 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgen-hot: Efficient bit-level sparsity for powers-of-two neural network quantization
Mar 22, 2021
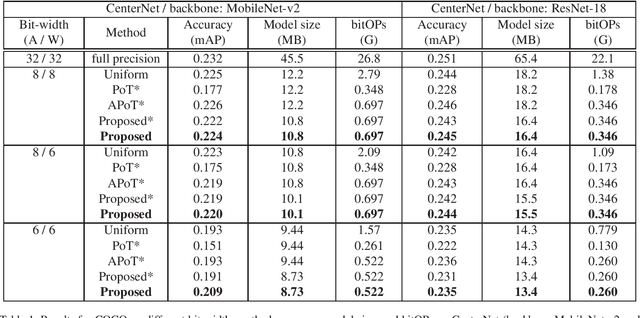
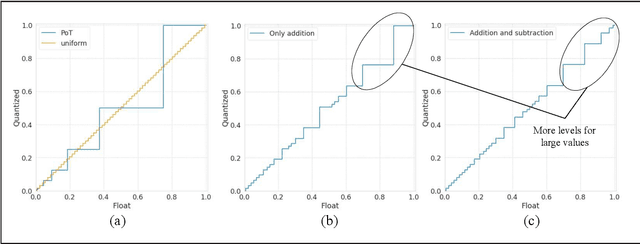
Powers-of-two (PoT) quantization reduces the number of bit operations of deep neural networks on resource-constrained hardware. However, PoT quantization triggers a severe accuracy drop because of its limited representation ability. Since DNN models have been applied for relatively complex tasks (e.g., classification for large datasets and object detection), improvement in accuracy for the PoT quantization method is required. Although some previous works attempt to improve the accuracy of PoT quantization, there is no work that balances accuracy and computation costs in a memory-efficient way. To address this problem, we propose an efficient PoT quantization scheme. Bit-level sparsity is introduced; weights (or activations) are rounded to values that can be calculated by n shift operations in multiplication. We also allow not only addition but also subtraction as each operation. Moreover, we use a two-stage fine-tuning algorithm to recover the accuracy drop that is triggered by introducing the bit-level sparsity. The experimental results on an object detection model (CenterNet, MobileNet-v2 backbone) on the COCO dataset show that our proposed method suppresses the accuracy drop by 0.3% at most while reducing the number of operations by about 75% and model size by 11.5% compared to the uniform method.
Filter Pre-Pruning for Improved Fine-tuning of Quantized Deep Neural Networks
Nov 25, 2020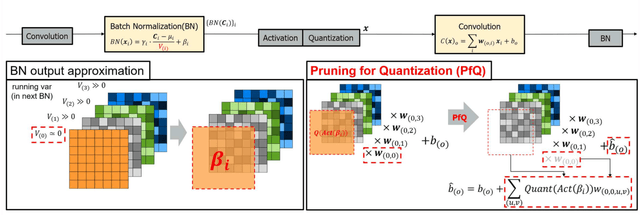
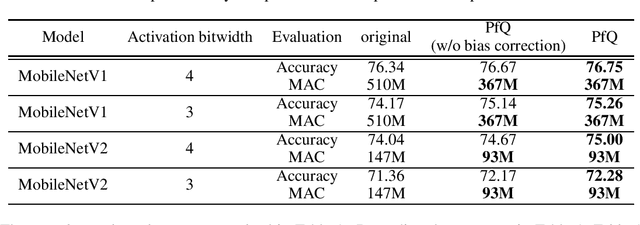
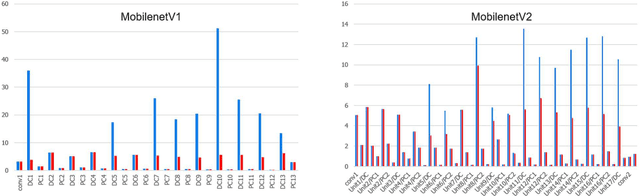
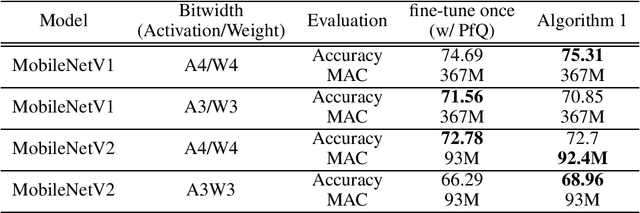
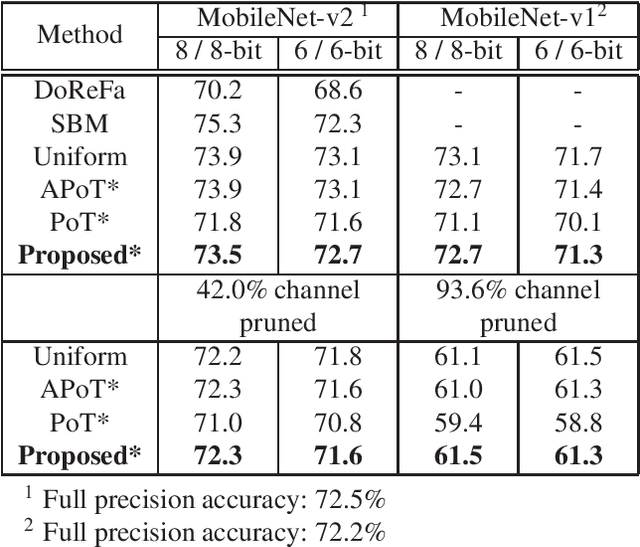
Deep Neural Networks(DNNs) have many parameters and activation data, and these both are expensive to implement. One method to reduce the size of the DNN is to quantize the pre-trained model by using a low-bit expression for weights and activations, using fine-tuning to recover the drop in accuracy. However, it is generally difficult to train neural networks which use low-bit expressions. One reason is that the weights in the middle layer of the DNN have a wide dynamic range and so when quantizing the wide dynamic range into a few bits, the step size becomes large, which leads to a large quantization error and finally a large degradation in accuracy. To solve this problem, this paper makes the following three contributions without using any additional learning parameters and hyper-parameters. First, we analyze how batch normalization, which causes the aforementioned problem, disturbs the fine-tuning of the quantized DNN. Second, based on these results, we propose a new pruning method called Pruning for Quantization (PfQ) which removes the filters that disturb the fine-tuning of the DNN while not affecting the inferred result as far as possible. Third, we propose a workflow of fine-tuning for quantized DNNs using the proposed pruning method(PfQ). Experiments using well-known models and datasets confirmed that the proposed method achieves higher performance with a similar model size than conventional quantization methods including fine-tuning.