 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing and Enhancing Core Visual Regions: Harnessing Internal Attention Dynamics for Hallucination Mitigation in LVLMs
Feb 17, 2026LVLMs have achieved strong multimodal reasoning capabilities but remain prone to hallucinations, producing outputs inconsistent with visual inputs or user instructions. Existing training-free methods, including contrastive decoding and auxiliary expert models, which incur several times more computational overhead and may introduce potential interference, as well as static internal signal enhancement, are often vulnerable to the attention sink phenomenon. We find that internal Positive Attention Dynamics (PAD) in LVLMs naturally reveal semantically core visual regions under the distortions of attention sinks. Based on this, we propose Positive Attention Dynamics Enhancement (PADE), a training-free attention intervention that constructs a PAD map to identify semantically core visual regions, applies per-head Median Absolute Deviation Scaling to adaptively control the intervention strength, and leverages System-Token Compensation to maintain attention to complex user instructions and support long-term output consistency. Experiments on multiple LVLMs and benchmarks show that PADE improves visual grounding and reduces hallucinations, validating the effectiveness of leveraging internal attention dynamics for reliable multimodal reasoning.
Towards Interpretable Hallucination Analysis and Mitigation in LVLMs via Contrastive Neuron Steering
Jan 31, 2026LVLMs achieve remarkable multimodal understanding and generation but remain susceptible to hallucinations. Existing mitigation methods predominantly focus on output-level adjustments, leaving the internal mechanisms that give rise to these hallucinations largely unexplored. To gain a deeper understanding, we adopt a representation-level perspective by introducing sparse autoencoders (SAEs) to decompose dense visual embeddings into sparse, interpretable neurons. Through neuron-level analysis, we identify distinct neuron types, including always-on neurons and image-specific neurons. Our findings reveal that hallucinations often result from disruptions or spurious activations of image-specific neurons, while always-on neurons remain largely stable. Moreover, selectively enhancing or suppressing image-specific neurons enables controllable intervention in LVLM outputs, improving visual grounding and reducing hallucinations. Building on these insights, we propose Contrastive Neuron Steering (CNS), which identifies image-specific neurons via contrastive analysis between clean and noisy inputs. CNS selectively amplifies informative neurons while suppressing perturbation-induced activations, producing more robust and semantically grounded visual representations. This not only enhances visual understanding but also effectively mitigates hallucinations. By operating at the prefilling stage, CNS is fully compatible with existing decoding-stage methods. Extensive experiments on both hallucination-focused and general multimodal benchmarks demonstrate that CNS consistently reduces hallucinations while preserving overall multimodal understanding.
Beyond Global Alignment: Fine-Grained Motion-Language Retrieval via Pyramidal Shapley-Taylor Learning
Jan 29, 2026As a foundational task in human-centric cross-modal intelligence, motion-language retrieval aims to bridge the semantic gap between natural language and human motion, enabling intuitive motion analysis, yet existing approaches predominantly focus on aligning entire motion sequences with global textual representations. This global-centric paradigm overlooks fine-grained interactions between local motion segments and individual body joints and text tokens, inevitably leading to suboptimal retrieval performance. To address this limitation, we draw inspiration from the pyramidal process of human motion perception (from joint dynamics to segment coherence, and finally to holistic comprehension) and propose a novel Pyramidal Shapley-Taylor (PST) learning framework for fine-grained motion-language retrieval. Specifically, the framework decomposes human motion into temporal segments and spatial body joints, and learns cross-modal correspondences through progressive joint-wise and segment-wise alignment in a pyramidal fashion, effectively capturing both local semantic details and hierarchical structural relationships. Extensive experiments on multiple public benchmark datasets demonstrate that our approach significantly outperforms state-of-the-art methods, achieving precise alignment between motion segments and body joints and their corresponding text tokens. The code of this work will be released upon acceptance.
