 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHi-DREAM: Brain Inspired Hierarchical Diffusion for fMRI Reconstruction via ROI Encoder and visuAl Mapping
Nov 14, 2025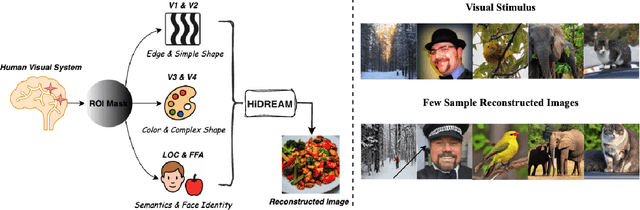
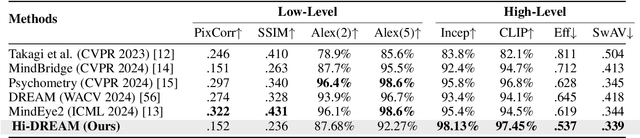
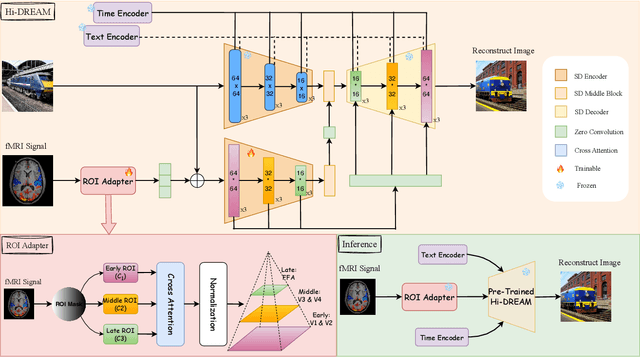
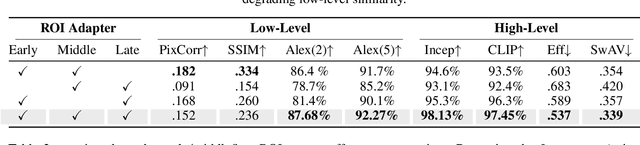
Mapping human brain activity to natural images offers a new window into vision and cognition, yet current diffusion-based decoders face a core difficulty: most condition directly on fMRI features without analyzing how visual information is organized across the cortex. This overlooks the brain's hierarchical processing and blurs the roles of early, middle, and late visual areas. We propose Hi-DREAM, a brain-inspired conditional diffusion framework that makes the cortical organization explicit. A region-of-interest (ROI) adapter groups fMRI into early/mid/late streams and converts them into a multi-scale cortical pyramid aligned with the U-Net depth (shallow scales preserve layout and edges; deeper scales emphasize objects and semantics). A lightweight, depth-matched ControlNet injects these scale-specific hints during denoising. The result is an efficient and interpretable decoder in which each signal plays a brain-like role, allowing the model not only to reconstruct images but also to illuminate functional contributions of different visual areas. Experiments on the Natural Scenes Dataset (NSD) show that Hi-DREAM attains state-of-the-art performance on high-level semantic metrics while maintaining competitive low-level fidelity. These findings suggest that structuring conditioning by cortical hierarchy is a powerful alternative to purely data-driven embeddings and provides a useful lens for studying the visual cortex.
Simulating Biological Intelligence: Active Inference with Experiment-Informed Generative Model
Aug 09, 2025With recent and rapid advancements in artificial intelligence (AI), understanding the foundation of purposeful behaviour in autonomous agents is crucial for developing safe and efficient systems. While artificial neural networks have dominated the path to AI, recent studies are exploring the potential of biologically based systems, such as networks of living biological neuronal networks. Along with promises of high power and data efficiency, these systems may also inform more explainable and biologically plausible models. In this work, we propose a framework rooted in active inference, a general theory of behaviour, to model decision-making in embodied agents. Using experiment-informed generative models, we simulate decision-making processes in a simulated game-play environment, mirroring experimental setups that use biological neurons. Our results demonstrate learning in these agents, providing insights into the role of memory-based learning and predictive planning in intelligent decision-making. This work contributes to the growing field of explainable AI by offering a biologically grounded and scalable approach to understanding purposeful behaviour in agents.
