 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Spatial-Temporal Focal Adapter with SSM for Temporal Action Detection
Apr 10, 2026Temporal human action detection aims to identify and localize action segments within untrimmed videos, serving as a pivotal task in video understanding. Despite the progress achieved by prior architectures like CNN and Transformer models, these continue to struggle with feature redundancy and degraded global dependency modeling capabilities when applied to long video sequences. These limitations severely constrain their scalability in real-world video analysis. State Space Models (SSMs) offer a promising alternative with linear long-term modeling and robust global temporal reasoning capabilities. Rethinking the application of SSMs in temporal modeling, this research constructs a novel framework for video human action detection. Specifically, we introduce the Efficient Spatial-Temporal Focal (ESTF) Adapter into the pre-trained layers. This module integrates the advantages of our proposed Temporal Boundary-aware SSM(TB-SSM) for temporal feature modeling with efficient processing of spatial features. We perform comprehensive and quantitative analyses across multiple benchmarks, comparing our proposed method against previous SSM-based and other structural methods. Extensive experiments demonstrate that our improved strategy significantly enhances both localization performance and robustness, validating the effectiveness of our proposed method.
PosBridge: Multi-View Positional Embedding Transplant for Identity-Aware Image Editing
Aug 24, 2025Localized subject-driven image editing aims to seamlessly integrate user-specified objects into target scenes. As generative models continue to scale, training becomes increasingly costly in terms of memory and computation, highlighting the need for training-free and scalable editing frameworks.To this end, we propose PosBridge an efficient and flexible framework for inserting custom objects. A key component of our method is positional embedding transplant, which guides the diffusion model to faithfully replicate the structural characteristics of reference objects.Meanwhile, we introduce the Corner Centered Layout, which concatenates reference images and the background image as input to the FLUX.1-Fill model. During progressive denoising, positional embedding transplant is applied to guide the noise distribution in the target region toward that of the reference object. In this way, Corner Centered Layout effectively directs the FLUX.1-Fill model to synthesize identity-consistent content at the desired location. Extensive experiments demonstrate that PosBridge outperforms mainstream baselines in structural consistency, appearance fidelity, and computational efficiency, showcasing its practical value and potential for broad adoption.
PrismLayers: Open Data for High-Quality Multi-Layer Transparent Image Generative Models
May 28, 2025Generating high-quality, multi-layer transparent images from text prompts can unlock a new level of creative control, allowing users to edit each layer as effortlessly as editing text outputs from LLMs. However, the development of multi-layer generative models lags behind that of conventional text-to-image models due to the absence of a large, high-quality corpus of multi-layer transparent data. In this paper, we address this fundamental challenge by: (i) releasing the first open, ultra-high-fidelity PrismLayers (PrismLayersPro) dataset of 200K (20K) multilayer transparent images with accurate alpha mattes, (ii) introducing a trainingfree synthesis pipeline that generates such data on demand using off-the-shelf diffusion models, and (iii) delivering a strong, open-source multi-layer generation model, ART+, which matches the aesthetics of modern text-to-image generation models. The key technical contributions include: LayerFLUX, which excels at generating high-quality single transparent layers with accurate alpha mattes, and MultiLayerFLUX, which composes multiple LayerFLUX outputs into complete images, guided by human-annotated semantic layout. To ensure higher quality, we apply a rigorous filtering stage to remove artifacts and semantic mismatches, followed by human selection. Fine-tuning the state-of-the-art ART model on our synthetic PrismLayersPro yields ART+, which outperforms the original ART in 60% of head-to-head user study comparisons and even matches the visual quality of images generated by the FLUX.1-[dev] model. We anticipate that our work will establish a solid dataset foundation for the multi-layer transparent image generation task, enabling research and applications that require precise, editable, and visually compelling layered imagery.
