 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogical Bias Learning for Object Relation Prediction
Oct 01, 2023Scene graph generation (SGG) aims to automatically map an image into a semantic structural graph for better scene understanding. It has attracted significant attention for its ability to provide object and relation information, enabling graph reasoning for downstream tasks. However, it faces severe limitations in practice due to the biased data and training method. In this paper, we present a more rational and effective strategy based on causal inference for object relation prediction. To further evaluate the superiority of our strategy, we propose an object enhancement module to conduct ablation studies. Experimental results on the Visual Gnome 150 (VG-150) dataset demonstrate the effectiveness of our proposed method. These contributions can provide great potential for foundation models for decision-making.
Few shot font generation via transferring similarity guided global style and quantization local style
Sep 14, 2023Automatic few-shot font generation (AFFG), aiming at generating new fonts with only a few glyph references, reduces the labor cost of manually designing fonts. However, the traditional AFFG paradigm of style-content disentanglement cannot capture the diverse local details of different fonts. So, many component-based approaches are proposed to tackle this problem. The issue with component-based approaches is that they usually require special pre-defined glyph components, e.g., strokes and radicals, which is infeasible for AFFG of different languages. In this paper, we present a novel font generation approach by aggregating styles from character similarity-guided global features and stylized component-level representations. We calculate the similarity scores of the target character and the referenced samples by measuring the distance along the corresponding channels from the content features, and assigning them as the weights for aggregating the global style features. To better capture the local styles, a cross-attention-based style transfer module is adopted to transfer the styles of reference glyphs to the components, where the components are self-learned discrete latent codes through vector quantization without manual definition. With these designs, our AFFG method could obtain a complete set of component-level style representations, and also control the global glyph characteristics. The experimental results reflect the effectiveness and generalization of the proposed method on different linguistic scripts, and also show its superiority when compared with other state-of-the-art methods. The source code can be found at https://github.com/awei669/VQ-Font.
FETNet: Feature Erasing and Transferring Network for Scene Text Removal
Jun 16, 2023



The scene text removal (STR) task aims to remove text regions and recover the background smoothly in images for private information protection. Most existing STR methods adopt encoder-decoder-based CNNs, with direct copies of the features in the skip connections. However, the encoded features contain both text texture and structure information. The insufficient utilization of text features hampers the performance of background reconstruction in text removal regions. To tackle these problems, we propose a novel Feature Erasing and Transferring (FET) mechanism to reconfigure the encoded features for STR in this paper. In FET, a Feature Erasing Module (FEM) is designed to erase text features. An attention module is responsible for generating the feature similarity guidance. The Feature Transferring Module (FTM) is introduced to transfer the corresponding features in different layers based on the attention guidance. With this mechanism, a one-stage, end-to-end trainable network called FETNet is constructed for scene text removal. In addition, to facilitate research on both scene text removal and segmentation tasks, we introduce a novel dataset, Flickr-ST, with multi-category annotations. A sufficient number of experiments and ablation studies are conducted on the public datasets and Flickr-ST. Our proposed method achieves state-of-the-art performance using most metrics, with remarkably higher quality scene text removal results. The source code of our work is available at: \href{https://github.com/GuangtaoLyu/FETNet}{https://github.com/GuangtaoLyu/FETNet.
