 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossWalk: Fairness-enhanced Node Representation Learning
May 06, 2021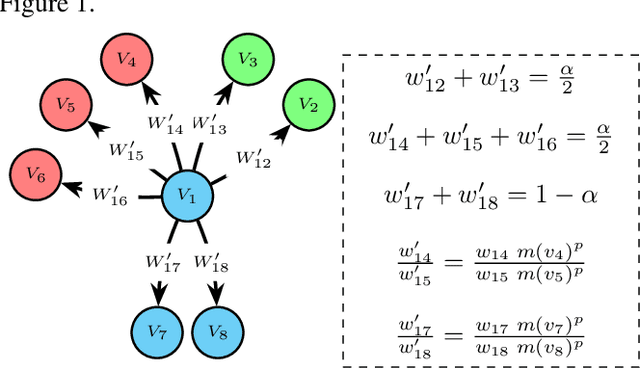
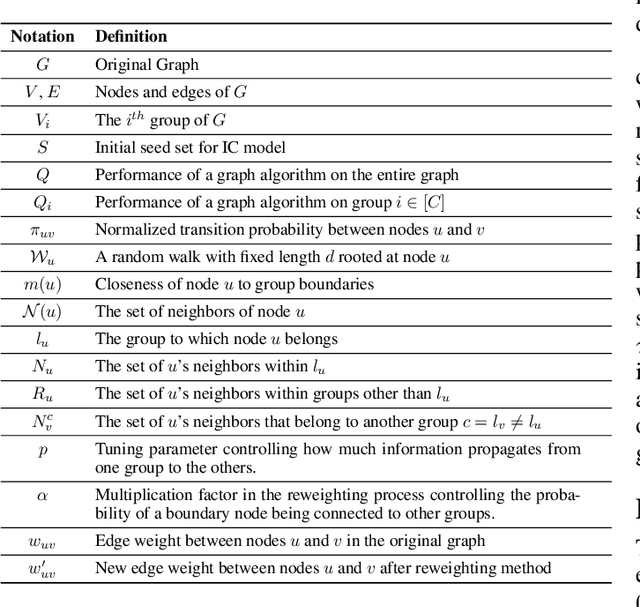
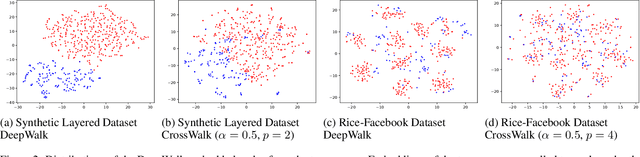
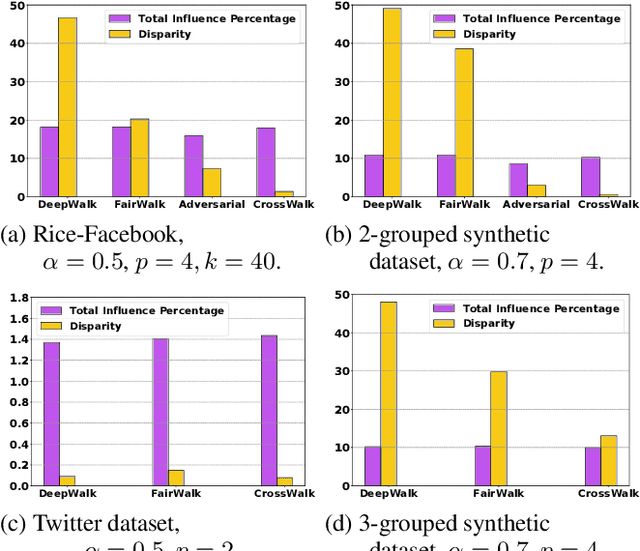
The potential for machine learning systems to amplify social inequities and unfairness is receiving increasing popular and academic attention. Much recent work has focused on developing algorithmic tools to assess and mitigate such unfairness. However, there is little work on enhancing fairness in graph algorithms. Here, we develop a simple, effective and general method, CrossWalk, that enhances fairness of various graph algorithms, including influence maximization, link prediction and node classification, applied to node embeddings. CrossWalk is applicable to any random walk based node representation learning algorithm, such as DeepWalk and Node2Vec. The key idea is to bias random walks to cross group boundaries, by upweighting edges which (1) are closer to the groups' peripheries or (2) connect different groups in the network. CrossWalk pulls nodes that are near groups' peripheries towards their neighbors from other groups in the embedding space, while preserving the necessary structural information from the graph. Extensive experiments show the effectiveness of our algorithm to enhance fairness in various graph algorithms, including influence maximization, link prediction and node classification in synthetic and real networks, with only a very small decrease in performance.
