 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-precision Supernet Training from Vision Foundation Models using Low Rank Adapter
Mar 29, 2024Compression of large and performant vision foundation models (VFMs) into arbitrary bit-wise operations (BitOPs) allows their deployment on various hardware. We propose to fine-tune a VFM to a mixed-precision quantized supernet. The supernet-based neural architecture search (NAS) can be adopted for this purpose, which trains a supernet, and then subnets within arbitrary hardware budgets can be extracted. However, existing methods face difficulties in optimizing the mixed-precision search space and incurring large memory costs during training. To tackle these challenges, first, we study the effective search space design for fine-tuning a VFM by comparing different operators (such as resolution, feature size, width, depth, and bit-widths) in terms of performance and BitOPs reduction. Second, we propose memory-efficient supernet training using a low-rank adapter (LoRA) and a progressive training strategy. The proposed method is evaluated for the recently proposed VFM, Segment Anything Model, fine-tuned on segmentation tasks. The searched model yields about a 95% reduction in BitOPs without incurring performance degradation.
Instruct 3D-to-3D: Text Instruction Guided 3D-to-3D conversion
Mar 28, 2023



We propose a high-quality 3D-to-3D conversion method, Instruct 3D-to-3D. Our method is designed for a novel task, which is to convert a given 3D scene to another scene according to text instructions. Instruct 3D-to-3D applies pretrained Image-to-Image diffusion models for 3D-to-3D conversion. This enables the likelihood maximization of each viewpoint image and high-quality 3D generation. In addition, our proposed method explicitly inputs the source 3D scene as a condition, which enhances 3D consistency and controllability of how much of the source 3D scene structure is reflected. We also propose dynamic scaling, which allows the intensity of the geometry transformation to be adjusted. We performed quantitative and qualitative evaluations and showed that our proposed method achieves higher quality 3D-to-3D conversions than baseline methods.
DetOFA: Efficient Training of Once-for-All Networks for Object Detection by Using Pre-trained Supernet and Path Filter
Mar 23, 2023



We address the challenge of training a large supernet for the object detection task, using a relatively small amount of training data. Specifically, we propose an efficient supernet-based neural architecture search (NAS) method that uses transfer learning and search space pruning. First, the supernet is pre-trained on a classification task, for which large datasets are available. Second, the search space defined by the supernet is pruned by removing candidate models that are predicted to perform poorly. To effectively remove the candidates over a wide range of resource constraints, we particularly design a performance predictor, called path filter, which can accurately predict the relative performance of the models that satisfy similar resource constraints. Hence, supernet training is more focused on the best-performing candidates. Our path filter handles prediction for paths with different resource budgets. Compared to once-for-all, our proposed method reduces the computational cost of the optimal network architecture by 30% and 63%, while yielding better accuracy-floating point operations Pareto front (0.85 and 0.45 points of improvement on average precision for Pascal VOC and COCO, respectively).
n-hot: Efficient bit-level sparsity for powers-of-two neural network quantization
Mar 22, 2021
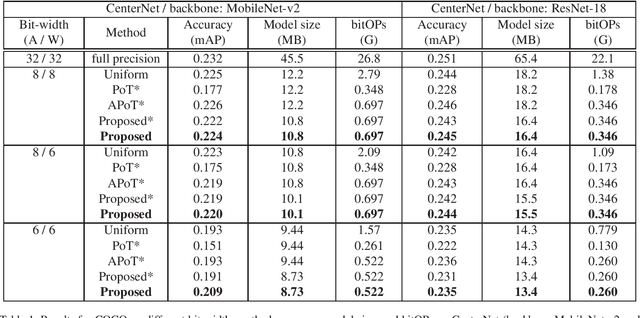
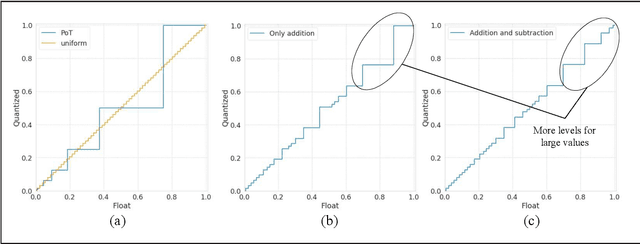
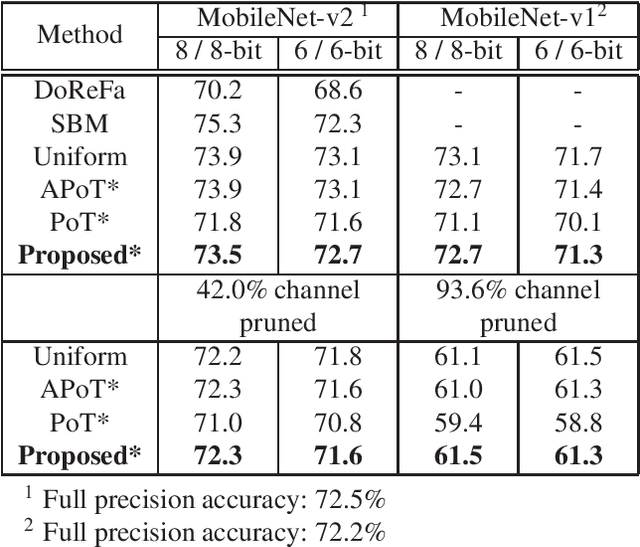
Powers-of-two (PoT) quantization reduces the number of bit operations of deep neural networks on resource-constrained hardware. However, PoT quantization triggers a severe accuracy drop because of its limited representation ability. Since DNN models have been applied for relatively complex tasks (e.g., classification for large datasets and object detection), improvement in accuracy for the PoT quantization method is required. Although some previous works attempt to improve the accuracy of PoT quantization, there is no work that balances accuracy and computation costs in a memory-efficient way. To address this problem, we propose an efficient PoT quantization scheme. Bit-level sparsity is introduced; weights (or activations) are rounded to values that can be calculated by n shift operations in multiplication. We also allow not only addition but also subtraction as each operation. Moreover, we use a two-stage fine-tuning algorithm to recover the accuracy drop that is triggered by introducing the bit-level sparsity. The experimental results on an object detection model (CenterNet, MobileNet-v2 backbone) on the COCO dataset show that our proposed method suppresses the accuracy drop by 0.3% at most while reducing the number of operations by about 75% and model size by 11.5% compared to the uniform method.