A Principled Bayesian Framework for Training Binary and Spiking Neural Networks
May 23, 2025We propose a Bayesian framework for training binary and spiking neural networks that achieves state-of-the-art performance without normalisation layers. Unlike commonly used surrogate gradient methods -- often heuristic and sensitive to hyperparameter choices -- our approach is grounded in a probabilistic model of noisy binary networks, enabling fully end-to-end gradient-based optimisation. We introduce importance-weighted straight-through (IW-ST) estimators, a unified class generalising straight-through and relaxation-based estimators. We characterise the bias-variance trade-off in this family and derive a bias-minimising objective implemented via an auxiliary loss. Building on this, we introduce Spiking Bayesian Neural Networks (SBNNs), a variational inference framework that uses posterior noise to train Binary and Spiking Neural Networks with IW-ST. This Bayesian approach minimises gradient bias, regularises parameters, and introduces dropout-like noise. By linking low-bias conditions, vanishing gradients, and the KL term, we enable training of deep residual networks without normalisation. Experiments on CIFAR-10, DVS Gesture, and SHD show our method matches or exceeds existing approaches without normalisation or hand-tuned gradients.
TAVRNN: Temporal Attention-enhanced Variational Graph RNN Captures Neural Dynamics and Behavior
Oct 01, 2024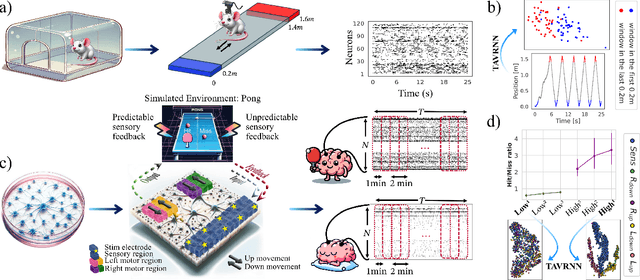
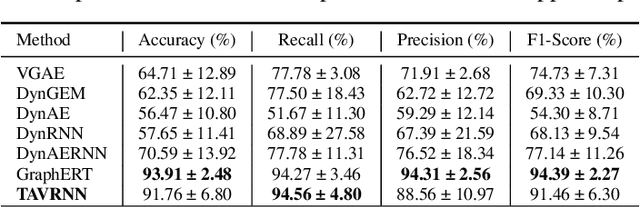
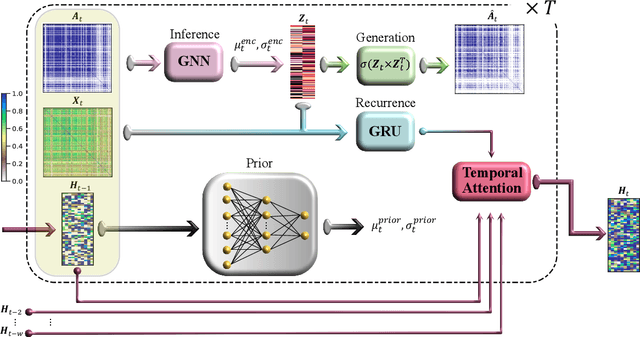

We introduce Temporal Attention-enhanced Variational Graph Recurrent Neural Network (TAVRNN), a novel framework for analyzing the evolving dynamics of neuronal connectivity networks in response to external stimuli and behavioral feedback. TAVRNN captures temporal changes in network structure by modeling sequential snapshots of neuronal activity, enabling the identification of key connectivity patterns. Leveraging temporal attention mechanisms and variational graph techniques, TAVRNN uncovers how connectivity shifts align with behavior over time. We validate TAVRNN on two datasets: in vivo calcium imaging data from freely behaving rats and novel in vitro electrophysiological data from the DishBrain system, where biological neurons control a simulated environment during the game of pong. We show that TAVRNN outperforms previous baseline models in classification, clustering tasks and computational efficiency while accurately linking connectivity changes to performance variations. Crucially, TAVRNN reveals that high game performance in the DishBrain system correlates with the alignment of sensory and motor subregion channels, a relationship not evident in earlier models. This framework represents the first application of dynamic graph representation of electrophysiological (neuronal) data from DishBrain system, providing insights into the reorganization of neuronal networks during learning. TAVRNN's ability to differentiate between neuronal states associated with successful and unsuccessful learning outcomes, offers significant implications for real-time monitoring and manipulation of biological neuronal systems.
