 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeType-R: Automatically Retouching Typos for Text-to-Image Generation
Nov 27, 2024While recent text-to-image models can generate photorealistic images from text prompts that reflect detailed instructions, they still face significant challenges in accurately rendering words in the image. In this paper, we propose to retouch erroneous text renderings in the post-processing pipeline. Our approach, called Type-R, identifies typographical errors in the generated image, erases the erroneous text, regenerates text boxes for missing words, and finally corrects typos in the rendered words. Through extensive experiments, we show that Type-R, in combination with the latest text-to-image models such as Stable Diffusion or Flux, achieves the highest text rendering accuracy while maintaining image quality and also outperforms text-focused generation baselines in terms of balancing text accuracy and image quality.
Can GPTs Evaluate Graphic Design Based on Design Principles?
Oct 11, 2024Recent advancements in foundation models show promising capability in graphic design generation. Several studies have started employing Large Multimodal Models (LMMs) to evaluate graphic designs, assuming that LMMs can properly assess their quality, but it is unclear if the evaluation is reliable. One way to evaluate the quality of graphic design is to assess whether the design adheres to fundamental graphic design principles, which are the designer's common practice. In this paper, we compare the behavior of GPT-based evaluation and heuristic evaluation based on design principles using human annotations collected from 60 subjects. Our experiments reveal that, while GPTs cannot distinguish small details, they have a reasonably good correlation with human annotation and exhibit a similar tendency to heuristic metrics based on design principles, suggesting that they are indeed capable of assessing the quality of graphic design. Our dataset is available at https://cyberagentailab.github.io/Graphic-design-evaluation .
OpenCOLE: Towards Reproducible Automatic Graphic Design Generation
Jun 12, 2024



Automatic generation of graphic designs has recently received considerable attention. However, the state-of-the-art approaches are complex and rely on proprietary datasets, which creates reproducibility barriers. In this paper, we propose an open framework for automatic graphic design called OpenCOLE, where we build a modified version of the pioneering COLE and train our model exclusively on publicly available datasets. Based on GPT4V evaluations, our model shows promising performance comparable to the original COLE. We release the pipeline and training results to encourage open development.
Total Disentanglement of Font Images into Style and Character Class Features
Mar 19, 2024In this paper, we demonstrate a total disentanglement of font images. Total disentanglement is a neural network-based method for decomposing each font image nonlinearly and completely into its style and content (i.e., character class) features. It uses a simple but careful training procedure to extract the common style feature from all `A'-`Z' images in the same font and the common content feature from all `A' (or another class) images in different fonts. These disentangled features guarantee the reconstruction of the original font image. Various experiments have been conducted to understand the performance of total disentanglement. First, it is demonstrated that total disentanglement is achievable with very high accuracy; this is experimental proof of the long-standing open question, ``Does `A'-ness exist?'' Hofstadter (1985). Second, it is demonstrated that the disentangled features produced by total disentanglement apply to a variety of tasks, including font recognition, character recognition, and one-shot font image generation.
Image Cropping under Design Constraints
Oct 13, 2023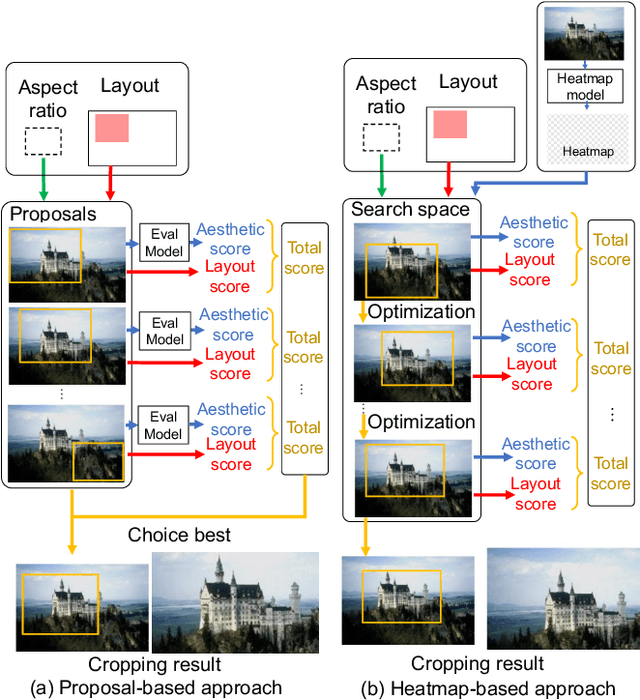
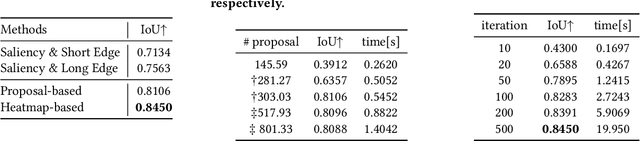