Towards Arbitrary Motion Completing via Hierarchical Continuous Representation
Dec 24, 2025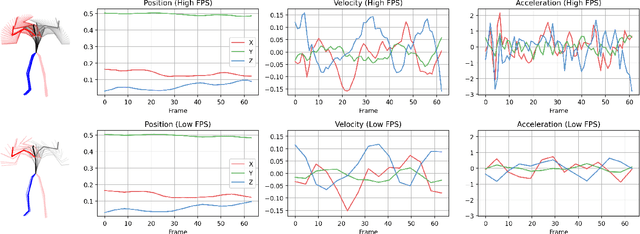
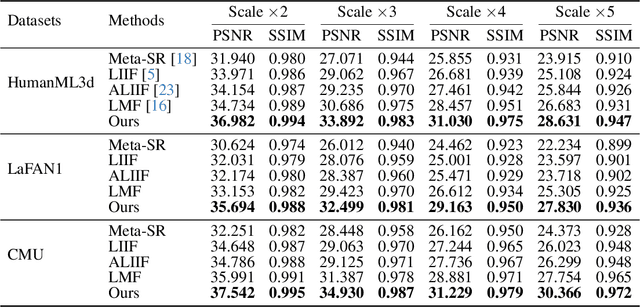
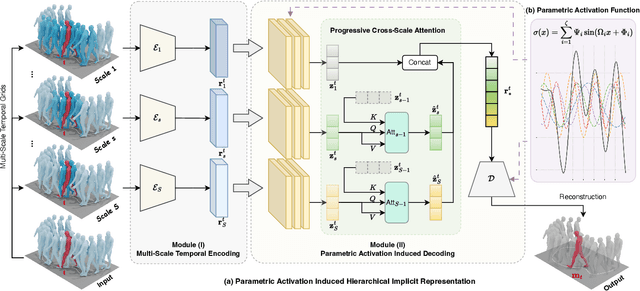
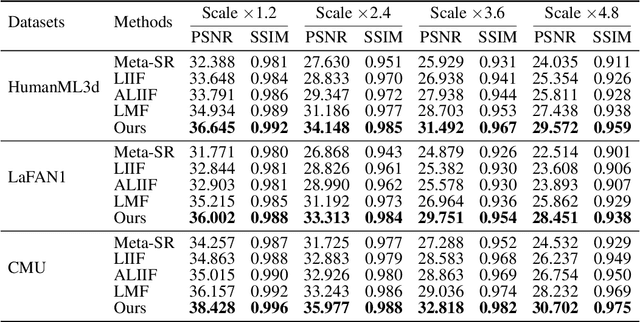
Physical motions are inherently continuous, and higher camera frame rates typically contribute to improved smoothness and temporal coherence. For the first time, we explore continuous representations of human motion sequences, featuring the ability to interpolate, inbetween, and even extrapolate any input motion sequences at arbitrary frame rates. To achieve this, we propose a novel parametric activation-induced hierarchical implicit representation framework, referred to as NAME, based on Implicit Neural Representations (INRs). Our method introduces a hierarchical temporal encoding mechanism that extracts features from motion sequences at multiple temporal scales, enabling effective capture of intricate temporal patterns. Additionally, we integrate a custom parametric activation function, powered by Fourier transformations, into the MLP-based decoder to enhance the expressiveness of the continuous representation. This parametric formulation significantly augments the model's ability to represent complex motion behaviors with high accuracy. Extensive evaluations across several benchmark datasets demonstrate the effectiveness and robustness of our proposed approach.
Tempo as the Stable Cue: Hierarchical Mixture of Tempo and Beat Experts for Music to 3D Dance Generation
Dec 21, 2025Music to 3D dance generation aims to synthesize realistic and rhythmically synchronized human dance from music. While existing methods often rely on additional genre labels to further improve dance generation, such labels are typically noisy, coarse, unavailable, or insufficient to capture the diversity of real-world music, which can result in rhythm misalignment or stylistic drift. In contrast, we observe that tempo, a core property reflecting musical rhythm and pace, remains relatively consistent across datasets and genres, typically ranging from 60 to 200 BPM. Based on this finding, we propose TempoMoE, a hierarchical tempo-aware Mixture-of-Experts module that enhances the diffusion model and its rhythm perception. TempoMoE organizes motion experts into tempo-structured groups for different tempo ranges, with multi-scale beat experts capturing fine- and long-range rhythmic dynamics. A Hierarchical Rhythm-Adaptive Routing dynamically selects and fuses experts from music features, enabling flexible, rhythm-aligned generation without manual genre labels. Extensive experiments demonstrate that TempoMoE achieves state-of-the-art results in dance quality and rhythm alignment.
