 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIMII DUE: Sound Dataset for Malfunctioning Industrial Machine Investigation and Inspection with Domain Shifts due to Changes in Operational and Environmental Conditions
May 07, 2021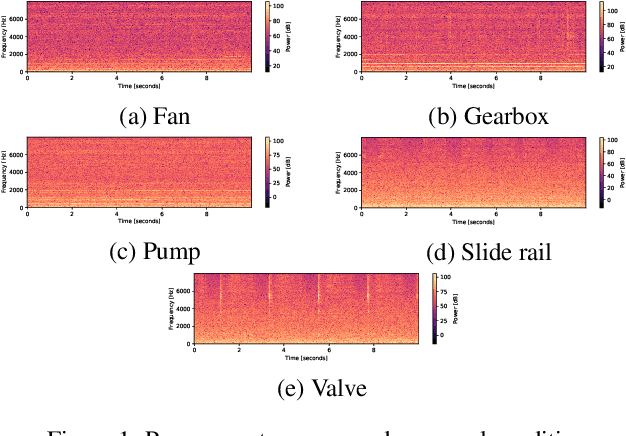
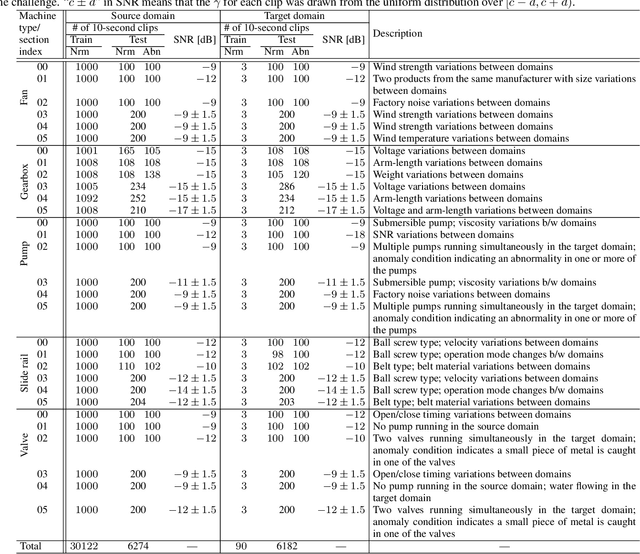
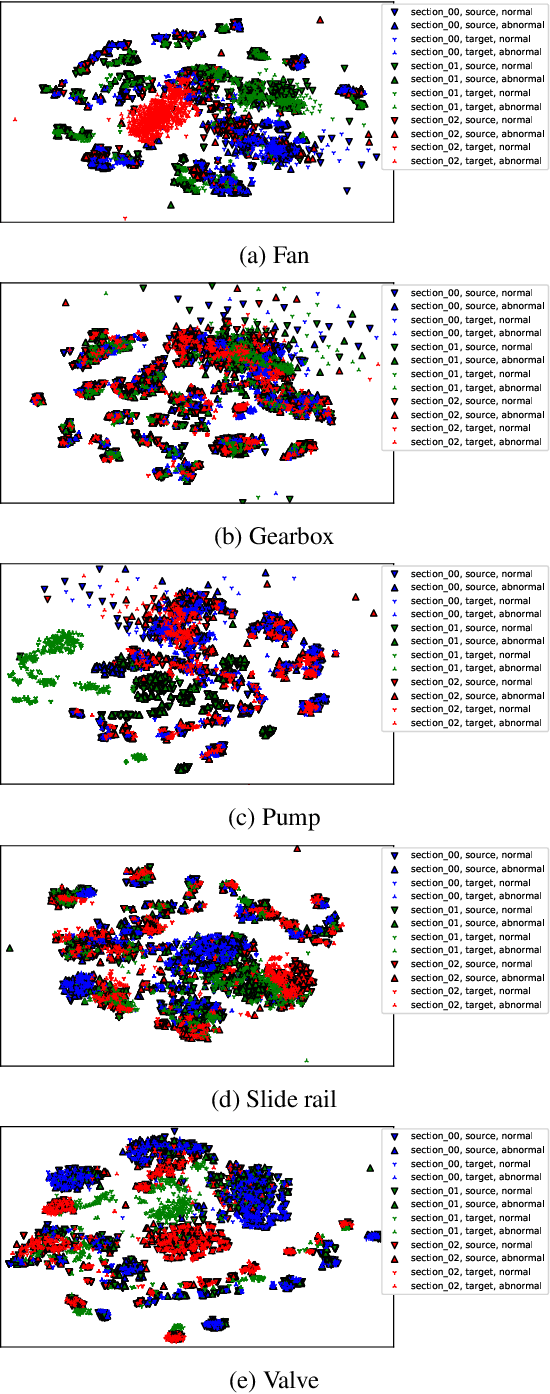

In this paper, we introduce a new dataset for malfunctioning industrial machine investigation and inspection with domain shifts due to changes in operational and environmental conditions (MIMII DUE). Conventional methods for anomalous sound detection face challenges in practice because the distribution of features changes between the training and operational phases (called domain shift) due to some real-world factors. To check the robustness against domain shifts, we need a dataset with domain shifts, but such a dataset does not exist so far. The new dataset consists of normal and abnormal operating sounds of industrial machines of five different types under two different operational/environmental conditions (source domain and target domain) independent of normal/abnormal, with domain shifts occurring between the two domains. Experimental results show significant performance differences between the source and target domains, and the dataset contains the domain shifts. These results indicate that the dataset will be helpful to check the robustness against domain shifts. The dataset is a subset of the dataset for DCASE 2021 Challenge Task 2 and freely available for download at https://zenodo.org/record/4740355