Biological Neurons Compete with Deep Reinforcement Learning in Sample Efficiency in a Simulated Gameworld
May 27, 2024How do biological systems and machine learning algorithms compare in the number of samples required to show significant improvements in completing a task? We compared the learning efficiency of in vitro biological neural networks to the state-of-the-art deep reinforcement learning (RL) algorithms in a simplified simulation of the game `Pong'. Using DishBrain, a system that embodies in vitro neural networks with in silico computation using a high-density multi-electrode array, we contrasted the learning rate and the performance of these biological systems against time-matched learning from three state-of-the-art deep RL algorithms (i.e., DQN, A2C, and PPO) in the same game environment. This allowed a meaningful comparison between biological neural systems and deep RL. We find that when samples are limited to a real-world time course, even these very simple biological cultures outperformed deep RL algorithms across various game performance characteristics, implying a higher sample efficiency. Ultimately, even when tested across multiple types of information input to assess the impact of higher dimensional data input, biological neurons showcased faster learning than all deep reinforcement learning agents.
CrossWalk: Fairness-enhanced Node Representation Learning
May 06, 2021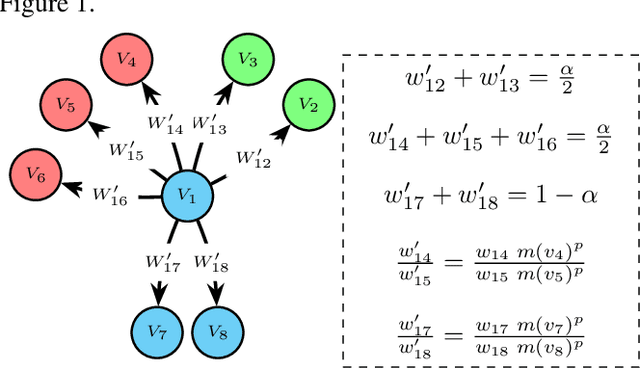
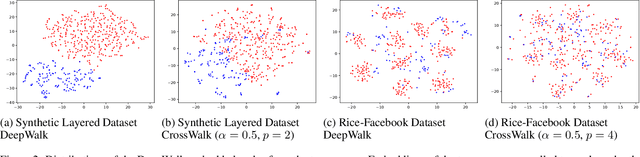
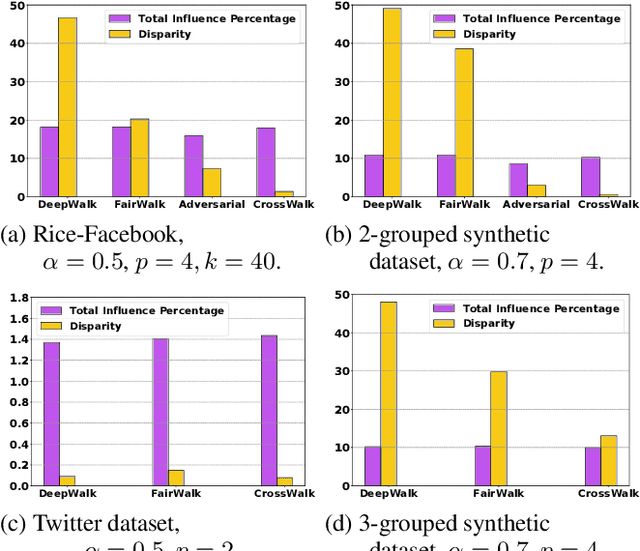
The potential for machine learning systems to amplify social inequities and unfairness is receiving increasing popular and academic attention. Much recent work has focused on developing algorithmic tools to assess and mitigate such unfairness. However, there is little work on enhancing fairness in graph algorithms. Here, we develop a simple, effective and general method, CrossWalk, that enhances fairness of various graph algorithms, including influence maximization, link prediction and node classification, applied to node embeddings. CrossWalk is applicable to any random walk based node representation learning algorithm, such