Revealing Perception and Generation Dynamics in LVLMs: Mitigating Hallucinations via Validated Dominance Correction
Dec 21, 2025Large Vision-Language Models (LVLMs) have shown remarkable capabilities, yet hallucinations remain a persistent challenge. This work presents a systematic analysis of the internal evolution of visual perception and token generation in LVLMs, revealing two key patterns. First, perception follows a three-stage GATE process: early layers perform a Global scan, intermediate layers Approach and Tighten on core content, and later layers Explore supplementary regions. Second, generation exhibits an SAD (Subdominant Accumulation to Dominant) pattern, where hallucinated tokens arise from the repeated accumulation of subdominant tokens lacking support from attention (visual perception) or feed-forward network (internal knowledge). Guided by these findings, we devise the VDC (Validated Dominance Correction) strategy, which detects unsupported tokens and replaces them with validated dominant ones to improve output reliability. Extensive experiments across multiple models and benchmarks confirm that VDC substantially mitigates hallucinations.
FETNet: Feature Erasing and Transferring Network for Scene Text Removal
Jun 16, 2023



The scene text removal (STR) task aims to remove text regions and recover the background smoothly in images for private information protection. Most existing STR methods adopt encoder-decoder-based CNNs, with direct copies of the features in the skip connections. However, the encoded features contain both text texture and structure information. The insufficient utilization of text features hampers the performance of background reconstruction in text removal regions. To tackle these problems, we propose a novel Feature Erasing and Transferring (FET) mechanism to reconfigure the encoded features for STR in this paper. In FET, a Feature Erasing Module (FEM) is designed to erase text features. An attention module is responsible for generating the feature similarity guidance. The Feature Transferring Module (FTM) is introduced to transfer the corresponding features in different layers based on the attention guidance. With this mechanism, a one-stage, end-to-end trainable network called FETNet is constructed for scene text removal. In addition, to facilitate research on both scene text removal and segmentation tasks, we introduce a novel dataset, Flickr-ST, with multi-category annotations. A sufficient number of experiments and ablation studies are conducted on the public datasets and Flickr-ST. Our proposed method achieves state-of-the-art performance using most metrics, with remarkably higher quality scene text removal results. The source code of our work is available at: \href{https://github.com/GuangtaoLyu/FETNet}{https://github.com/GuangtaoLyu/FETNet.
* Accepted by Pattern Recognition 2023
PSSTRNet: Progressive Segmentation-guided Scene Text Removal Network
Jun 13, 2023Scene text removal (STR) is a challenging task due to the complex text fonts, colors, sizes, and background textures in scene images. However, most previous methods learn both text location and background inpainting implicitly within a single network, which weakens the text localization mechanism and makes a lossy background. To tackle these problems, we propose a simple Progressive Segmentation-guided Scene Text Removal Network(PSSTRNet) to remove the text in the image iteratively. It contains two decoder branches, a text segmentation branch, and a text removal branch, with a shared encoder. The text segmentation branch generates text mask maps as the guidance for the regional removal branch. In each iteration, the original image, previous text removal result, and text mask are input to the network to extract the rest part of the text segments and cleaner text removal result. To get a more accurate text mask map, an update module is developed to merge the mask map in the current and previous stages. The final text removal result is obtained by adaptive fusion of results from all previous stages. A sufficient number of experiments and ablation studies conducted on the real and synthetic public datasets demonstrate our proposed method achieves state-of-the-art performance. The source code of our work is available at: \href{https://github.com/GuangtaoLyu/PSSTRNet}{https://github.com/GuangtaoLyu/PSSTRNet.}
* Accepted by ICME2022
MSLKANet: A Multi-Scale Large Kernel Attention Network for Scene Text Removal
Nov 12, 2022Scene text removal aims to remove the text and fill the regions with perceptually plausible background information in natural images. It has attracted increasing attention due to its various applications in privacy protection, scene text retrieval, and text editing. With the development of deep learning, the previous methods have achieved significant improvements. However, most of the existing methods seem to ignore the large perceptive fields and global information. The pioneer method can get significant improvements by only changing training data from the cropped image to the full image. In this paper, we present a single-stage multi-scale network MSLKANet for scene text removal in full images. For obtaining large perceptive fields and global information, we propose multi-scale large kernel attention (MSLKA) to obtain long-range dependencies between the text regions and the backgrounds at various granularity levels. Furthermore, we combine the large kernel decomposition mechanism and atrous spatial pyramid pooling to build a large kernel spatial pyramid pooling (LKSPP), which can perceive more valid pixels in the spatial dimension while maintaining large receptive fields and low cost of computation. Extensive experimental results indicate that the proposed method achieves state-of-the-art performance on both synthetic and real-world datasets and the effectiveness of the proposed components MSLKA and LKSPP.