 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQAHOI: Query-Based Anchors for Human-Object Interaction Detection
Paper and Code
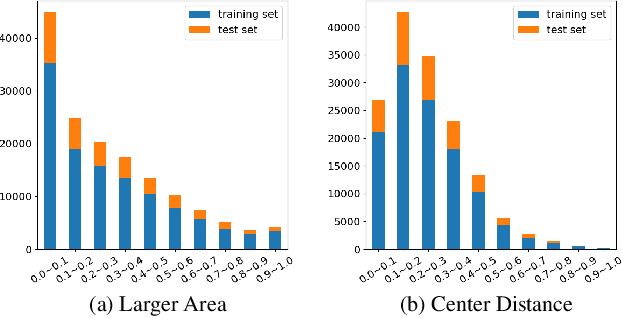
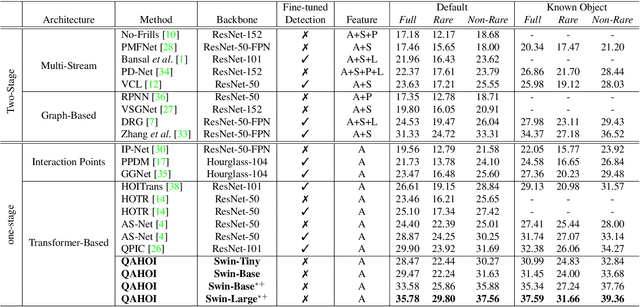
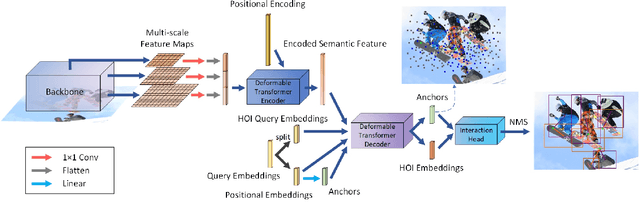
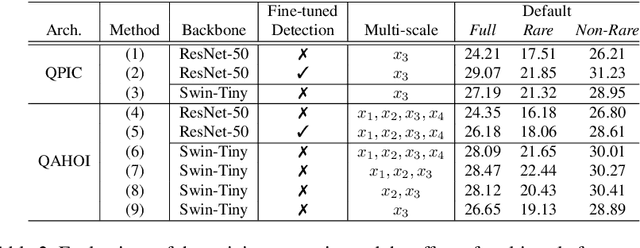
Human-object interaction (HOI) detection as a downstream of object detection tasks requires localizing pairs of humans and objects and extracting the semantic relationships between humans and objects from an image. Recently, one-stage approaches have become a new trend for this task due to their high efficiency. However, these approaches focus on detecting possible interaction points or filtering human-object pairs, ignoring the variability in the location and size of different objects at spatial scales. To address this problem, we propose a transformer-based method, QAHOI (Query-Based Anchors for Human-Object Interaction detection), which leverages a multi-scale architecture to extract features from different spatial scales and uses query-based anchors to predict all the elements of an HOI instance. We further investigate that a powerful backbone significantly increases accuracy for QAHOI, and QAHOI with a transformer-based backbone outperforms recent state-of-the-art methods by large margins on the HICO-DET benchmark. The source code is available at $\href{https://github.com/cjw2021/QAHOI}{\text{this https URL}}$.