 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation for Ulcerative Colitis Severity Estimation Using Patient-Level Diagnoses
Sep 18, 2025



The development of methods to estimate the severity of Ulcerative Colitis (UC) is of significant importance. However, these methods often suffer from domain shifts caused by differences in imaging devices and clinical settings across hospitals. Although several domain adaptation methods have been proposed to address domain shift, they still struggle with the lack of supervision in the target domain or the high cost of annotation. To overcome these challenges, we propose a novel Weakly Supervised Domain Adaptation method that leverages patient-level diagnostic results, which are routinely recorded in UC diagnosis, as weak supervision in the target domain. The proposed method aligns class-wise distributions across domains using Shared Aggregation Tokens and a Max-Severity Triplet Loss, which leverages the characteristic that patient-level diagnoses are determined by the most severe region within each patient. Experimental results demonstrate that our method outperforms comparative DA approaches, improving UC severity estimation in a domain-shifted setting.
Model Selection with a Shapelet-based Distance Measure for Multi-source Transfer Learning in Time Series Classification
Sep 30, 2024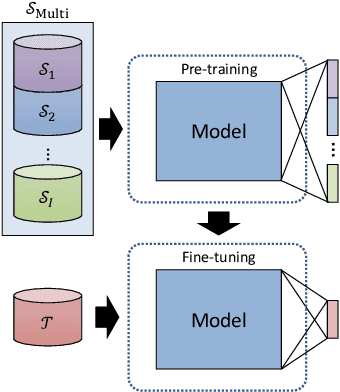

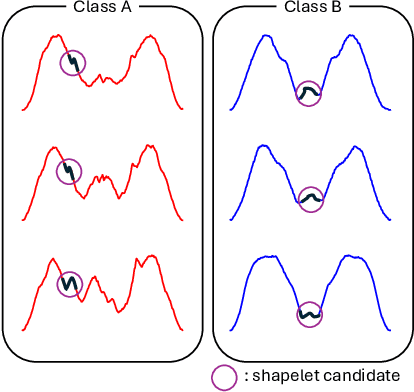
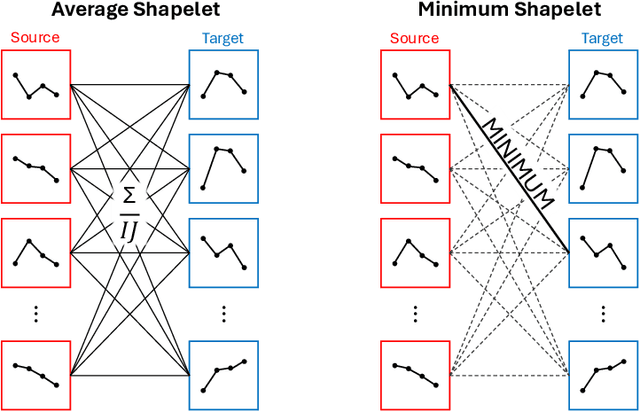
Transfer learning is a common practice that alleviates the need for extensive data to train neural networks. It is performed by pre-training a model using a source dataset and fine-tuning it for a target task. However, not every source dataset is appropriate for each target dataset, especially for time series. In this paper, we propose a novel method of selecting and using multiple datasets for transfer learning for time series classification. Specifically, our method combines multiple datasets as one source dataset for pre-training neural networks. Furthermore, for selecting multiple sources, our method measures the transferability of datasets based on shapelet discovery for effective source selection. While traditional transferability measures require considerable time for pre-training all the possible sources for source selection of each possible architecture, our method can be repeatedly used for every possible architecture with a single simple computation. Using the proposed method, we demonstrate that it is possible to increase the performance of temporal convolutional neural networks (CNN) on time series datasets.
What Text Design Characterizes Book Genres?
Feb 26, 2024



This study analyzes the relationship between non-verbal information (e.g., genres) and text design (e.g., font style, character color, etc.) through the classification of book genres using text design on book covers. Text images have both semantic information about the word itself and other information (non-semantic information or visual design), such as font style, character color, etc. When we read a word printed on some materials, we receive impressions or other information from both the word itself and the visual design. Basically, we can understand verbal information only from semantic information, i.e., the words themselves; however, we can consider that text design is helpful for understanding other additional information (i.e., non-verbal information), such as impressions, genre, etc. To investigate the effect of text design, we analyze text design using words printed on book covers and their genres in two scenarios. First, we attempted to understand the importance of visual design for determining the genre (i.e., non-verbal information) of books by analyzing the differences in the relationship between semantic information/visual design and genres. In the experiment, we found that semantic information is sufficient to determine the genre; however, text design is helpful in adding more discriminative features for book genres. Second, we investigated the effect of each text design on book genres. As a result, we found that each text design characterizes some book genres. For example, font style is useful to add more discriminative features for genres of ``Mystery, Thriller \& Suspense'' and ``Christian books \& Bibles.''