* Accepted by Pattern Recognition 2023
PSSTRNet: Progressive Segmentation-guided Scene Text Removal Network
Jun 13, 2023Scene text removal (STR) is a challenging task due to the complex text fonts, colors, sizes, and background textures in scene images. However, most previous methods learn both text location and background inpainting implicitly within a single network, which weakens the text localization mechanism and makes a lossy background. To tackle these problems, we propose a simple Progressive Segmentation-guided Scene Text Removal Network(PSSTRNet) to remove the text in the image iteratively. It contains two decoder branches, a text segmentation branch, and a text removal branch, with a shared encoder. The text segmentation branch generates text mask maps as the guidance for the regional removal branch. In each iteration, the original image, previous text removal result, and text mask are input to the network to extract the rest part of the text segments and cleaner text removal result. To get a more accurate text mask map, an update module is developed to merge the mask map in the current and previous stages. The final text removal result is obtained by adaptive fusion of results from all previous stages. A sufficient number of experiments and ablation studies conducted on the real and synthetic public datasets demonstrate our proposed method achieves state-of-the-art performance. The source code of our work is available at: \href{https://github.com/GuangtaoLyu/PSSTRNet}{https://github.com/GuangtaoLyu/PSSTRNet.}
* Accepted by ICME2022
Scene Text Detection with Selected Anchor
Aug 19, 2020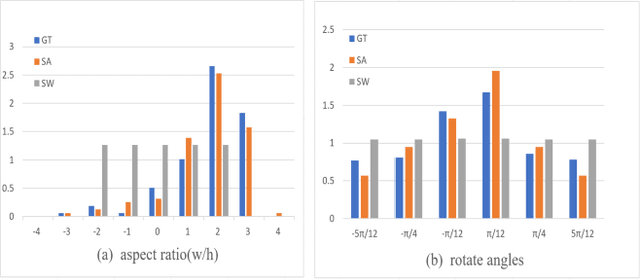

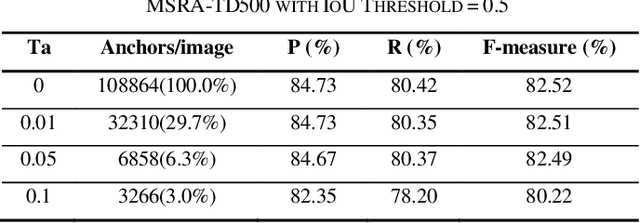
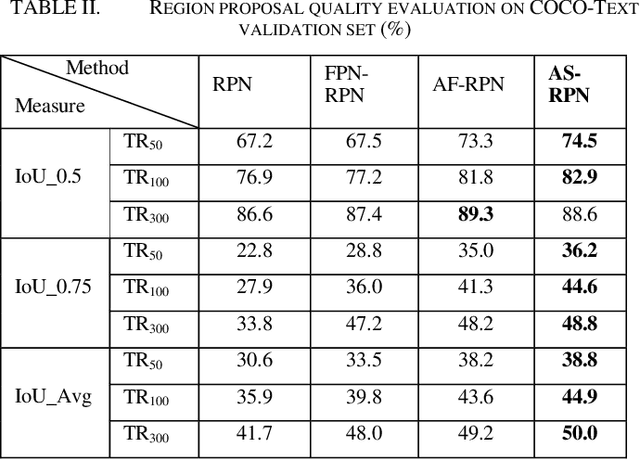
Object proposal technique with dense anchoring scheme for scene text detection were applied frequently to achieve high recall. It results in the significant improvement in accuracy but waste of computational searching, regression and classification. In this paper, we propose an anchor selection-based region proposal network (AS-RPN) using effective selected anchors instead of dense anchors to extract text proposals. The center, scales, aspect ratios and orientations of anchors are learnable instead of fixing, which leads to high recall and greatly reduced numbers of anchors. By replacing the anchor-based RPN in Faster RCNN, the AS-RPN-based Faster RCNN can achieve comparable performance with previous state-of-the-art text detecting approaches on standard benchmarks, including COCO-Text, ICDAR2013, ICDAR2015 and MSRA-TD500 when using single-scale and single model (ResNet50) testing only.
Scene Text Magnifier