as DeepWalk and Node2Vec. The key idea is to bias random walks to cross group boundaries, by upweighting edges which (1) are closer to the groups' peripheries or (2) connect different groups in the network. CrossWalk pulls nodes that are near groups' peripheries towards their neighbors from other groups in the embedding space, while preserving the necessary structural information from the graph. Extensive experiments show the effectiveness of our algorithm to enhance fairness in various graph algorithms, including influence maximization, link prediction and node classification in synthetic and real networks, with only a very small decrease in performance.
Adversarial Graph Embeddings for Fair Influence Maximization over Social Networks
May 11, 2020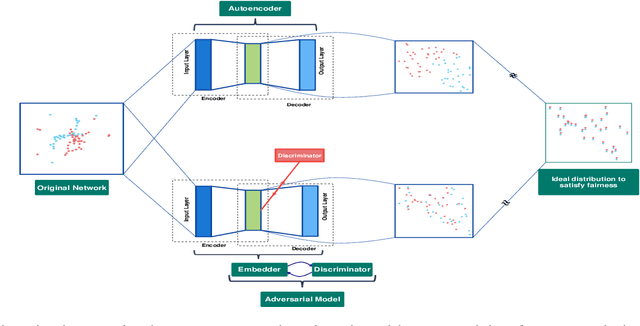
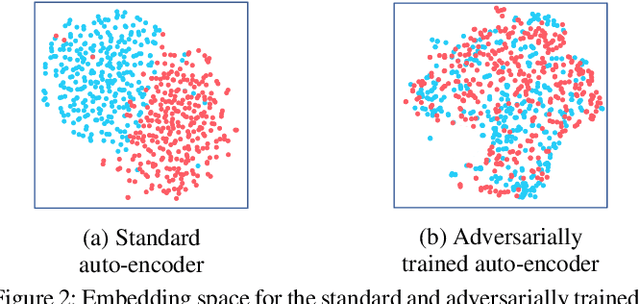
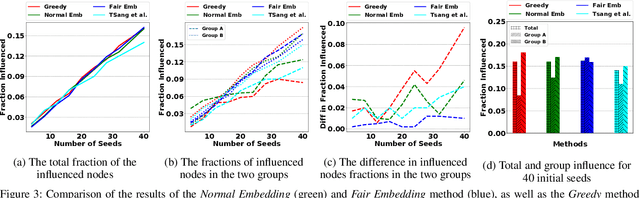
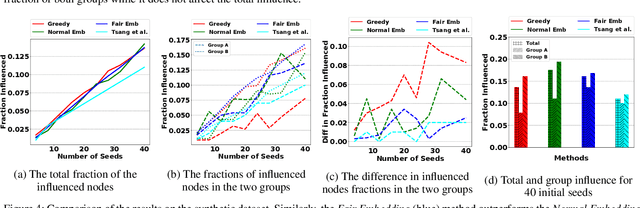
Influence maximization is a widely studied topic in network science, where the aim is to reach the maximum possible number of nodes, while only targeting a small initial set of individuals. It has critical applications in many fields, including viral marketing, information propagation, news dissemination, and vaccinations. However, the objective does not usually take into account whether the final set of influenced nodes is fair with respect to sensitive attributes, such as race or gender. Here we address fair influence maximization, aiming to reach minorities more equitably. We introduce Adversarial Graph Embeddings: we co-train an auto-encoder for graph embedding and a discriminator to discern sensitive attributes. This leads to embeddings which are similarly distributed across sensitive attributes. We then find a good initial set by clustering the embeddings. We believe we are the first to use embeddings for the task of fair influence maximization. While there are typically trade-offs between fairness and influence maximization objectives, our experiments on synthetic and real-world datasets show that our approach dramatically reduces disparity while remaining competitive with state-of-the-art influence maximization methods.