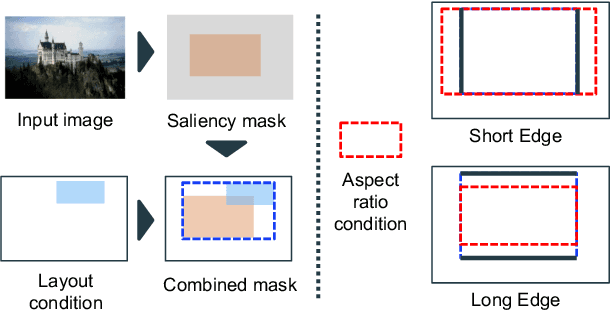
Image cropping is essential in image editing for obtaining a compositionally enhanced image. In display media, image cropping is a prospective technique for automatically creating media content. However, image cropping for media contents is often required to satisfy various constraints, such as an aspect ratio and blank regions for placing texts or objects. We call this problem image cropping under design constraints. To achieve image cropping under design constraints, we propose a score function-based approach, which computes scores for cropped results whether aesthetically plausible and satisfies design constraints. We explore two derived approaches, a proposal-based approach, and a heatmap-based approach, and we construct a dataset for evaluating the performance of the proposed approaches on image cropping under design constraints. In experiments, we demonstrate that the proposed approaches outperform a baseline, and we observe that the proposal-based approach is better than the heatmap-based approach under the same computation cost, but the heatmap-based approach leads to better scores by increasing computation cost. The experimental results indicate that balancing aesthetically plausible regions and satisfying design constraints is not a trivial problem and requires sensitive balance, and both proposed approaches are reasonable alternatives.
Towards Diverse and Consistent Typography Generation
Sep 05, 2023



In this work, we consider the typography generation task that aims at producing diverse typographic styling for the given graphic document. We formulate typography generation as a fine-grained attribute generation for multiple text elements and build an autoregressive model to generate diverse typography that matches the input design context. We further propose a simple yet effective sampling approach that respects the consistency and distinction principle of typography so that generated examples share consistent typographic styling across text elements. Our empirical study shows that our model successfully generates diverse typographic designs while preserving a consistent typographic structure.
De-rendering Stylized Texts
Oct 05, 2021
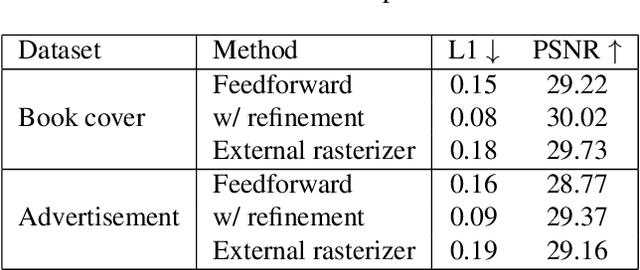
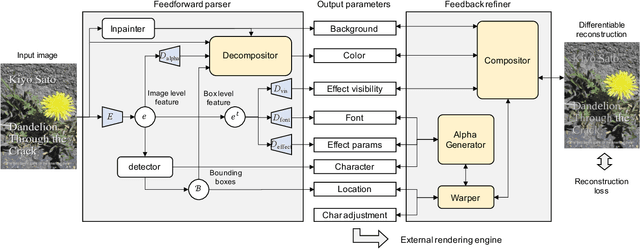

Editing raster text is a promising but challenging task. We propose to apply text vectorization for the task of raster text editing in display media, such as posters, web pages, or advertisements. In our approach, instead of applying image transformation or generation in the raster domain, we learn a text vectorization model to parse all the rendering parameters including text, location, size, font, style, effects, and hidden background, then utilize those parameters for reconstruction and any editing task. Our text vectorization takes advantage of differentiable text rendering to accurately reproduce the input raster text in a resolution-free parametric format. We show in the experiments that our approach can successfully parse text, styling, and background information in the unified model, and produces artifact-free text editing compared to a raster baseline.
Self-Supervised Difference Detection for Weakly-Supervised Semantic Segmentation
Nov 12, 2019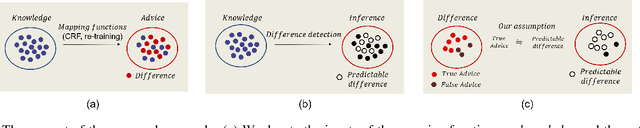

