 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Data Curation for Object Detection via Marginal Contributions to Dataset-level Average Precision
Nov 18, 2025High-quality data has become a primary driver of progress under scale laws, with curated datasets often outperforming much larger unfiltered ones at lower cost. Online data curation extends this idea by dynamically selecting training samples based on the model's evolving state. While effective in classification and multimodal learning, existing online sampling strategies rarely extend to object detection because of its structural complexity and domain gaps. We introduce DetGain, an online data curation method specifically for object detection that estimates the marginal perturbation of each image to dataset-level Average Precision (AP) based on its prediction quality. By modeling global score distributions, DetGain efficiently estimates the global AP change and computes teacher-student contribution gaps to select informative samples at each iteration. The method is architecture-agnostic and minimally intrusive, enabling straightforward integration into diverse object detection architectures. Experiments on the COCO dataset with multiple representative detectors show consistent improvements in accuracy. DetGain also demonstrates strong robustness under low-quality data and can be effectively combined with knowledge distillation techniques to further enhance performance, highlighting its potential as a general and complementary strategy for data-efficient object detection.
Extreme Compression of Adaptive Neural Images
May 27, 2024Implicit Neural Representations (INRs) and Neural Fields are a novel paradigm for signal representation, from images and audio to 3D scenes and videos. The fundamental idea is to represent a signal as a continuous and differentiable neural network. This idea offers unprecedented benefits such as continuous resolution and memory efficiency, enabling new compression techniques. However, representing data as neural networks poses new challenges. For instance, given a 2D image as a neural network, how can we further compress such a neural image?. In this work, we present a novel analysis on compressing neural fields, with the focus on images. We also introduce Adaptive Neural Images (ANI), an efficient neural representation that enables adaptation to different inference or transmission requirements. Our proposed method allows to reduce the bits-per-pixel (bpp) of the neural image by 4x, without losing sensitive details or harming fidelity. We achieve this thanks to our successful implementation of 4-bit neural representations. Our work offers a new framework for developing compressed neural fields.
Mixed-precision Supernet Training from Vision Foundation Models using Low Rank Adapter
Mar 29, 2024Compression of large and performant vision foundation models (VFMs) into arbitrary bit-wise operations (BitOPs) allows their deployment on various hardware. We propose to fine-tune a VFM to a mixed-precision quantized supernet. The supernet-based neural architecture search (NAS) can be adopted for this purpose, which trains a supernet, and then subnets within arbitrary hardware budgets can be extracted. However, existing methods face difficulties in optimizing the mixed-precision search space and incurring large memory costs during training. To tackle these challenges, first, we study the effective search space design for fine-tuning a VFM by comparing different operators (such as resolution, feature size, width, depth, and bit-widths) in terms of performance and BitOPs reduction. Second, we propose memory-efficient supernet training using a low-rank adapter (LoRA) and a progressive training strategy. The proposed method is evaluated for the recently proposed VFM, Segment Anything Model, fine-tuned on segmentation tasks. The searched model yields about a 95% reduction in BitOPs without incurring performance degradation.