Focusing on what to decode and what to train: Efficient Training with HOI Split Decoders and Specific Target Guided DeNoising
Jul 05, 2023Recent one-stage transformer-based methods achieve notable gains in the Human-object Interaction Detection (HOI) task by leveraging the detection of DETR. However, the current methods redirect the detection target of the object decoder, and the box target is not explicitly separated from the query embeddings, which leads to long and hard training. Furthermore, matching the predicted HOI instances with the ground-truth is more challenging than object detection, simply adapting training strategies from the object detection makes the training more difficult. To clear the ambiguity between human and object detection and share the prediction burden, we propose a novel one-stage framework (SOV), which consists of a subject decoder, an object decoder, and a verb decoder. Moreover, we propose a novel Specific Target Guided (STG) DeNoising strategy, which leverages learnable object and verb label embeddings to guide the training and accelerates the training convergence. In addition, for the inference part, the label-specific information is directly fed into the decoders by initializing the query embeddings from the learnable label embeddings. Without additional features or prior language knowledge, our method (SOV-STG) achieves higher accuracy than the state-of-the-art method in one-third of training epochs. The code is available at \url{https://github.com/cjw2021/SOV-STG}.
Transformer-based Cross-Modal Recipe Embeddings with Large Batch Training
May 10, 2022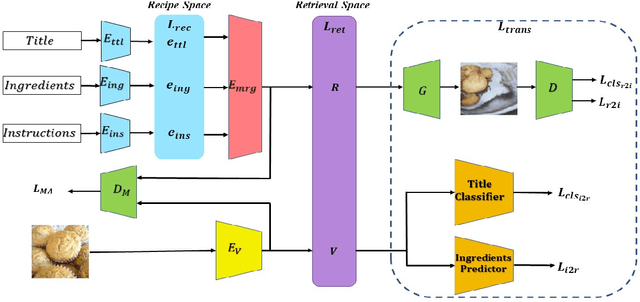
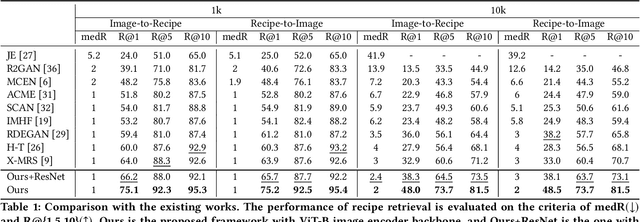
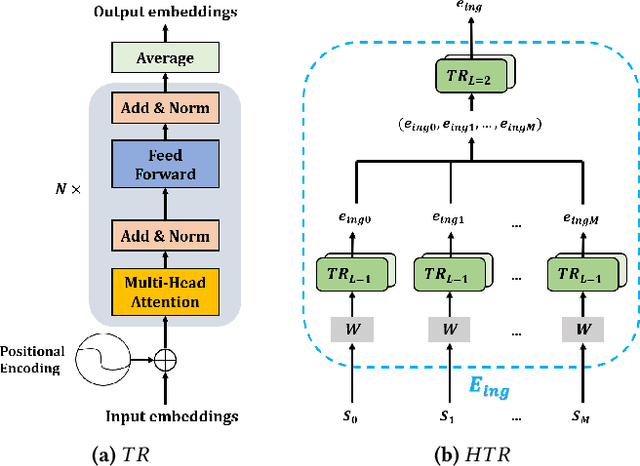
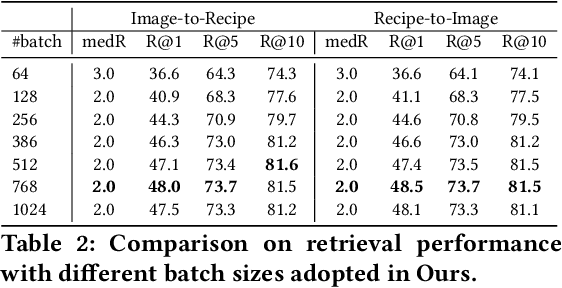
In this paper, we present a cross-modal recipe retrieval framework, Transformer-based Network for Large Batch Training (TNLBT), which is inspired by ACME~(Adversarial Cross-Modal Embedding) and H-T~(Hierarchical Transformer). TNLBT aims to accomplish retrieval tasks while generating images from recipe embeddings. We apply the Hierarchical Transformer-based recipe text encoder, the Vision Transformer~(ViT)-based recipe image encoder, and an adversarial network architecture to enable better cross-modal embedding learning for recipe texts and images. In addition, we use self-supervised learning to exploit the rich information in the recipe texts having no corresponding images. Since contrastive learning could benefit from a larger batch size according to the recent literature on self-supervised learning, we adopt a large batch size during training and have validated its effectiveness. In the experiments, the proposed framework significantly outperformed the current state-of-the-art frameworks in both cross-modal recipe retrieval and image generation tasks on the benchmark Recipe1M. This is the first work which confirmed the effectiveness of large batch training on cross-modal recipe embeddings.
