diagrams, and mind maps. To eliminate confounding complexity during evaluation, we adopt a unified Knowledge Graph (KG) representation. Each KG explicitly delineates a target image's core entities and their dependencies. We further introduce MMMG-Score to evaluate generated knowledge images. This metric combines factual fidelity, measured by graph-edit distance between KGs, with visual clarity assessment. Comprehensive evaluations of 16 state-of-the-art text-to-image generation models expose serious reasoning deficits--low entity fidelity, weak relations, and clutter--with GPT-4o achieving an MMMG-Score of only 50.20, underscoring the benchmark's difficulty. To spur further progress, we release FLUX-Reason (MMMG-Score of 34.45), an effective and open baseline that combines a reasoning LLM with diffusion models and is trained on 16,000 curated knowledge image-prompt pairs.
PrismLayers: Open Data for High-Quality Multi-Layer Transparent Image Generative Models
May 28, 2025Generating high-quality, multi-layer transparent images from text prompts can unlock a new level of creative control, allowing users to edit each layer as effortlessly as editing text outputs from LLMs. However, the development of multi-layer generative models lags behind that of conventional text-to-image models due to the absence of a large, high-quality corpus of multi-layer transparent data. In this paper, we address this fundamental challenge by: (i) releasing the first open, ultra-high-fidelity PrismLayers (PrismLayersPro) dataset of 200K (20K) multilayer transparent images with accurate alpha mattes, (ii) introducing a trainingfree synthesis pipeline that generates such data on demand using off-the-shelf diffusion models, and (iii) delivering a strong, open-source multi-layer generation model, ART+, which matches the aesthetics of modern text-to-image generation models. The key technical contributions include: LayerFLUX, which excels at generating high-quality single transparent layers with accurate alpha mattes, and MultiLayerFLUX, which composes multiple LayerFLUX outputs into complete images, guided by human-annotated semantic layout. To ensure higher quality, we apply a rigorous filtering stage to remove artifacts and semantic mismatches, followed by human selection. Fine-tuning the state-of-the-art ART model on our synthetic PrismLayersPro yields ART+, which outperforms the original ART in 60% of head-to-head user study comparisons and even matches the visual quality of images generated by the FLUX.1-[dev] model. We anticipate that our work will establish a solid dataset foundation for the multi-layer transparent image generation task, enabling research and applications that require precise, editable, and visually compelling layered imagery.
Transformation vs Tradition: Artificial General Intelligence (AGI) for Arts and Humanities
Oct 30, 2023
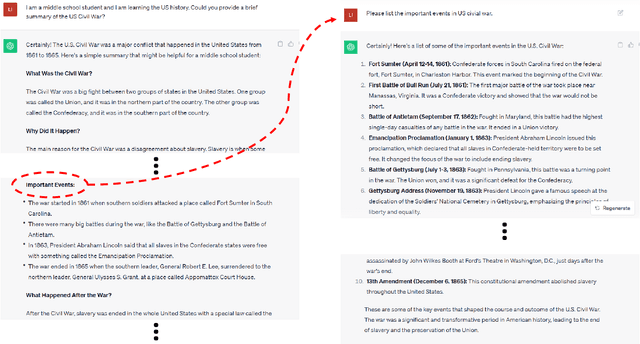
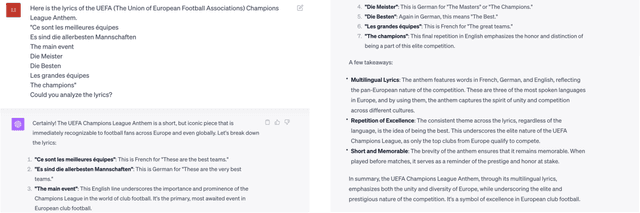
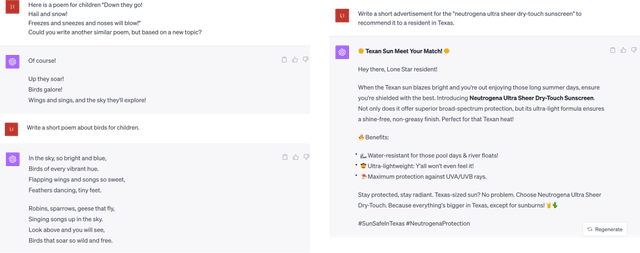
Recent advances in artificial general intelligence (AGI), particularly large language models and creative image generation systems have demonstrated impressive capabilities on diverse tasks spanning the arts and humanities. However, the swift evolution of AGI has also raised critical questions about its responsible deployment in these culturally significant domains traditionally seen as profoundly human. This paper provides a comprehensive analysis of the applications and implications of AGI for text, graphics, audio, and video pertaining to arts and the humanities. We survey cutting-edge systems and their usage in areas ranging from poetry to history, marketing to film, and communication to classical art. We outline substantial concerns pertaining to factuality, toxicity, biases, and public safety in AGI systems, and propose mitigation strategies. The paper argues for multi-stakeholder collaboration to ensure AGI promotes creativity, knowledge, and cultural values without undermining truth or human dignity. Our timely contribution summarizes a rapidly developing field, highlighting promising directions while advocating for responsible progress centering on human flourishing. The analysis lays the groundwork for further research on aligning AGI's technological capacities with enduring social goods.