Efficient Joint Detection and Multiple Object Tracking with Spatially Aware Transformer
Nov 09, 2022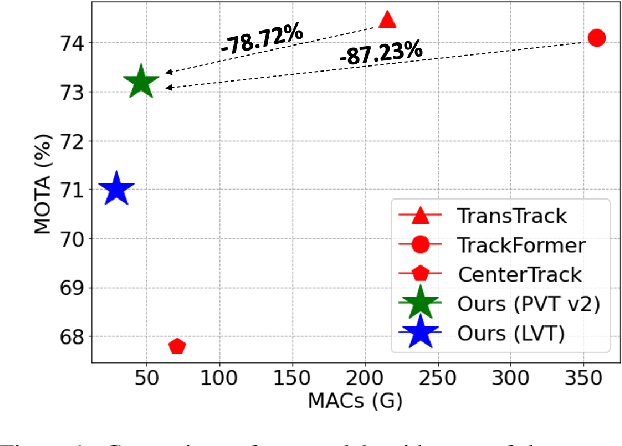
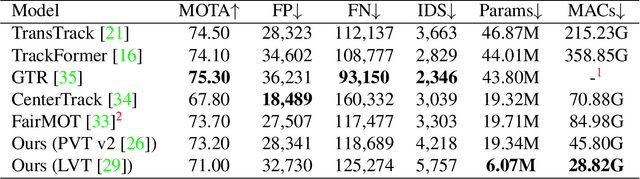
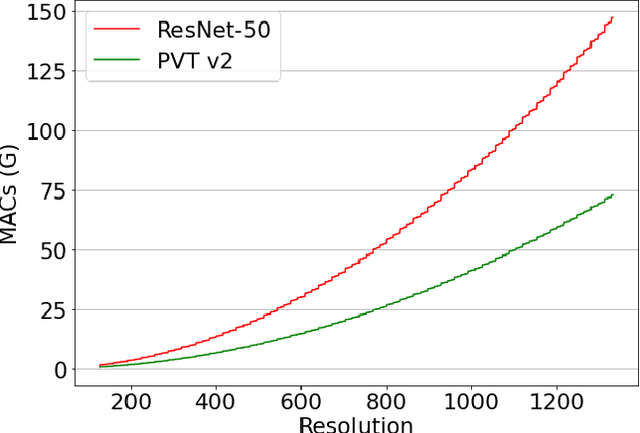
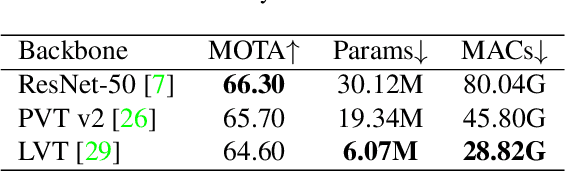
We propose a light-weight and highly efficient Joint Detection and Tracking pipeline for the task of Multi-Object Tracking using a fully-transformer architecture. It is a modified version of TransTrack, which overcomes the computational bottleneck associated with its design, and at the same time, achieves state-of-the-art MOTA score of 73.20%. The model design is driven by a transformer based backbone instead of CNN, which is highly scalable with the input resolution. We also propose a drop-in replacement for Feed Forward Network of transformer encoder layer, by using Butterfly Transform Operation to perform channel fusion and depth-wise convolution to learn spatial context within the feature maps, otherwise missing within the attention maps of the transformer. As a result of our modifications, we reduce the overall model size of TransTrack by 58.73% and the complexity by 78.72%. Therefore, we expect our design to provide novel perspectives for architecture optimization in future research related to multi-object tracking.
DynamicISP: Dynamically Controlled Image Signal Processor for Image Recognition
Nov 02, 2022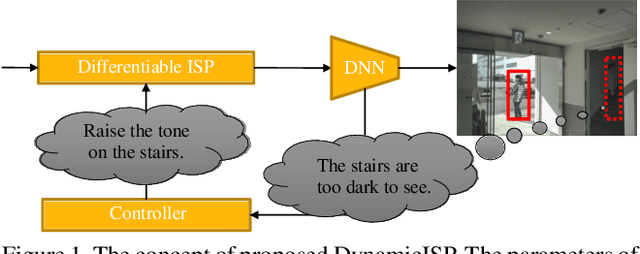
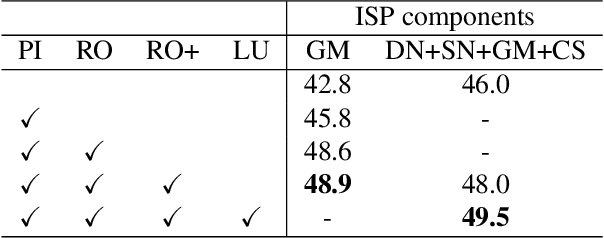
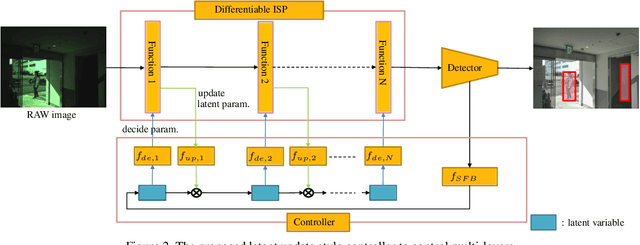
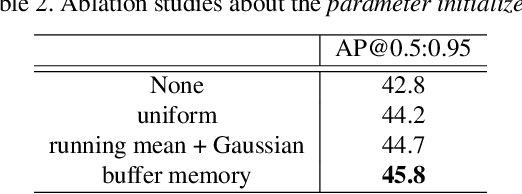
Image signal processor (ISP) plays an important role not only for human perceptual quality but also for computer vision. In most cases, experts resort to manual tuning of many parameters in the ISPs for perceptual quality. It failed in sub-optimal, especially for computer vision. Aiming to improve ISPs, two approaches have been actively proposed; tuning the parameters with machine learning, or constructing an ISP with DNN. The former is lightweight but lacks expressive powers. The latter has expressive powers but it was too heavy to calculate on edge devices. To this end, we propose DynamicISP, which consists of traditional simple ISP functions but their parameters are controlled dynamically per image according to what the downstream image recognition model felt to the previous frame. Our proposed method successfully controlled parameters of multiple ISP functions and got state-of-the-art accuracy with a small computational cost.