QAHOI: Query-Based Anchors for Human-Object Interaction Detection
Dec 16, 2021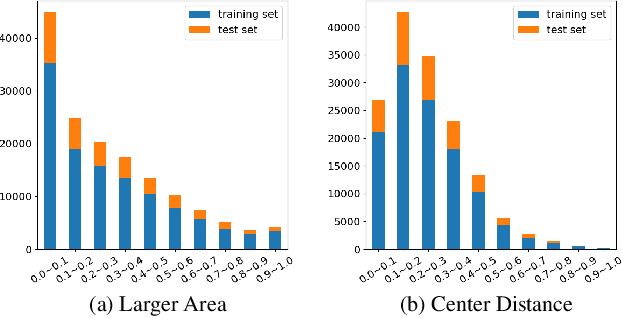
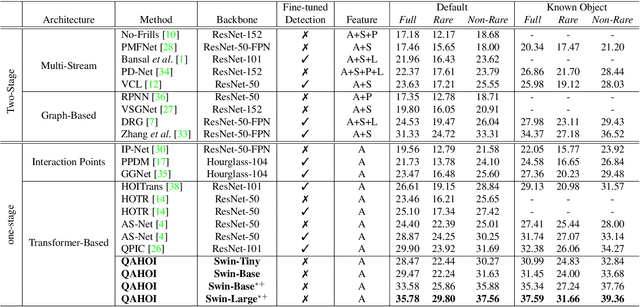
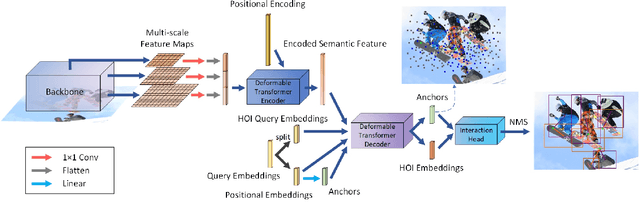
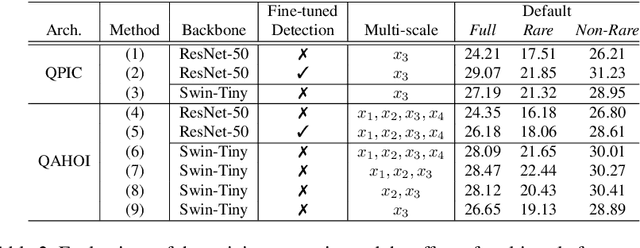
Human-object interaction (HOI) detection as a downstream of object detection tasks requires localizing pairs of humans and objects and extracting the semantic relationships between humans and objects from an image. Recently, one-stage approaches have become a new trend for this task due to their high efficiency. However, these approaches focus on detecting possible interaction points or filtering human-object pairs, ignoring the variability in the location and size of different objects at spatial scales. To address this problem, we propose a transformer-based method, QAHOI (Query-Based Anchors for Human-Object Interaction detection), which leverages a multi-scale architecture to extract features from different spatial scales and uses query-based anchors to predict all the elements of an HOI instance. We further investigate that a powerful backbone significantly increases accuracy for QAHOI, and QAHOI with a transformer-based backbone outperforms recent state-of-the-art methods by large margins on the HICO-DET benchmark. The source code is available at $\href{https://github.com/cjw2021/QAHOI}{\text{this https URL}}$.
