 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Asymmetric Embedding for Attributed Networks via Convolutional Neural Network
Feb 13, 2022

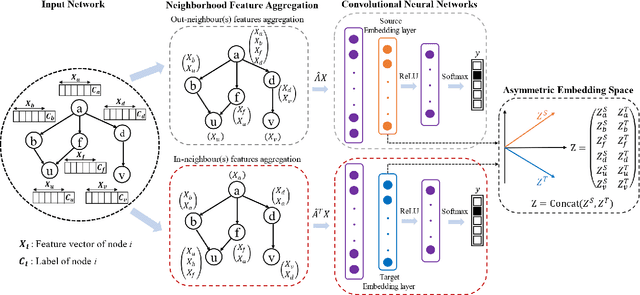
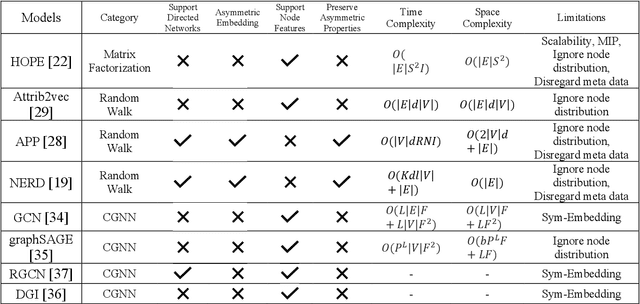
Recently network embedding has gained increasing attention due to its advantages in facilitating network computation tasks such as link prediction, node classification and node clustering. The objective of network embedding is to represent network nodes in a low-dimensional vector space while retaining as much information as possible from the original network including structural, relational, and semantic information. However, asymmetric nature of directed networks poses many challenges as how to best preserve edge directions in the embedding process. Here, we propose a novel deep asymmetric attributed network embedding model based on convolutional graph neural network, called AAGCN. The main idea is to maximally preserve the asymmetric proximity and asymmetric similarity of directed attributed networks. AAGCN introduces two neighbourhood feature aggregation schemes to separately aggregate the features of a node with the features of its in- and out- neighbours. Then, it learns two embedding vectors for each node, one source embedding vector and one target embedding vector. The final representations are the results of concatenating source and target embedding vectors. We test the performance of AAGCN on three real-world networks for network reconstruction, link prediction, node classification and visualization tasks. The experimental results show the superiority of AAGCN against state-of-the-art embedding methods.
Vital Node Identification in Complex Networks Using a Machine Learning-Based Approach
Feb 13, 2022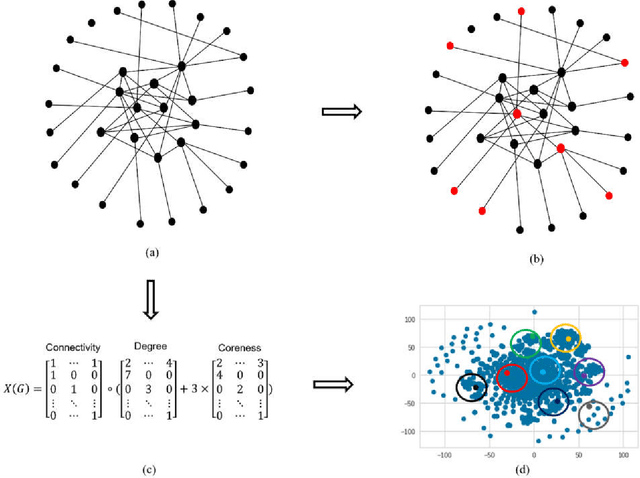
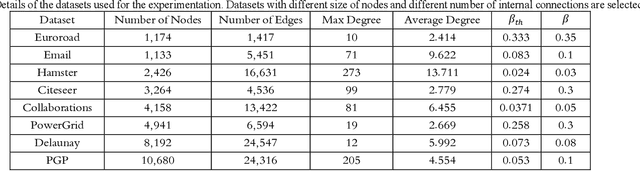
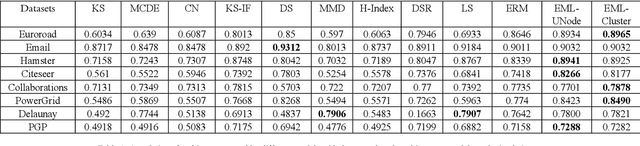
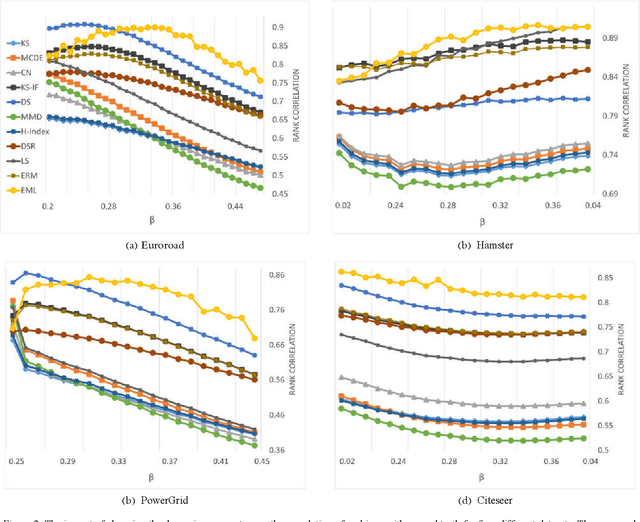
Vital node identification is the problem of finding nodes of highest importance in complex networks. This problem has crucial applications in various contexts such as viral marketing or controlling the propagation of virus or rumours in real-world networks. Existing approaches for vital node identification mainly focus on capturing the importance of a node through a mathematical expression which directly relates structural properties of the node to its vitality. Although these heuristic approaches have achieved good performance in practice, they have weak adaptability, and their performance is limited to