Adversarial Graph Embeddings for Fair Influence Maximization over Social Networks
May 11, 2020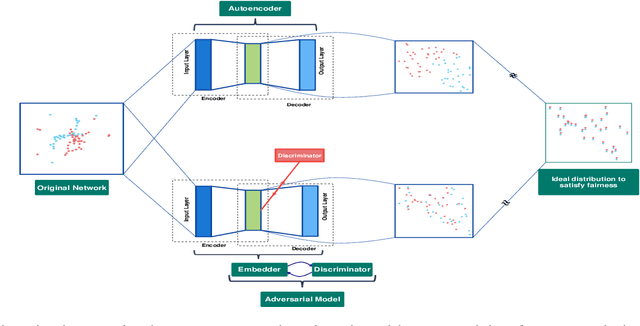
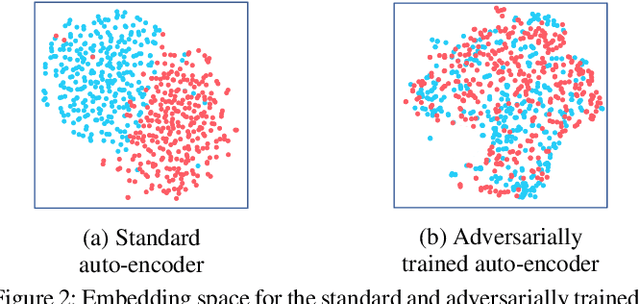
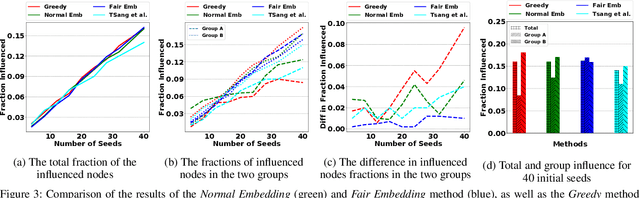
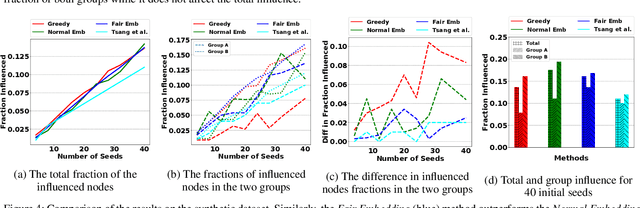
Influence maximization is a widely studied topic in network science, where the aim is to reach the maximum possible number of nodes, while only targeting a small initial set of individuals. It has critical applications in many fields, including viral marketing, information propagation, news dissemination, and vaccinations. However, the objective does not usually take into account whether the final set of influenced nodes is fair with respect to sensitive attributes, such as race or gender. Here we address fair influence maximization, aiming to reach minorities more equitably. We introduce Adversarial Graph Embeddings: we co-train an auto-encoder for graph embedding and a discriminator to discern sensitive attributes. This leads to embeddings which are similarly distributed across sensitive attributes. We then find a good initial set by clustering the embeddings. We believe we are the first to use embeddings for the task of fair influence maximization. While there are typically trade-offs between fairness and influence maximization objectives, our experiments on synthetic and real-world datasets show that our approach dramatically reduces disparity while remaining competitive with state-of-the-art influence maximization methods.