IPN Hand: A Video Dataset and Benchmark for Real-Time Continuous Hand Gesture Recognition
Apr 20, 2020


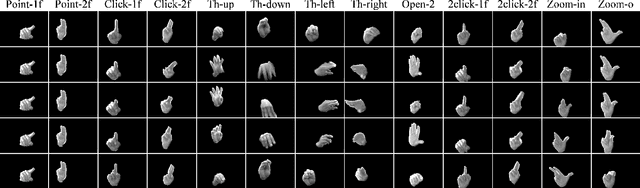
In the research community of continuous hand gesture recognition (HGR), the current publicly available datasets lack real-world elements needed to build responsive and efficient HGR systems. In this paper, we introduce a new benchmark dataset named IPN Hand with sufficient size, variation, and real-world elements able to train and evaluate deep neural networks. This dataset contains more than 4 000 gesture samples and 800 000 RGB frames from 50 distinct subjects. We design 13 different static and dynamic gestures focused on interaction with touchless screens. We especially consider the scenario when continuous gestures are performed without transition states, and when subjects perform natural movements with their hands as non-gesture actions. Gestures were collected from about 30 diverse scenes, with real-world variation in background and illumination. With our dataset, the performance of three 3D-CNN models is evaluated on the tasks of isolated and continuous real-time HGR. Furthermore, we analyze the possibility of increasing the recognition accuracy by adding multiple modalities derived from RGB frames, i.e., optical flow and semantic segmentation, while keeping the real-time performance of the 3D-CNN model. Our empirical study also provides a comparison with the publicly available nvGesture (NVIDIA) dataset. The experimental results show that the state-of-the-art ResNext-101 model decreases about 30% accuracy when using our real-world dataset, demonstrating that the IPN Hand dataset can be used as a benchmark, and may help the community to step forward in the continuous HGR. Our dataset and pre-trained models used in the evaluation are publicly available at https://github.com/GibranBenitez/IPN-hand.
Iconify: Converting Photographs into Icons
Apr 07, 2020
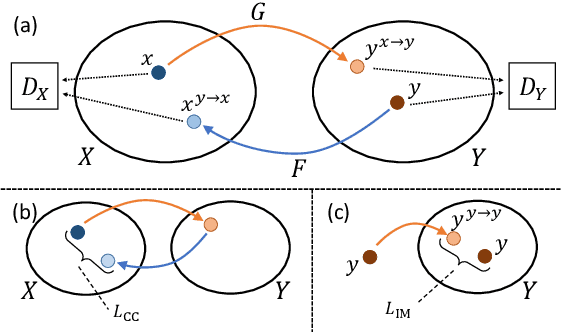
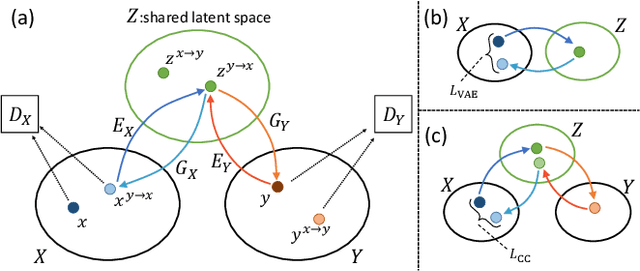

In this paper, we tackle a challenging domain conversion task between photo and icon images. Although icons often originate from real object images (i.e., photographs), severe abstractions and simplifications are applied to generate icon images by professional graphic designers. Moreover, there is no one-to-one correspondence between the two domains, for this reason we cannot use it as the ground-truth for learning a direct conversion function. Since generative adversarial networks (GAN) can undertake the problem of domain conversion without any correspondence, we test CycleGAN and UNIT to generate icons from objects segmented from photo images. Our experiments with several image datasets prove that CycleGAN learns sufficient abstraction and simplification ability to generate icon-like images.