n-hot: Efficient bit-level sparsity for powers-of-two neural network quantization
Mar 22, 2021
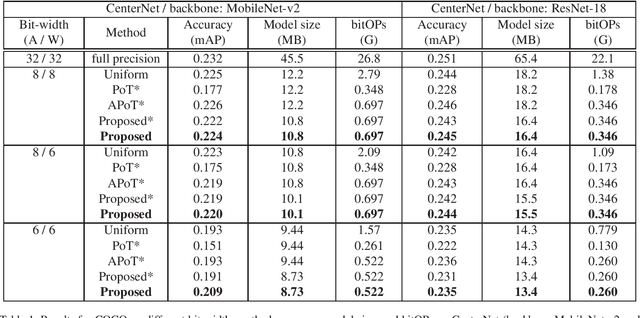
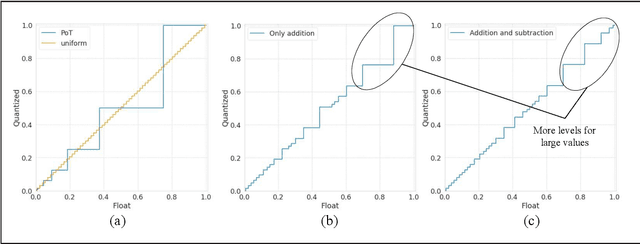
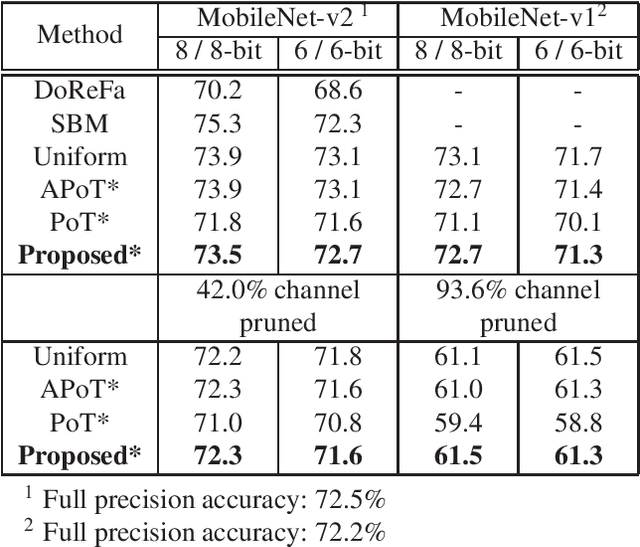
Powers-of-two (PoT) quantization reduces the number of bit operations of deep neural networks on resource-constrained hardware. However, PoT quantization triggers a severe accuracy drop because of its limited representation ability. Since DNN models have been applied for relatively complex tasks (e.g., classification for large datasets and object detection), improvement in accuracy for the PoT quantization method is required. Although some previous works attempt to improve the accuracy of PoT quantization, there is no work that balances accuracy and computation costs in a memory-efficient way. To address this problem, we propose an efficient PoT quantization scheme. Bit-level sparsity is introduced; weights (or activations) are rounded to values that can be calculated by n shift operations in multiplication. We also allow not only addition but also subtraction as each operation. Moreover, we use a two-stage fine-tuning algorithm to recover the accuracy drop that is triggered by introducing the bit-level sparsity. The experimental results on an object detection model (CenterNet, MobileNet-v2 backbone) on the COCO dataset show that our proposed method suppresses the accuracy drop by 0.3% at most while reducing the number of operations by about 75% and model size by 11.5% compared to the uniform method.
