 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Adaptive Retrieval over Agentic Multi-Modal Web Histories via Learned Graph Memory
Apr 09, 2026Retrieving relevant observations from long multi-modal web interaction histories is challenging because relevance depends on the evolving task state, modality (screenshots, HTML text, structured signals), and temporal distance. Prior approaches typically rely on static similarity thresholds or fixed-capacity buffers, which fail to adapt relevance to the current task context. We propose \textbf{ACGM}, a learned graph-memory retriever that constructs \emph{task-adaptive} relevance graphs over agent histories using policy-gradient optimization from downstream task success. ACGM captures heterogeneous temporal dynamics with modality-specific decay (visual decays $4.3\times$ faster than text: $λ_v{=}0.47$ vs.\ $λ_x{=}0.11$) and learns sparse connectivity (3.2 edges/node), enabling efficient $O(\log T)$ retrieval. Across WebShop, VisualWebArena, and Mind2Web, ACGM improves retrieval quality to \textbf{82.7 nDCG@10} (+9.3 over GPT-4o, $p{<}0.001$) and \textbf{89.2\% Precision@10} (+7.7), outperforming 19 strong dense, re-ranking, multi-modal, and graph-based baselines. Code to reproduce our results is available at{\color{blue}\href{https://github.com/S-Forouzandeh/ACGM-Agentic-Web}{Saman Forouzandeh}}.
AC2L-GAD: Active Counterfactual Contrastive Learning for Graph Anomaly Detection
Jan 29, 2026Graph anomaly detection aims to identify abnormal patterns in networks, but faces significant challenges from label scarcity and extreme class imbalance. While graph contrastive learning offers a promising unsupervised solution, existing methods suffer from two critical limitations: random augmentations break semantic consistency in positive pairs, while naive negative sampling produces trivial, uninformative contrasts. We propose AC2L-GAD, an Active Counterfactual Contrastive Learning framework that addresses both limitations through principled counterfactual reasoning. By combining information-theoretic active selection with counterfactual generation, our approach identifies structurally complex nodes and generates anomaly-preserving positive augmentations alongside normal negative counterparts that provide hard contrasts, while restricting expensive counterfactual generation to a strategically selected subset. This design reduces computational overhead by approximately 65% compared to full-graph counterfactual generation while maintaining detection quality. Experiments on nine benchmark datasets, including real-world financial transaction graphs from GADBench, show that AC2L-GAD achieves competitive or superior performance compared to state-of-the-art baselines, with notable gains in datasets where anomalies exhibit complex attribute-structure interactions.
Learning Hierarchical Procedural Memory for LLM Agents through Bayesian Selection and Contrastive Refinement
Dec 22, 2025We present MACLA, a framework that decouples reasoning from learning by maintaining a frozen large language model while performing all adaptation in an external hierarchical procedural memory. MACLA extracts reusable procedures from trajectories, tracks reliability via Bayesian posteriors, selects actions through expected-utility scoring, and refines procedures by contrasting successes and failures. Across four benchmarks (ALFWorld, WebShop, TravelPlanner, InterCodeSQL), MACLA achieves 78.1 percent average performance, outperforming all baselines. On ALFWorld unseen tasks, MACLA reaches 90.3 percent with 3.1 percent positive generalization. The system constructs memory in 56 seconds, 2800 times faster than the state-of-the-art LLM parameter-training baseline, compressing 2851 trajectories into 187 procedures. Experimental results demonstrate that structured external memory with Bayesian selection and contrastive refinement enables sample-efficient, interpretable, and continually improving agents without LLM parameter updates.
