 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgen-hot: Efficient bit-level sparsity for powers-of-two neural network quantization
Mar 22, 2021
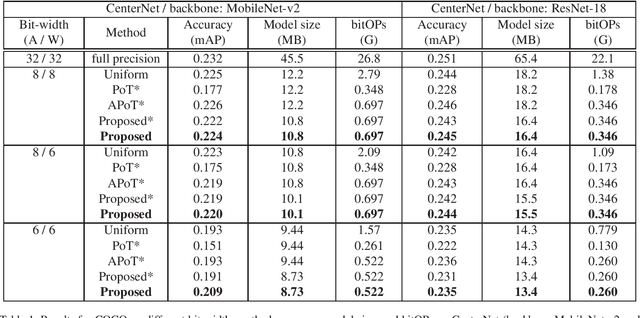
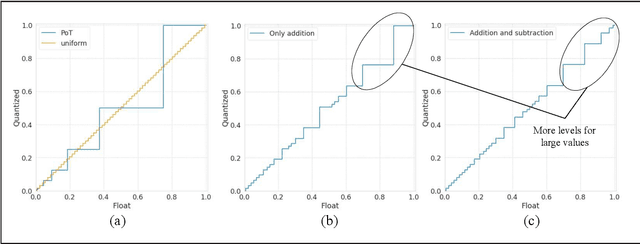
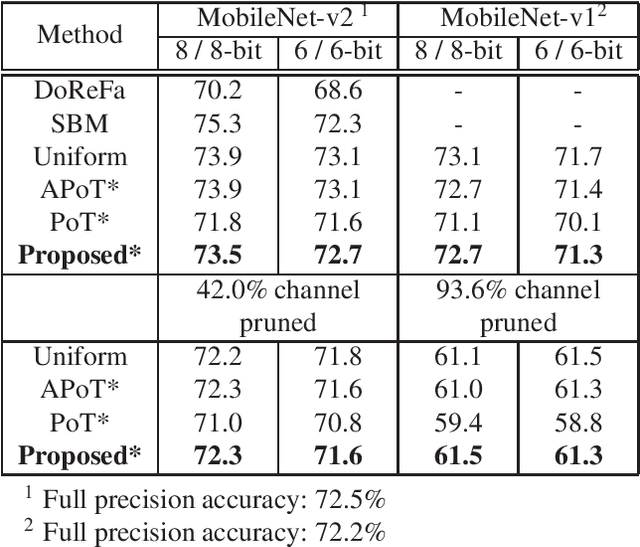
Powers-of-two (PoT) quantization reduces the number of bit operations of deep neural networks on resource-constrained hardware. However, PoT quantization triggers a severe accuracy drop because of its limited representation ability. Since DNN models have been applied for relatively complex tasks (e.g., classification for large datasets and object detection), improvement in accuracy for the PoT quantization method is required. Although some previous works attempt to improve the accuracy of PoT quantization, there is no work that balances accuracy and computation costs in a memory-efficient way. To address this problem, we propose an efficient PoT quantization scheme. Bit-level sparsity is introduced; weights (or activations) are rounded to values that can be calculated by n shift operations in multiplication. We also allow not only addition but also subtraction as each operation. Moreover, we use a two-stage fine-tuning algorithm to recover the accuracy drop that is triggered by introducing the bit-level sparsity. The experimental results on an object detection model (CenterNet, MobileNet-v2 backbone) on the COCO dataset show that our proposed method suppresses the accuracy drop by 0.3% at most while reducing the number of operations by about 75% and model size by 11.5% compared to the uniform method.