Rawgment: Noise-Accounted RAW Augmentation Enables Recognition in a Wide Variety of Environments
Oct 28, 2022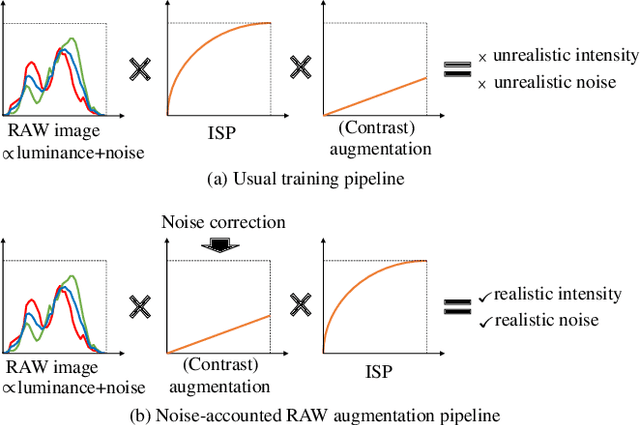

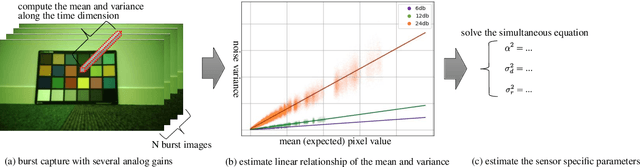
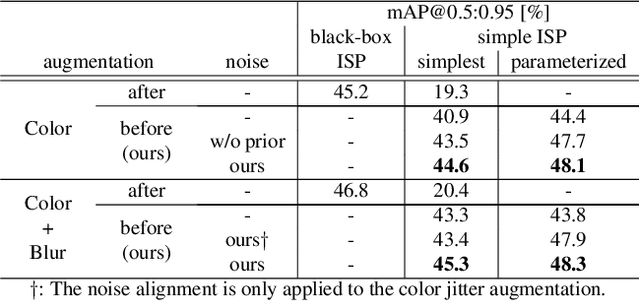
Image recognition models that can work in challenging environments (e.g., extremely dark, blurry, or high dynamic range conditions) must be useful. However, creating a training dataset for such environments is expensive and hard due to the difficulties of data collection and annotation. It is desirable if we could get a robust model without the need of hard-to-obtain dataset. One simple approach is to apply data augmentation such as color jitter and blur to standard RGB (sRGB) images in simple scenes. Unfortunately, this approach struggles to yield realistic images in terms of pixel intensity and noise distribution due to not considering the non-linearity of Image Signal Processor (ISP) and noise characteristics of an image sensor. Instead, we propose a noise-accounted RAW image augmentation method. In essence, color jitter and blur augmentation are applied to a RAW image before applying non-linear ISP, yielding realistic intensity. Furthermore, we introduce a noise amount alignment method that calibrates the domain gap in noise property caused by the augmentation. We show that our proposed noise-accounted RAW augmentation method doubles the image recognition accuracy in challenging environments only with simple training data.