 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Text Magnifier
Paper and Code
Jul 05, 2019

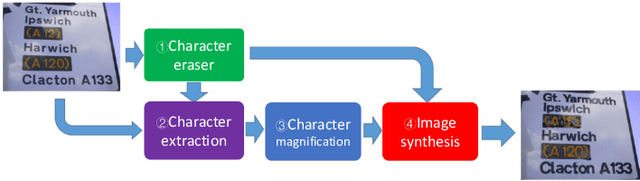
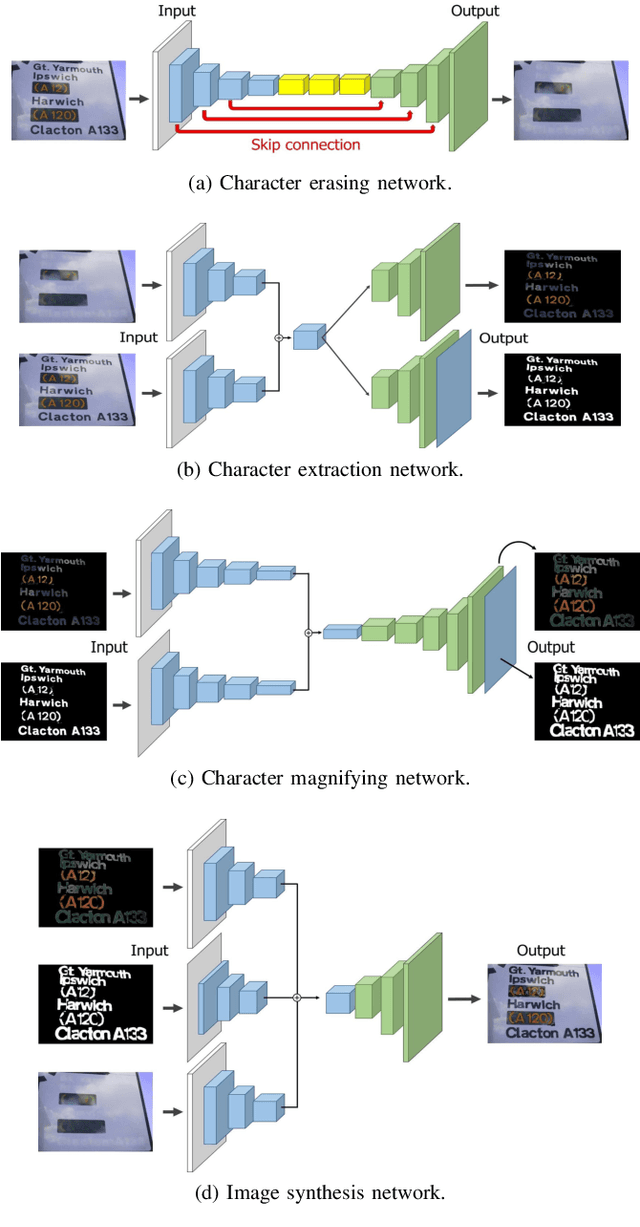
Scene text magnifier aims to magnify text in natural scene images without recognition. It could help the special groups, who have myopia or dyslexia to better understand the scene. In this paper, we design the scene text magnifier through interacted four CNN-based networks: character erasing, character extraction, character magnify, and image synthesis. The architecture of the networks are extended based on the hourglass encoder-decoders. It inputs the original scene text image and outputs the text magnified image while keeps the background unchange. Intermediately, we can get the side-output results of text erasing and text extraction. The four sub-networks are first trained independently and fine-tuned in end-to-end mode. The training samples for each stage are processed through a flow with original image and text annotation in ICDAR2013 and Flickr dataset as input, and corresponding text erased image, magnified text annotation, and text magnified scene image as output. To evaluate the performance of text magnifier, the Structural Similarity is used to measure the regional changes in each character region. The experimental results demonstrate our method can magnify scene text effectively without effecting the background.