 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB$^3$-Seg: Camera-Free, Training-Free 3DGS Segmentation via Analytic EIG and Beta-Bernoulli Bayesian Updates
Feb 19, 2026Interactive 3D Gaussian Splatting (3DGS) segmentation is essential for real-time editing of pre-reconstructed assets in film and game production. However, existing methods rely on predefined camera viewpoints, ground-truth labels, or costly retraining, making them impractical for low-latency use. We propose B$^3$-Seg (Beta-Bernoulli Bayesian Segmentation for 3DGS), a fast and theoretically grounded method for open-vocabulary 3DGS segmentation under camera-free and training-free conditions. Our approach reformulates segmentation as sequential Beta-Bernoulli Bayesian updates and actively selects the next view via analytic Expected Information Gain (EIG). This Bayesian formulation guarantees the adaptive monotonicity and submodularity of EIG, which produces a greedy $(1{-}1/e)$ approximation to the optimal view sampling policy. Experiments on multiple datasets show that B$^3$-Seg achieves competitive results to high-cost supervised methods while operating end-to-end segmentation within a few seconds. The results demonstrate that B$^3$-Seg enables practical, interactive 3DGS segmentation with provable information efficiency.
Instruct 3D-to-3D: Text Instruction Guided 3D-to-3D conversion
Mar 28, 2023



We propose a high-quality 3D-to-3D conversion method, Instruct 3D-to-3D. Our method is designed for a novel task, which is to convert a given 3D scene to another scene according to text instructions. Instruct 3D-to-3D applies pretrained Image-to-Image diffusion models for 3D-to-3D conversion. This enables the likelihood maximization of each viewpoint image and high-quality 3D generation. In addition, our proposed method explicitly inputs the source 3D scene as a condition, which enhances 3D consistency and controllability of how much of the source 3D scene structure is reflected. We also propose dynamic scaling, which allows the intensity of the geometry transformation to be adjusted. We performed quantitative and qualitative evaluations and showed that our proposed method achieves higher quality 3D-to-3D conversions than baseline methods.
Fully Spiking Variational Autoencoder
Oct 05, 2021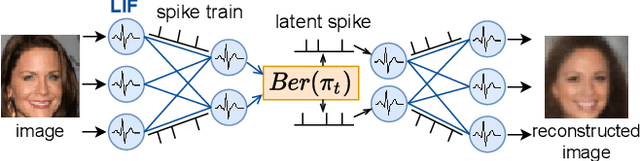
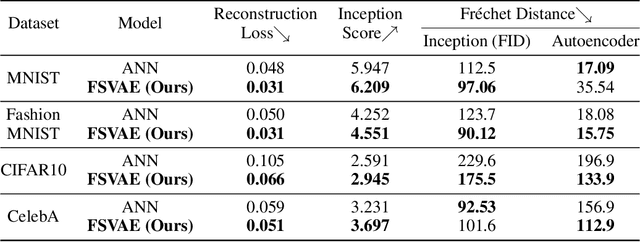
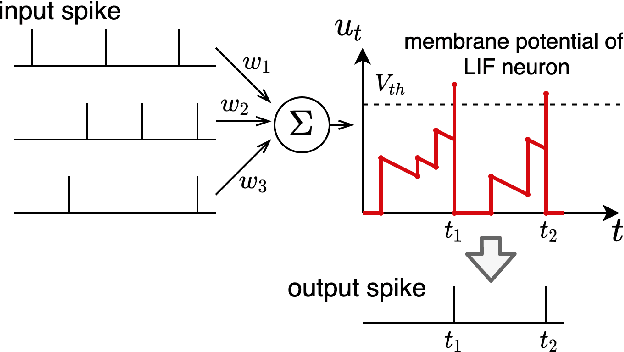

Spiking neural networks (SNNs) can be run on neuromorphic devices with ultra-high speed and ultra-low energy consumption because of their binary and event-driven nature. Therefore, SNNs are expected to have various applications, including as generative models being running on edge devices to create high-quality images. In this study, we build a variational autoencoder (VAE) with SNN to enable image generation. VAE is known for its stability among generative models; recently, its quality advanced. In vanilla VAE, the latent space is represented as a normal distribution, and floating-point calculations are required in sampling. However, this is not possible in SNNs because all features must be binary time series data. Therefore, we constructed the latent space with an autoregressive SNN model, and randomly selected samples from its output to sample the latent variables. This allows the latent variables to follow the Bernoulli process and allows variational learning. Thus, we build the Fully Spiking Variational Autoencoder where all modules are constructed with SNN. To the best of our knowledge, we are the first to build a VAE only with SNN layers. We experimented with several datasets, and confirmed that it can generate images with the same or better quality compared to conventional ANNs. The code is available at https://github.com/kamata1729/FullySpikingVAE