Optimal Decision Making Under Strategic Behavior
May 22, 2019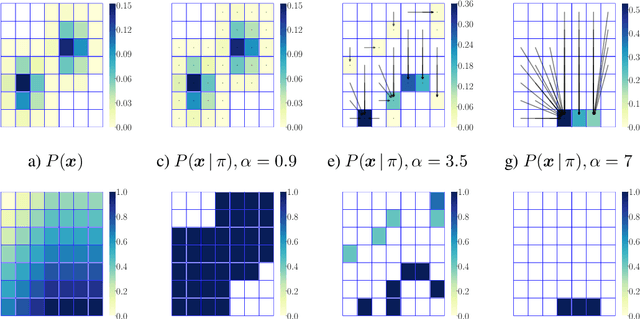
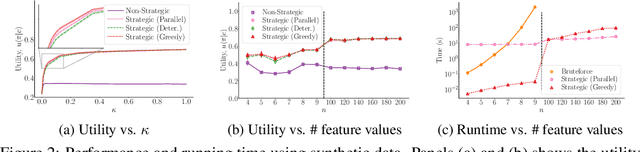
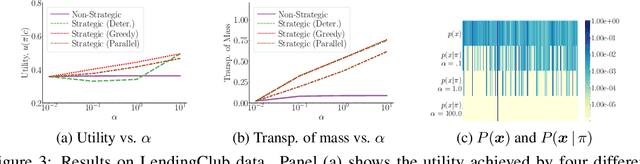
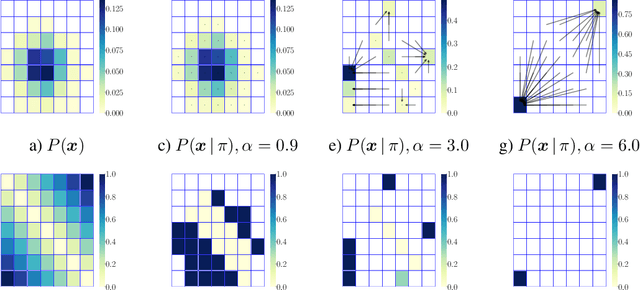
We are witnessing an increasing use of data-driven predictive models to inform decisions. As decisions have implications for individuals and society, there is increasing pressure on decision makers to be transparent about their decision policies, models, and the features they use. At the same time, individuals may use knowledge, gained by transparency, to invest effort strategically in order to maximize their chances of receiving a beneficial decision. In this paper, our goal is to find decision policies that are optimal in terms of utility in such a strategic setting. To this end, we first use the theory of optimal transport to characterize how strategic investment of effort by individuals leads to a change in the feature distribution at a population level. Then, we show that, in contrast with the non-strategic setting, optimal decision policies are stochastic, and we cannot expect to find them in polynomial time. Finally, we derive an efficient greedy algorithm that is guaranteed to find locally optimal decision policies in polynomial time. Experiments on synthetic and real lending data illustrate our theoretical findings and show that the decision policies found by our greedy algorithm achieve higher utility than deterministic threshold rules, which are optimal policies in a non-strategic setting.