Jul 05, 2019

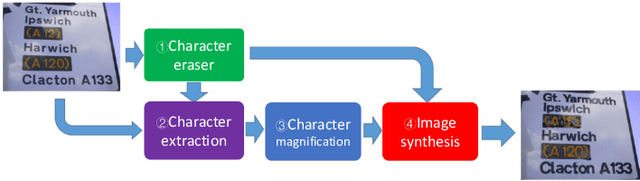
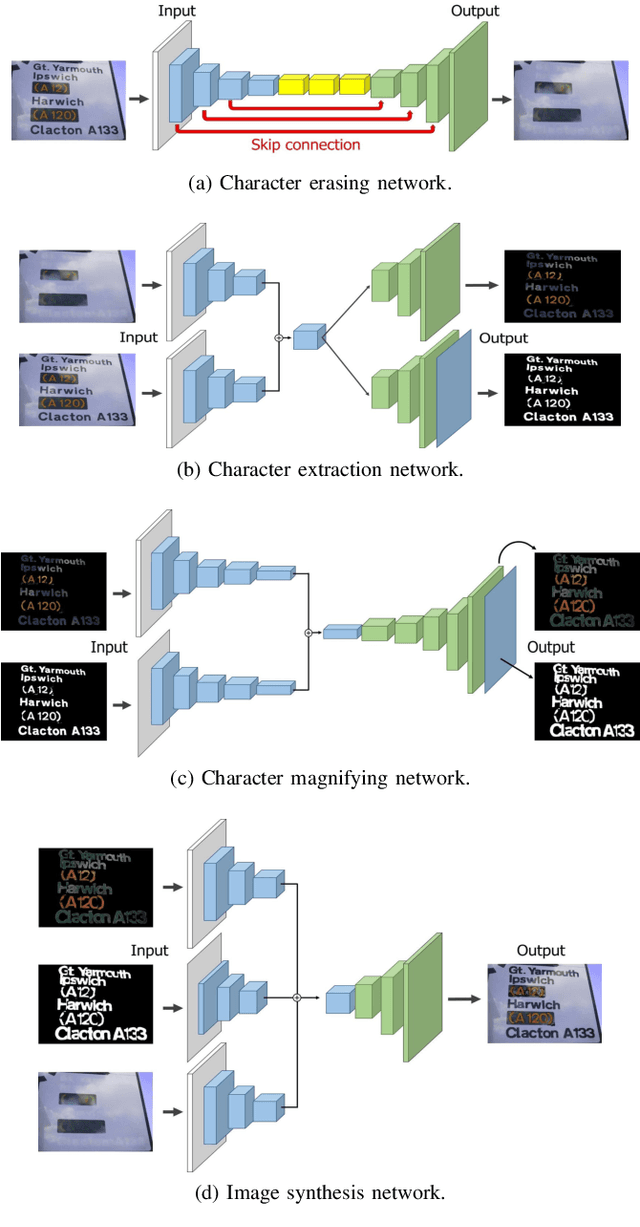
Scene text magnifier aims to magnify text in natural scene images without recognition. It could help the special groups, who have myopia or dyslexia to better understand the scene. In this paper, we design the scene text magnifier through interacted four CNN-based networks: character erasing, character extraction, character magnify, and image synthesis. The architecture of the networks are extended based on the hourglass encoder-decoders. It inputs the original scene text image and outputs the text magnified image while keeps the background unchange. Intermediately, we can get the side-output results of text erasing and text extraction. The four sub-networks are first trained independently and fine-tuned in end-to-end mode. The training samples for each stage are processed through a flow with original image and text annotation in ICDAR2013 and Flickr dataset as input, and corresponding text erased image, magnified text annotation, and text magnified scene image as output. To evaluate the performance of text magnifier, the Structural Similarity is used to measure the regional changes in each character region. The experimental results demonstrate our method can magnify scene text effectively without effecting the background.
Scene Text Eraser
May 08, 2017
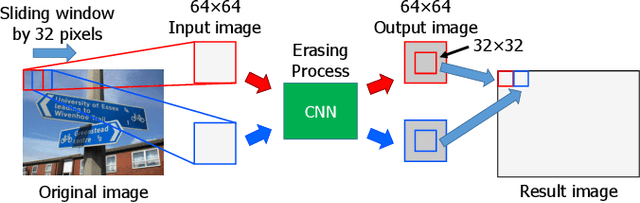
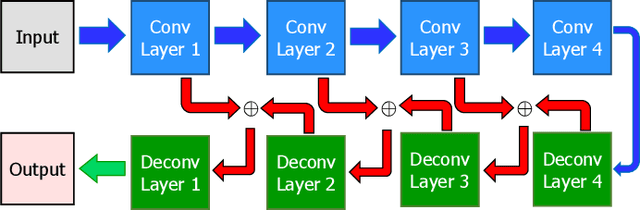

The character information in natural scene images contains various personal information, such as telephone numbers, home addresses, etc. It is a high risk of leakage the information if they are published. In this paper, we proposed a scene text erasing method to properly hide the information via an inpainting convolutional neural network (CNN) model. The input is a scene text image, and the output is expected to be text erased image with all the character regions filled up the colors of the surrounding background pixels. This work is accomplished by a CNN model through convolution to deconvolution with interconnection process. The training samples and the corresponding inpainting images are considered as teaching signals for training. To evaluate the text erasing performance, the output images are detected by a novel scene text detection method. Subsequently, the same measurement on text detection is utilized for testing the images in benchmark dataset ICDAR2013. Compared with direct text detection way, the scene text erasing process demonstrates a drastically decrease on the precision, recall and f-score. That proves the effectiveness of proposed method for erasing the text in natural scene images.