Learning Network Dismantling without Handcrafted Inputs
Aug 01, 2025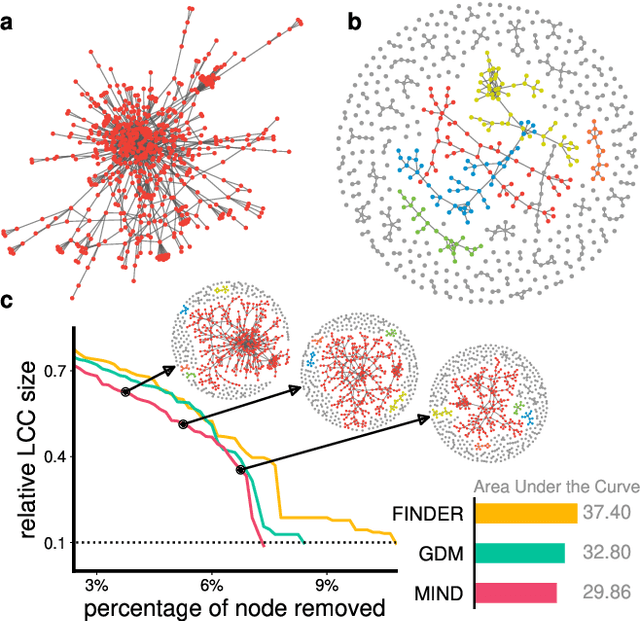

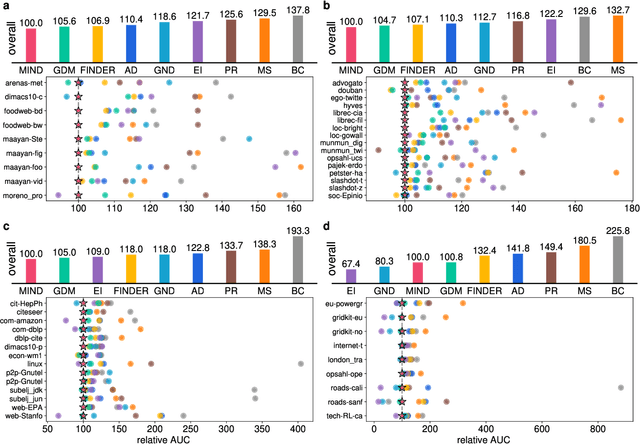
The application of message-passing Graph Neural Networks has been a breakthrough for important network science problems. However, the competitive performance often relies on using handcrafted structural features as inputs, which increases computational cost and introduces bias into the otherwise purely data-driven network representations. Here, we eliminate the need for handcrafted features by introducing an attention mechanism and utilizing message-iteration profiles, in addition to an effective algorithmic approach to generate a structurally diverse training set of small synthetic networks. Thereby, we build an expressive message-passing framework and use it to efficiently solve the NP-hard problem of Network Dismantling, virtually equivalent to vital node identification, with significant real-world applications. Trained solely on diversified synthetic networks, our proposed model -- MIND: Message Iteration Network Dismantler -- generalizes to large, unseen real networks with millions of nodes, outperforming state-of-the-art network dismantling methods. Increased efficiency and generalizability of the proposed model can be leveraged beyond dismantling in a range of complex network problems.
Resource Constrained Pathfinding with A* and Negative Weights
Mar 14, 2025Constrained pathfinding is a well-studied, yet challenging network optimisation problem that can be seen in a broad range of real-world applications. Pathfinding with multiple resource limits, which is known as the Resource Constrained Shortest Path Problem (RCSP), aims to plan a cost-optimum path subject to limited usage of resources. Given the recent advances in constrained and multi-criteria search with A*, this paper introduces a new resource constrained search framework on the basis of A* to tackle RCSP in large networks, even in the presence of negative cost and negative resources. We empirically evaluate our new algorithm on a set of large instances and show up to two orders of magnitude faster performance compared to state-of-the-art RCSP algorithms in the literature.
Parallelizing Multi-objective A* Search
Mar 13, 2025The Multi-objective Shortest Path (MOSP) problem is a classic network optimization problem that aims to find all Pareto-optimal paths between two points in a graph with multiple edge costs. Recent studies on multi-objective search with A* (MOA*) have demonstrated superior performance in solving difficult MOSP instances. This paper presents a novel search framework that allows efficient parallelization of MOA* with different objective orders. The framework incorporates a unique upper bounding strategy that helps the search reduce the problem's dimensionality to one in certain cases. Experimental results demonstrate that the proposed framework can enhance the performance of recent A*-based solutions, with the speed-up proportional to the problem dimension.
Resource Constrained Pathfinding with Enhanced Bidirectional A* Search
Dec 18, 2024The classic Resource Constrained Shortest Path (RCSP) problem aims to find a cost optimal path between a pair of nodes in a network such that the resources used in the path are within a given limit. Having been studied for over a decade, RCSP has seen recent solutions that utilize heuristic-guided search to solve the constrained problem faster. Building upon the bidirectional A* search paradigm, this research introduces a novel constrained search framework that uses efficient pruning strategies to allow for accelerated and effective RCSP search in large-scale networks. Results show that, compared to the state of the art, our enhanced framework can significantly reduce the constrained search time, achieving speed-ups of over to two orders of magnitude.