specific settings and certain dynamics. Inspired by the power of machine learning models for efficiently capturing different types of patterns and relations, we propose a machine learning-based, data driven approach for vital node identification. The main idea is to train the model with a small portion of the graph, say 0.5% of the nodes, and do the prediction on the rest of the nodes. The ground-truth vitality for the train data is computed by simulating the SIR diffusion method starting from the train nodes. We use collective feature engineering where each node in the network is represented by incorporating elements of its connectivity, degree and extended coreness. Several machine learning models are trained on the node representations, but the best results are achieved by a Support Vector Regression machine with RBF kernel. The empirical results confirms that the proposed model outperforms state-of-the-art models on a selection of datasets, while it also shows more adaptability to changes in the dynamics parameters.
Adversarial Graph Embeddings for Fair Influence Maximization over Social Networks
May 11, 2020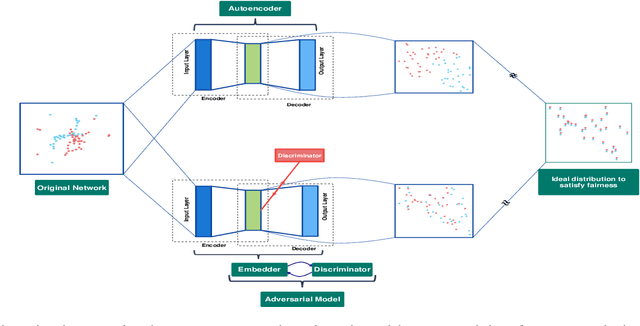
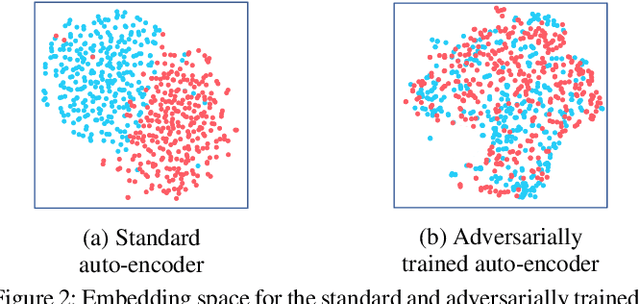
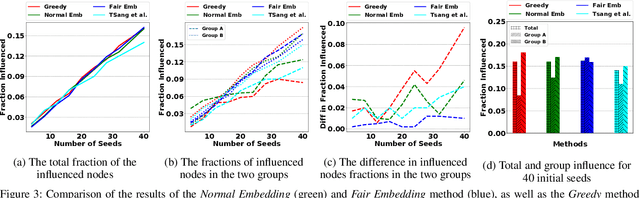
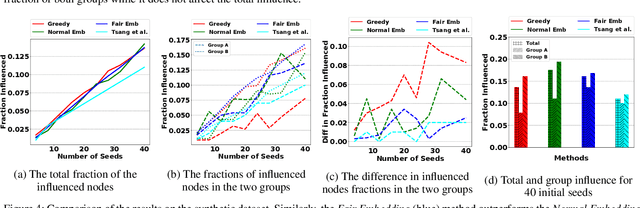
Influence maximization is a widely studied topic in network science, where the aim is to reach the maximum possible number of nodes, while only targeting a small initial set of individuals. It has critical applications in many fields, including viral marketing, information propagation, news dissemination, and vaccinations. However, the objective does not usually take into account whether the final set of influenced nodes is fair with respect to sensitive attributes, such as race or gender. Here we address fair influence maximization, aiming to reach minorities more equitably. We introduce Adversarial Graph Embeddings: we co-train an auto-encoder for graph embedding and a discriminator to discern sensitive attributes. This leads to embeddings which are similarly distributed across sensitive attributes. We then find a good initial set by clustering the embeddings. We believe we are the first to use embeddings for the task of fair influence maximization. While there are typically trade-offs between fairness and influence maximization objectives, our experiments on synthetic and real-world datasets show that our approach dramatically reduces disparity while remaining competitive with state-of-the-art influence maximization methods.