Description and Discussion on DCASE2020 Challenge Task2: Unsupervised Anomalous Sound Detection for Machine Condition Monitoring
Jun 10, 2020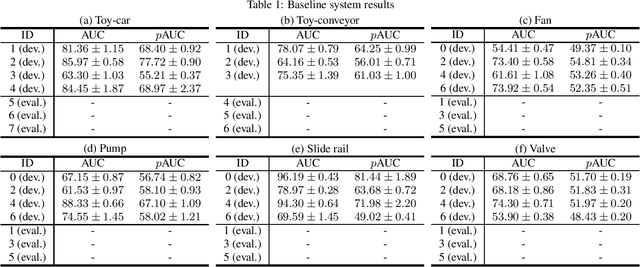
This paper presents the details of the DCASE 2020 Challenge Task 2; Unsupervised Detection of Anomalous Sounds for Machine Condition Monitoring. The goal of anomalous sound detection (ASD) is to identify whether the sound emitted from a target machine is normal or anomalous. The main challenge of this task is to detect unknown anomalous sounds under the condition that only normal sound samples have been provided as training data. We have designed a DCASE challenge task which contributes as a starting point and a benchmark of ASD research; the dataset, evaluation metrics, a simple baseline system, and other detailed rules. After the challenge submission deadline, challenge results and analysis of the submissions will be added.
Scene Text Magnifier
Jul 05, 2019

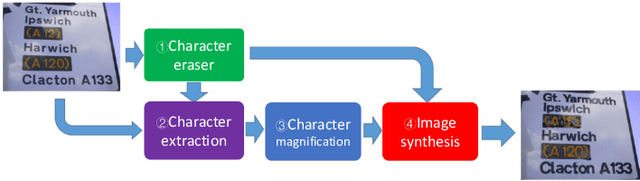
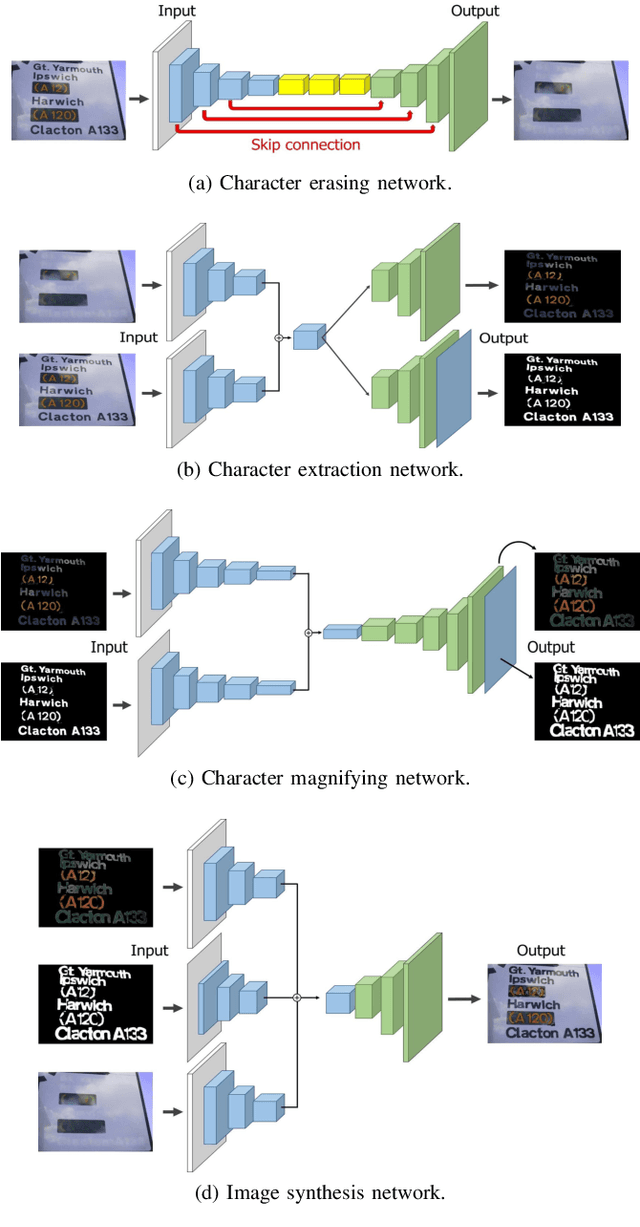
Scene text magnifier aims to magnify text in natural scene images without recognition. It could help the special groups, who have myopia or dyslexia to better understand the scene. In this paper, we design the scene text magnifier through interacted four CNN-based networks: character erasing, character extraction, character magnify, and image synthesis. The architecture of the networks are extended based on the hourglass encoder-decoders. It inputs the original scene text image and outputs the text magnified image while keeps the background unchange. Intermediately, we can get the side-output results of text erasing and text extraction. The four sub-networks are first trained independently and fine-tuned in end-to-end mode. The training samples for each stage