Real-Time Energy-Optimal Path Planning for Electric Vehicles
Nov 20, 2024The rapid adoption of electric vehicles (EVs) in modern transport systems has made energy-aware routing a critical task in their successful integration, especially within large-scale networks. In cases where an EV's remaining energy is limited and charging locations are not easily accessible, some destinations may only be reachable through an energy-optimal path: a route that consumes less energy than all other alternatives. The feasibility of such energy-efficient paths depends heavily on the accuracy of the energy model used for planning, and thus failing to account for vehicle dynamics can lead to inaccurate energy estimates, rendering some planned routes infeasible in reality. This paper explores the impact of vehicle dynamics on energy-optimal path planning for EVs. We develop an accurate energy model that incorporates key vehicle dynamics parameters into energy calculations, thereby reducing the risk of planning infeasible paths under battery constraints. The paper also introduces two novel online reweighting functions that allow for a faster, pre-processing free, pathfinding in the presence of negative energy costs resulting from regenerative braking, making them ideal for real-time applications. Through extensive experimentation on real-world transport networks, we demonstrate that our approach considerably enhances energy-optimal pathfinding for EVs in both computational efficiency and energy estimation accuracy.
Online Electric Vehicle Charging Detection Based on Memory-based Transformer using Smart Meter Data
Aug 06, 2024The growing popularity of Electric Vehicles (EVs) poses unique challenges for grid operators and infrastructure, which requires effectively managing these vehicles' integration into the grid. Identification of EVs charging is essential to electricity Distribution Network Operators (DNOs) for better planning and managing the distribution grid. One critical aspect is the ability to accurately identify the presence of EV charging in the grid. EV charging identification using smart meter readings obtained from behind-the-meter devices is a challenging task that enables effective managing the integration of EVs into the existing power grid. Different from the existing supervised models that require addressing the imbalance problem caused by EVs and non-EVs data, we propose a novel unsupervised memory-based transformer (M-TR) that can run in real-time (online) to detect EVs charging from a streaming smart meter. It dynamically leverages coarse-scale historical information using an M-TR encoder from an extended global temporal window, in conjunction with an M-TR decoder that concentrates on a limited time frame, local window, aiming to capture the fine-scale characteristics of the smart meter data. The M-TR is based on an anomaly detection technique that does not require any prior knowledge about EVs charging profiles, nor it does only require real power consumption data of non-EV users. In addition, the proposed model leverages the power of transfer learning. The M-TR is compared with different state-of-the-art methods and performs better than other unsupervised learning models. The model can run with an excellent execution time of 1.2 sec. for 1-minute smart recordings.
Clustering-based Multitasking Deep Neural Network for Solar Photovoltaics Power Generation Prediction
May 09, 2024The increasing installation of Photovoltaics (PV) cells leads to more generation of renewable energy sources (RES), but results in increased uncertainties of energy scheduling. Predicting PV power generation is important for energy management and dispatch optimization in smart grid. However, the PV power generation data is often collected across different types of customers (e.g., residential, agricultural, industrial, and commercial) while the customer information is always de-identified. This often results in a forecasting model trained with all PV power generation data, allowing the predictor to learn various patterns through intra-model self-learning, instead of constructing a separate predictor for each customer type. In this paper, we propose a clustering-based multitasking deep neural network (CM-DNN) framework for PV power generation prediction. K-means is applied to cluster the data into different customer types. For each type, a deep neural network (DNN) is employed and trained until the accuracy cannot be improved. Subsequently, for a specified customer type (i.e., the target task), inter-model knowledge transfer is conducted to enhance its training accuracy. During this process, source task selection is designed to choose the optimal subset of tasks (excluding the target customer), and each selected source task uses a coefficient to determine the amount of DNN model knowledge (weights and biases) transferred to the aimed prediction task. The proposed CM-DNN is tested on a real-world PV power generation dataset and its superiority is demonstrated by comparing the prediction performance on training the dataset with a single model without clustering.