Self-Supervised Difference Detection for Weakly-Supervised Semantic Segmentation
Nov 12, 2019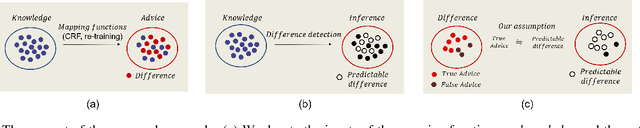

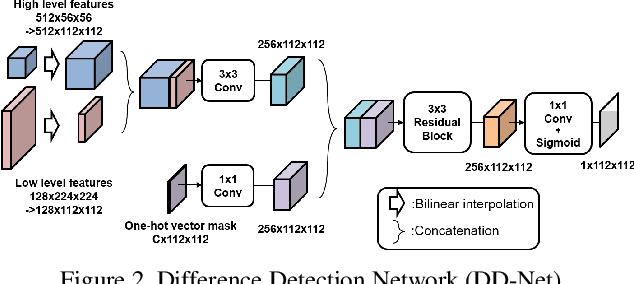
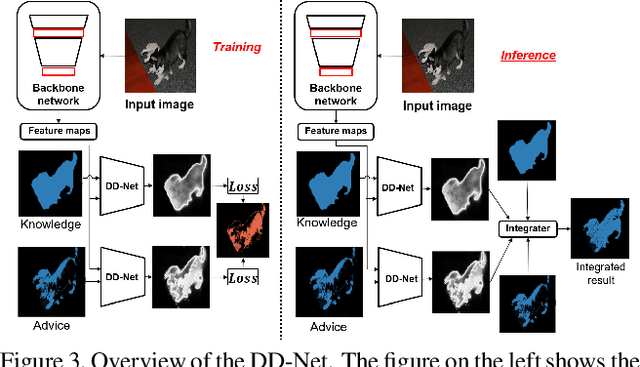
To minimize the annotation costs associated with the training of semantic segmentation models, researchers have extensively investigated weakly-supervised segmentation approaches. In the current weakly-supervised segmentation methods, the most widely adopted approach is based on visualization. However, the visualization results are not generally equal to semantic segmentation. Therefore, to perform accurate semantic segmentation under the weakly supervised condition, it is necessary to consider the mapping functions that convert the visualization results into semantic segmentation. For such mapping functions, the conditional random field and iterative re-training using the outputs of a segmentation model are usually used. However, these methods do not always guarantee improvements in accuracy; therefore, if we apply these mapping functions iteratively multiple times, eventually the accuracy will not improve or will decrease. In this paper, to make the most of such mapping functions, we assume that the results of the mapping function include noise, and we improve the accuracy by removing noise. To achieve our aim, we propose the self-supervised difference detection module, which estimates noise from the results of the mapping functions by predicting the difference between the segmentation masks before and after the mapping. We verified the effectiveness of the proposed method by performing experiments on the PASCAL Visual Object Classes 2012 dataset, and we achieved 64.9\% in the val set and 65.5\% in the test set. Both of the results become new state-of-the-art under the same setting of weakly supervised semantic segmentation.
An Integration of Bottom-up and Top-Down Salient Cues on RGB-D Data: Saliency from Objectness vs. Non-Objectness
Jul 04, 2018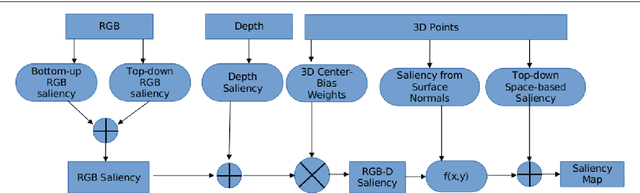


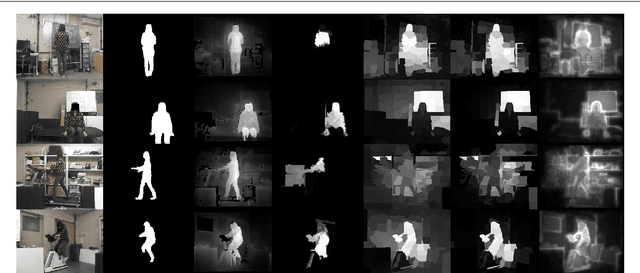
Bottom-up and top-down visual cues are two types of information that helps the visual saliency models. These salient cues can be from spatial distributions of the features (space-based saliency) or contextual / task-dependent features (object based saliency). Saliency models generally incorporate salient cues either in bottom-up or top-down norm separately. In this work, we combine bottom-up and top-down cues from both space and object based salient features on RGB-D data. In addition, we also investigated the ability of various pre-trained convolutional neural networks for extracting top-down saliency on color images based on the object dependent feature activation. We demonstrate that combining salient features from color and dept through bottom-up and top-down methods gives significant improvement on the salient object detection with space based and object based salient cues. RGB-D saliency integration framework yields promising results compared with the several state-of-the-art-models.
* 9 pages, 3 figures, 3 tables, This work includes the accepted version content of the paper published in journal of Signal Image and Video Processing (SIViP, Springer), Vol. 12, Issue 2, pp 307-314, Feb 2018 (DOI: https://doi.org/10.1007/s11760-017-1159-7)