 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPN Hand: A Video Dataset and Benchmark for Real-Time Continuous Hand Gesture Recognition
Apr 20, 2020


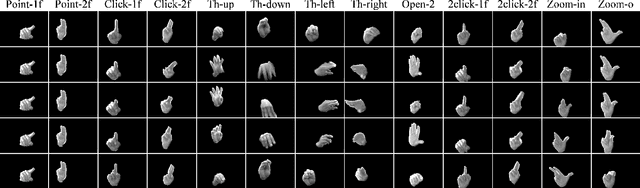
In the research community of continuous hand gesture recognition (HGR), the current publicly available datasets lack real-world elements needed to build responsive and efficient HGR systems. In this paper, we introduce a new benchmark dataset named IPN Hand with sufficient size, variation, and real-world elements able to train and evaluate deep neural networks. This dataset contains more than 4 000 gesture samples and 800 000 RGB frames from 50 distinct subjects. We design 13 different static and dynamic gestures focused on interaction with touchless screens. We especially consider the scenario when continuous gestures are performed without transition states, and when subjects perform natural movements with their hands as non-gesture actions. Gestures were collected from about 30 diverse scenes, with real-world variation in background and illumination. With our dataset, the performance of three 3D-CNN models is evaluated on the tasks of isolated and continuous real-time HGR. Furthermore, we analyze the possibility of increasing the recognition accuracy by adding multiple modalities derived from RGB frames, i.e., optical flow and semantic segmentation, while keeping the real-time performance of the 3D-CNN model. Our empirical study also provides a comparison with the publicly available nvGesture (NVIDIA) dataset. The experimental results show that the state-of-the-art ResNext-101 model decreases about 30% accuracy when using our real-world dataset, demonstrating that the IPN Hand dataset can be used as a benchmark, and may help the community to step forward in the continuous HGR. Our dataset and pre-trained models used in the evaluation are publicly available at https://github.com/GibranBenitez/IPN-hand.
Iconify: Converting Photographs into Icons
Apr 07, 2020
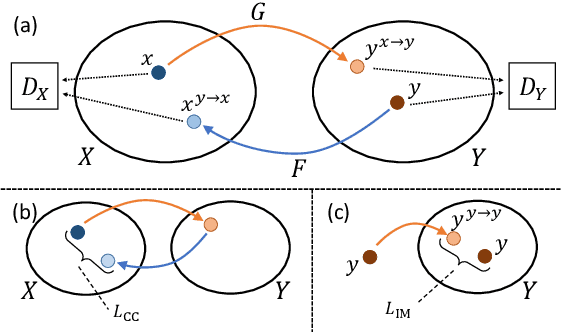
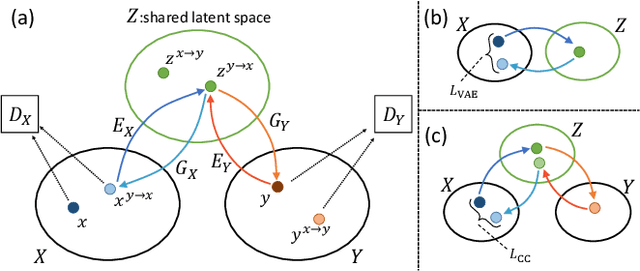

In this paper, we tackle a challenging domain conversion task between photo and icon images. Although icons often originate from real object images (i.e., photographs), severe abstractions and simplifications are applied to generate icon images by professional graphic designers. Moreover, there is no one-to-one correspondence between the two domains, for this reason we cannot use it as the ground-truth for learning a direct conversion function. Since generative adversarial networks (GAN) can undertake the problem of domain conversion without any correspondence, we test CycleGAN and UNIT to generate icons from objects segmented from photo images. Our experiments with several image datasets prove that CycleGAN learns sufficient abstraction and simplification ability to generate icon-like images.