are processed through a flow with original image and text annotation in ICDAR2013 and Flickr dataset as input, and corresponding text erased image, magnified text annotation, and text magnified scene image as output. To evaluate the performance of text magnifier, the Structural Similarity is used to measure the regional changes in each character region. The experimental results demonstrate our method can magnify scene text effectively without effecting the background.
Scene Text Eraser
May 08, 2017
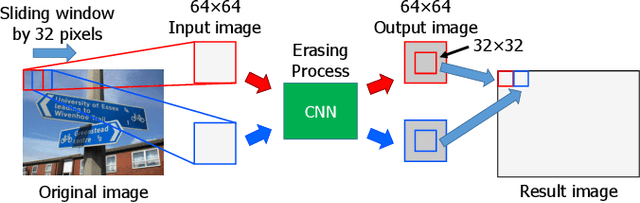
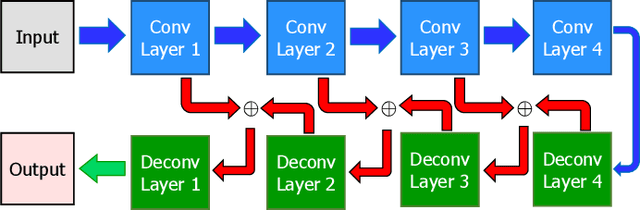

The character information in natural scene images contains various personal information, such as telephone numbers, home addresses, etc. It is a high risk of leakage the information if they are published. In this paper, we proposed a scene text erasing method to properly hide the information via an inpainting convolutional neural network (CNN) model. The input is a scene text image, and the output is expected to be text erased image with all the character regions filled up the colors of the surrounding background pixels. This work is accomplished by a CNN model through convolution to deconvolution with interconnection process. The training samples and the corresponding inpainting images are considered as teaching signals for training. To evaluate the text erasing performance, the output images are detected by a novel scene text detection method. Subsequently, the same measurement on text detection is utilized for testing the images in benchmark dataset ICDAR2013. Compared with direct text detection way, the scene text erasing process demonstrates a drastically decrease on the precision, recall and f-score. That proves the effectiveness of proposed method for erasing the text in natural scene images.