Few shot font generation via transferring similarity guided global style and quantization local style
Sep 14, 2023Automatic few-shot font generation (AFFG), aiming at generating new fonts with only a few glyph references, reduces the labor cost of manually designing fonts. However, the traditional AFFG paradigm of style-content disentanglement cannot capture the diverse local details of different fonts. So, many component-based approaches are proposed to tackle this problem. The issue with component-based approaches is that they usually require special pre-defined glyph components, e.g., strokes and radicals, which is infeasible for AFFG of different languages. In this paper, we present a novel font generation approach by aggregating styles from character similarity-guided global features and stylized component-level representations. We calculate the similarity scores of the target character and the referenced samples by measuring the distance along the corresponding channels from the content features, and assigning them as the weights for aggregating the global style features. To better capture the local styles, a cross-attention-based style transfer module is adopted to transfer the styles of reference glyphs to the components, where the components are self-learned discrete latent codes through vector quantization without manual definition. With these designs, our AFFG method could obtain a complete set of component-level style representations, and also control the global glyph characteristics. The experimental results reflect the effectiveness and generalization of the proposed method on different linguistic scripts, and also show its superiority when compared with other state-of-the-art methods. The source code can be found at https://github.com/awei669/VQ-Font.
Deep Attentive Time Warping
Sep 13, 2023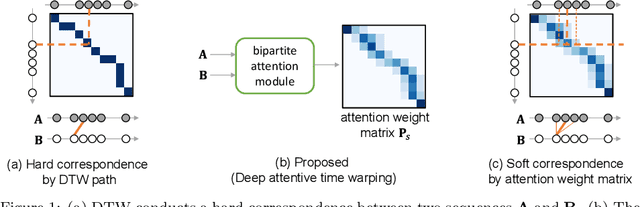
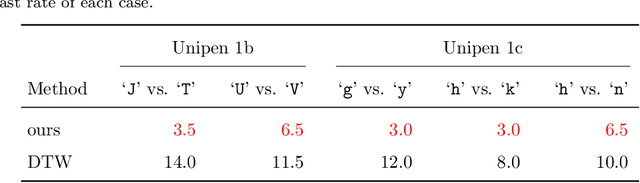
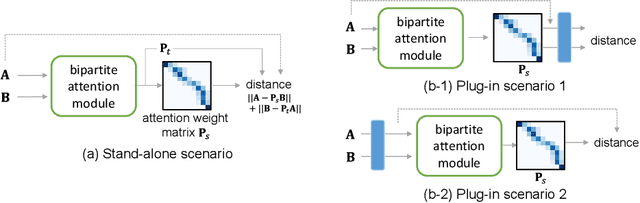
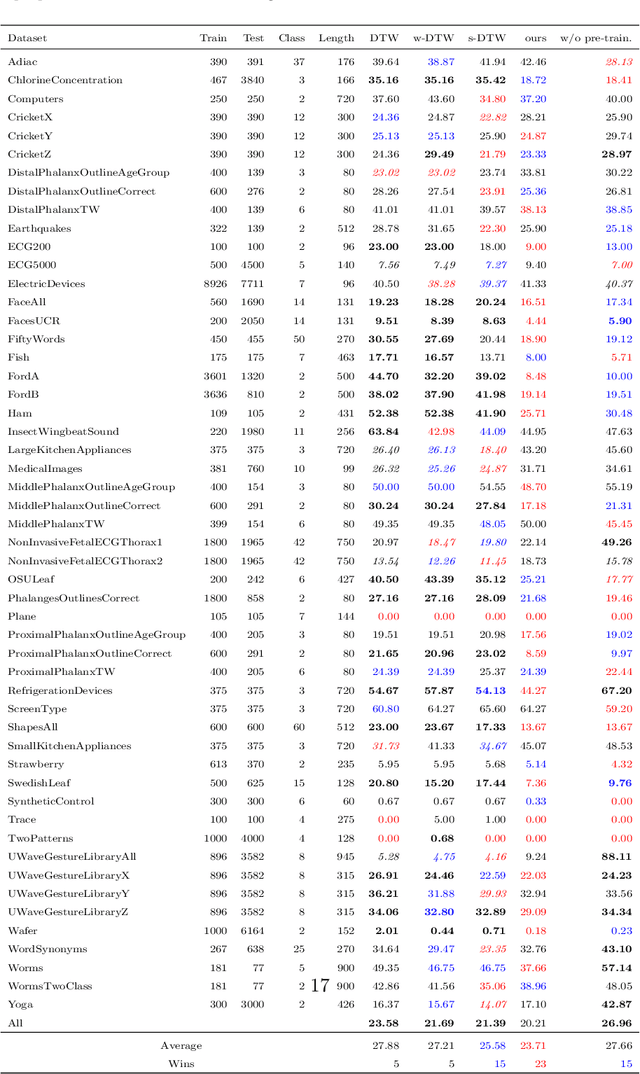
Similarity measures for time series are important problems for time series classification. To handle the nonlinear time distortions, Dynamic Time Warping (DTW) has been widely used. However, DTW is not learnable and suffers from a trade-off between robustness against time distortion and discriminative power. In this paper, we propose a neural network model for task-adaptive time warping. Specifically, we use the attention model, called the bipartite attention model, to develop an explicit time warping mechanism with greater distortion invariance. Unlike other learnable models using DTW for warping, our model predicts all local correspondences between two time series and is trained based on metric learning, which enables it to learn the optimal data-dependent warping for the target task. We also propose to induce pre-training of our model by DTW to improve the discriminative power. Extensive experiments demonstrate the superior effectiveness of our model over DTW and its state-of-the-art performance in online signature verification.