ATM: Action Temporality Modeling for Video Question Answering
Sep 05, 2023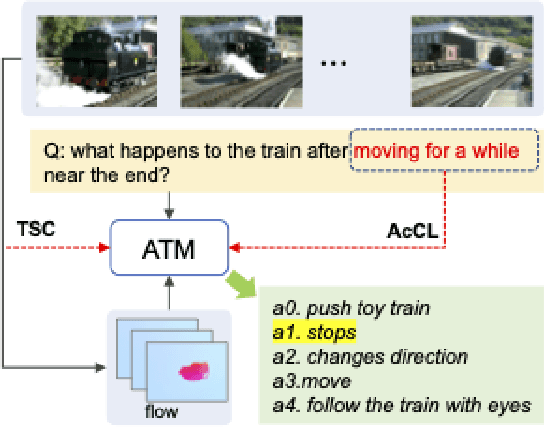
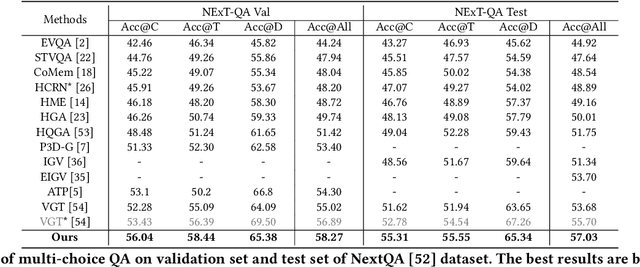
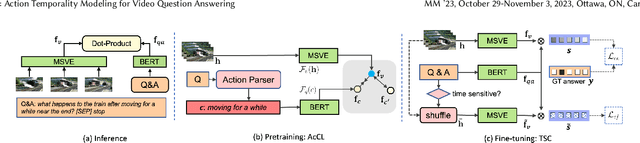
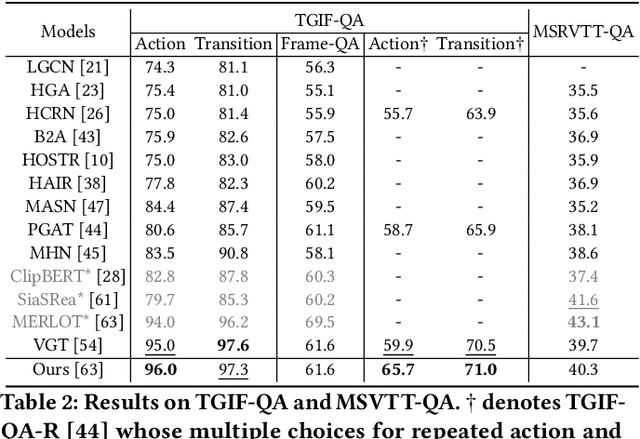
Despite significant progress in video question answering (VideoQA), existing methods fall short of questions that require causal/temporal reasoning across frames. This can be attributed to imprecise motion representations. We introduce Action Temporality Modeling (ATM) for temporality reasoning via three-fold uniqueness: (1) rethinking the optical flow and realizing that optical flow is effective in capturing the long horizon temporality reasoning; (2) training the visual-text embedding by contrastive learning in an action-centric manner, leading to better action representations in both vision and text modalities; and (3) preventing the model from answering the question given the shuffled video in the fine-tuning stage, to avoid spurious correlation between appearance and motion and hence ensure faithful temporality reasoning. In the experiments, we show that ATM outperforms previous approaches in terms of the accuracy on multiple VideoQAs and exhibits better true temporality reasoning ability.