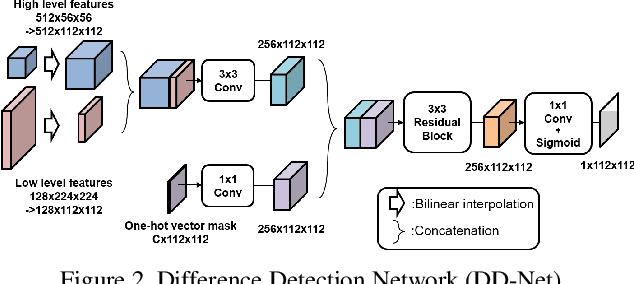
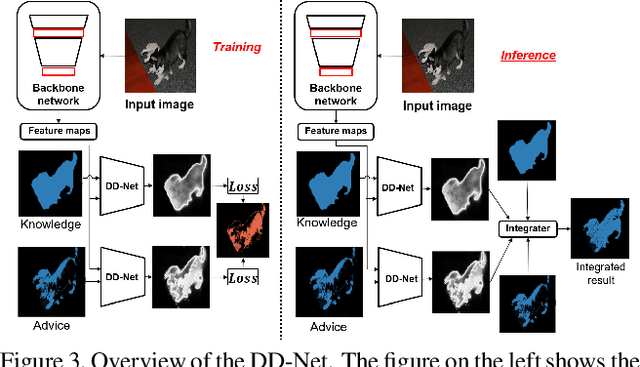
To minimize the annotation costs associated with the training of semantic segmentation models, researchers have extensively investigated weakly-supervised segmentation approaches. In the current weakly-supervised segmentation methods, the most widely adopted approach is based on visualization. However, the visualization results are not generally equal to semantic segmentation. Therefore, to perform accurate semantic segmentation under the weakly supervised condition, it is necessary to consider the mapping functions that convert the visualization results into semantic segmentation. For such mapping functions, the conditional random field and iterative re-training using the outputs of a segmentation model are usually used. However, these methods do not always guarantee improvements in accuracy; therefore, if we apply these mapping functions iteratively multiple times, eventually the accuracy will not improve or will decrease. In this paper, to make the most of such mapping functions, we assume that the results of the mapping function include noise, and we improve the accuracy by removing noise. To achieve our aim, we propose the self-supervised difference detection module, which estimates noise from the results of the mapping functions by predicting the difference between the segmentation masks before and after the mapping. We verified the effectiveness of the proposed method by performing experiments on the PASCAL Visual Object Classes 2012 dataset, and we achieved 64.9\% in the val set and 65.5\% in the test set. Both of the results become new state-of-the-art under the same setting of weakly supervised semantic segmentation.
An Integration of Bottom-up and Top-Down Salient Cues on RGB-D Data: Saliency from Objectness vs. Non-Objectness
Jul 04, 2018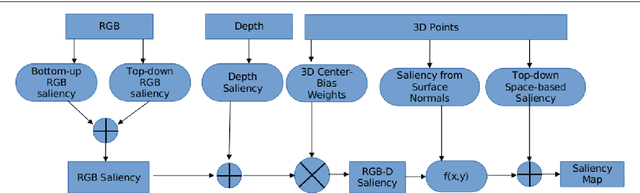


Bottom-up and top-down visual cues are two types of information that helps the visual saliency models. These salient cues can be from spatial distributions of the features (space-based saliency) or contextual / task-dependent features (object based saliency). Saliency models generally incorporate salient cues either in bottom-up or top-down norm separately. In this work, we combine bottom-up and top-down cues from both space and object based salient features on RGB-D data. In addition, we also investigated the ability of various pre-trained convolutional neural networks for extracting top-down saliency on color images based on the object dependent feature activation. We demonstrate that combining salient features from color and dept through bottom-up and top-down methods gives significant improvement on the salient object detection with space based and object based salient cues. RGB-D saliency integration framework yields promising results compared with the several state-of-the-art-models.
* 9 pages, 3 figures, 3 tables, This work includes the accepted version content of the paper published in journal of Signal Image and Video Processing (SIViP, Springer), Vol. 12, Issue 2, pp 307-314, Feb 2018 (DOI: https://doi.org/10.1007/s11760-017-1159-7)
Saliency Detection by Forward and Backward Cues in Deep-CNNs
Jun 21, 2017


As prior knowledge of objects or object features helps us make relations for similar objects on attentional tasks, pre-trained deep convolutional neural networks (CNNs) can be used to detect salient objects on images regardless of the object class is in the network knowledge or not. In this paper, we propose a top-down saliency model using CNN, a weakly supervised CNN model trained for 1000 object labelling task from RGB images. The model detects attentive regions based on their objectness scores predicted by selected features from CNNs. To estimate the salient objects effectively, we combine both forward and backward features, while demonstrating that partially-guided backpropagation will provide sufficient information for selecting the features from forward run of CNN model. Finally, these top-down cues are enhanced with a state-of-the-art bottom-up model as complementing the overall saliency. As the proposed model is an effective integration of forward and backward cues through objectness without any supervision or regression to ground truth data, it gives promising results compared to state-of-the-art models in two different datasets.