FETNet: Feature Erasing and Transferring Network for Scene Text Removal
Jun 16, 2023



The scene text removal (STR) task aims to remove text regions and recover the background smoothly in images for private information protection. Most existing STR methods adopt encoder-decoder-based CNNs, with direct copies of the features in the skip connections. However, the encoded features contain both text texture and structure information. The insufficient utilization of text features hampers the performance of background reconstruction in text removal regions. To tackle these problems, we propose a novel Feature Erasing and Transferring (FET) mechanism to reconfigure the encoded features for STR in this paper. In FET, a Feature Erasing Module (FEM) is designed to erase text features. An attention module is responsible for generating the feature similarity guidance. The Feature Transferring Module (FTM) is introduced to transfer the corresponding features in different layers based on the attention guidance. With this mechanism, a one-stage, end-to-end trainable network called FETNet is constructed for scene text removal. In addition, to facilitate research on both scene text removal and segmentation tasks, we introduce a novel dataset, Flickr-ST, with multi-category annotations. A sufficient number of experiments and ablation studies are conducted on the public datasets and Flickr-ST. Our proposed method achieves state-of-the-art performance using most metrics, with remarkably higher quality scene text removal results. The source code of our work is available at: \href{https://github.com/GuangtaoLyu/FETNet}{https://github.com/GuangtaoLyu/FETNet.
* Accepted by Pattern Recognition 2023
Vision Conformer: Incorporating Convolutions into Vision Transformer Layers
Apr 27, 2023



Transformers are popular neural network models that use layers of self-attention and fully-connected nodes with embedded tokens. Vision Transformers (ViT) adapt transformers for image recognition tasks. In order to do this, the images are split into patches and used as tokens. One issue with ViT is the lack of inductive bias toward image structures. Because ViT was adapted for image data from language modeling, the network does not explicitly handle issues such as local translations, pixel information, and information loss in the structures and features shared by multiple patches. Conversely, Convolutional Neural Networks (CNN) incorporate this information. Thus, in this paper, we propose the use of convolutional layers within ViT. Specifically, we propose a model called a Vision Conformer (ViC) which replaces the Multi-Layer Perceptron (MLP) in a ViT layer with a CNN. In addition, to use the CNN, we proposed to reconstruct the image data after the self-attention in a reverse embedding layer. Through the evaluation, we demonstrate that the proposed convolutions help improve the classification ability of ViT.