Defending Adversarial Patches via Joint Region Localizing and Inpainting
Jul 26, 2023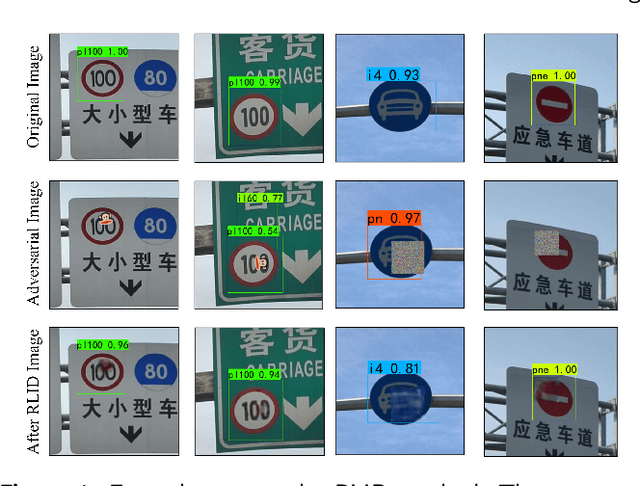
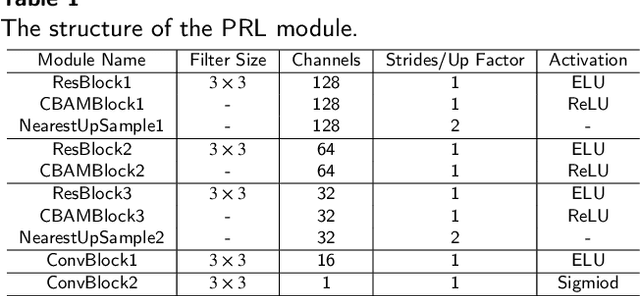
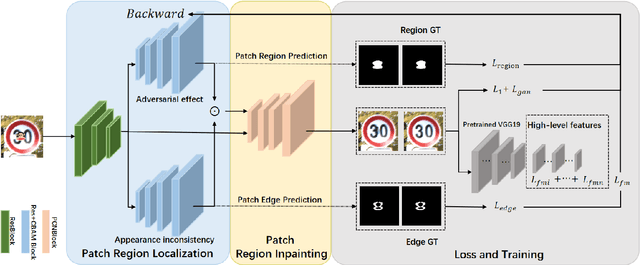
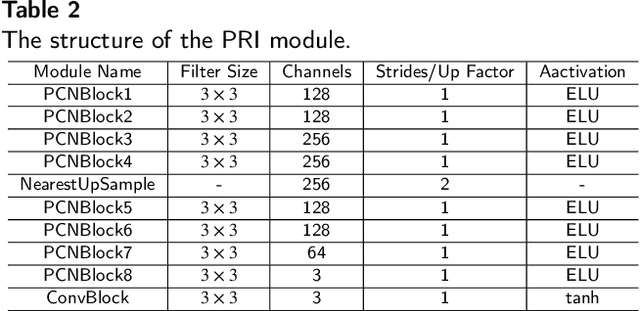
Deep neural networks are successfully used in various applications, but show their vulnerability to adversarial examples. With the development of adversarial patches, the feasibility of attacks in physical scenes increases, and the defenses against patch attacks are urgently needed. However, defending such adversarial patch attacks is still an unsolved problem. In this paper, we analyse the properties of adversarial patches, and find that: on the one hand, adversarial patches will lead to the appearance or contextual inconsistency in the target objects; on the other hand, the patch region will show abnormal changes on the high-level feature maps of the objects extracted by a backbone network. Considering the above two points, we propose a novel defense method based on a ``localizing and inpainting" mechanism to pre-process the input examples. Specifically, we design an unified framework, where the ``localizing" sub-network utilizes a two-branch structure to represent the above two aspects to accurately detect the adversarial patch region in the image. For the ``inpainting" sub-network, it utilizes the surrounding contextual cues to recover the original content covered by the adversarial patch. The quality of inpainted images is also evaluated by measuring the appearance consistency and the effects of adversarial attacks. These two sub-networks are then jointly trained via an iterative optimization manner. In this way, the ``localizing" and ``inpainting" modules can interact closely with each other, and thus learn a better solution. A series of experiments versus traffic sign classification and detection tasks are conducted to defend against various adversarial patch attacks.