Contour Completion by Transformers and Its Application to Vector Font Data
Apr 27, 2023In documents and graphics, contours are a popular format to describe specific shapes. For example, in the True Type Font (TTF) file format, contours describe vector outlines of typeface shapes. Each contour is often defined as a sequence of points. In this paper, we tackle the contour completion task. In this task, the input is a contour sequence with missing points, and the output is a generated completed contour. This task is more difficult than image completion because, for images, the missing pixels are indicated. Since there is no such indication in the contour completion task, we must solve the problem of missing part detection and completion simultaneously. We propose a Transformer-based method to solve this problem and show the results of the typeface contour completion.
On Mini-Batch Training with Varying Length Time Series
Dec 13, 2022



In real-world time series recognition applications, it is possible to have data with varying length patterns. However, when using artificial neural networks (ANN), it is standard practice to use fixed-sized mini-batches. To do this, time series data with varying lengths are typically normalized so that all the patterns are the same length. Normally, this is done using zero padding or truncation without much consideration. We propose a novel method of normalizing the lengths of the time series in a dataset by exploiting the dynamic matching ability of Dynamic Time Warping (DTW). In this way, the time series lengths in a dataset can be set to a fixed size while maintaining features typical to the dataset. In the experiments, all 11 datasets with varying length time series from the 2018 UCR Time Series Archive are used. We evaluate the proposed method by comparing it with 18 other length normalization methods on a Convolutional Neural Network (CNN), a Long-Short Term Memory network (LSTM), and a Bidirectional LSTM (BLSTM).
Dynamic Data Augmentation with Gating Networks
Nov 05, 2021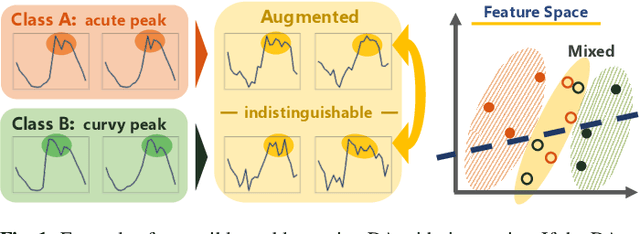
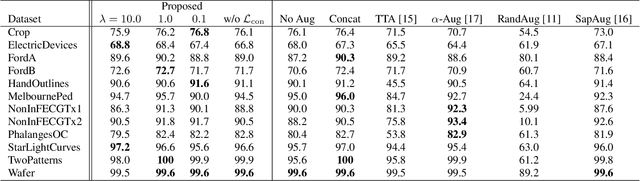
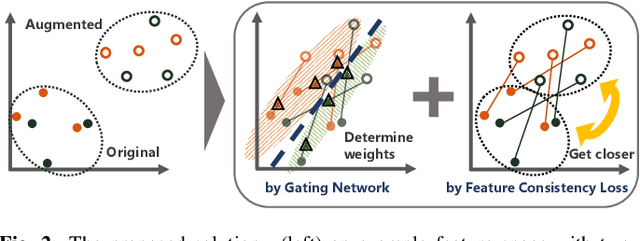
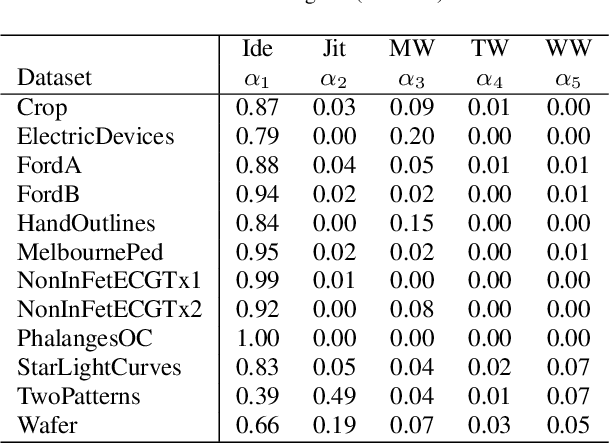
Data augmentation is a technique to improve the generalization ability of machine learning methods by increasing the size of the dataset. However, since every augmentation method is not equally effective for every dataset, you need to carefully select the best method. We propose a neural network that dynamically selects the best combination using a mutually beneficial gating network and a feature consistency loss. The gating network is able to control how much of each data augmentation is used for the representation within the network. The feature consistency loss, on the other hand, gives a constraint that augmented features from the same input should be in similar. In experiments, we demonstrate the effectiveness of the proposed method on the 12 largest time-series datasets from 2018 UCR Time Series Archive and reveal the relationships between the data augmentation methods through analysis of the proposed method.