 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusRec: Zero-Shot Text-to-Music Editing via Rectified Flow and Diffusion Transformers
Nov 06, 2025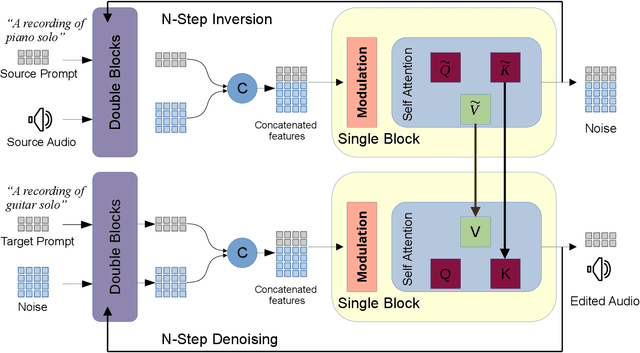



Music editing has emerged as an important and practical area of artificial intelligence, with applications ranging from video game and film music production to personalizing existing tracks according to user preferences. However, existing models face significant limitations, such as being restricted to editing synthesized music generated by their own models, requiring highly precise prompts, or necessitating task-specific retraining, thus lacking true zero-shot capability. Leveraging recent advances in rectified flow and diffusion transformers, we introduce MusRec, the first zero-shot text-to-music editing model capable of performing diverse editing tasks on real-world music efficiently and effectively. Experimental results demonstrate that our approach outperforms existing methods in preserving musical content, structural consistency, and editing fidelity, establishing a strong foundation for controllable music editing in real-world scenarios.
DCOR: Anomaly Detection in Attributed Networks via Dual Contrastive Learning Reconstruction
Dec 21, 2024



Anomaly detection using a network-based approach is one of the most efficient ways to identify abnormal events such as fraud, security breaches, and system faults in a variety of applied domains. While most of the earlier works address the complex nature of graph-structured data and predefined anomalies, the impact of data attributes and emerging anomalies are often neglected. This paper introduces DCOR, a novel approach on attributed networks that integrates reconstruction-based anomaly detection with Contrastive Learning. Utilizing a Graph Neural Network (GNN) framework, DCOR contrasts the reconstructed adjacency and feature matrices from both the original and augmented graphs to detect subtle anomalies. We employed comprehensive experimental studies on benchmark datasets through standard evaluation measures. The results show that DCOR significantly outperforms state-of-the-art methods. Obtained results demonstrate the efficacy of proposed approach in attributed networks with the potential of uncovering new patterns of anomalies.
Neural Graph Collaborative Filtering Using Variational Inference
Dec 02, 2023The customization of recommended content to users holds significant importance in enhancing user experiences across a wide spectrum of applications such as e-commerce, music, and shopping. Graph-based methods have achieved considerable performance by capturing user-item interactions. However, these methods tend to utilize randomly constructed embeddings in the dataset used for training the recommender, which lacks any user preferences. Here, we propose the concept of variational embeddings as a means of pre-training the recommender system to improve the feature propagation through the layers of graph convolutional networks (GCNs). The graph variational embedding collaborative filtering (GVECF) is introduced as a novel framework to incorporate representations learned through a variational graph auto-encoder which are embedded into a GCN-based collaborative filtering. This approach effectively transforms latent high-order user-item interactions into more trainable vectors, ultimately resulting in better performance in terms of recall and normalized discounted cumulative gain(NDCG) metrics. The experiments conducted on benchmark datasets demonstrate that our proposed method achieves up to 13.78% improvement in the recall over the test data.
Low-rank Dictionary Learning for Unsupervised Feature Selection
Jun 21, 2021
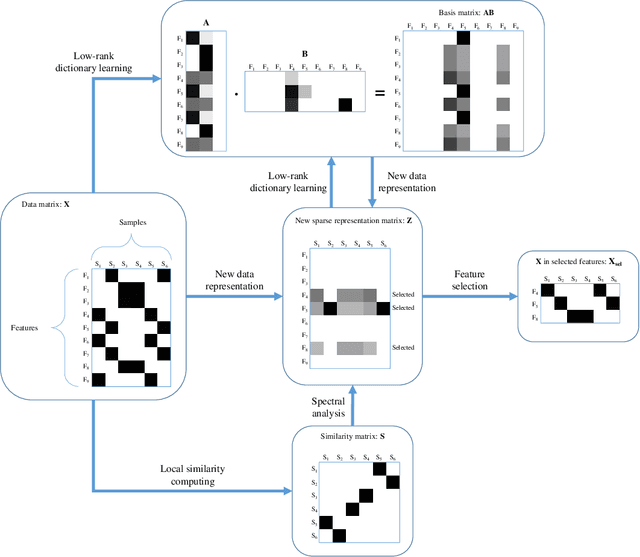

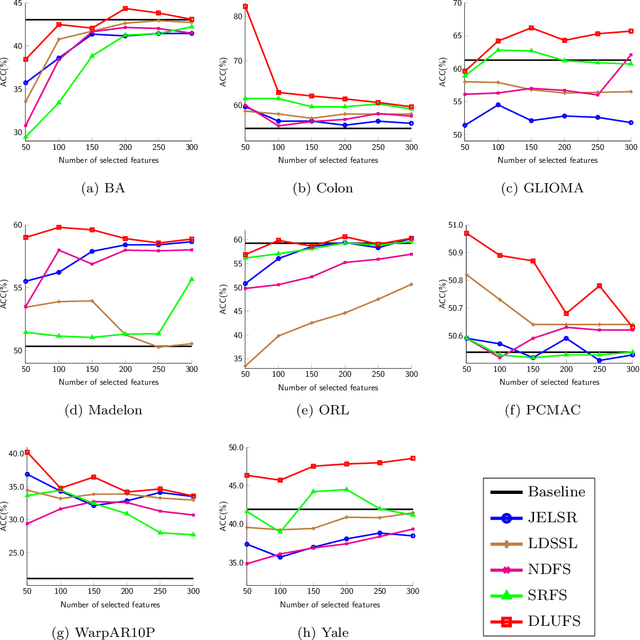
There exist many high-dimensional data in real-world applications such as biology, computer vision, and social networks. Feature selection approaches are devised to confront with high-dimensional data challenges with the aim of efficient learning technologies as well as reduction of models complexity. Due to the hardship of labeling on these datasets, there are a variety of approaches on feature selection process in an unsupervised setting by considering some important characteristics of data. In this paper, we introduce a novel unsupervised feature selection approach by applying dictionary learning ideas in a low-rank representation. Dictionary learning in a low-rank representation not only enables us to provide a new representation, but it also maintains feature correlation. Then, spectral analysis is employed to preserve sample similarities. Finally, a unified objective function for unsupervised feature selection is proposed in a sparse way by an $\ell_{2,1}$-norm regularization. Furthermore, an efficient numerical algorithm is designed to solve the corresponding optimization problem. We demonstrate the performance of the proposed method based on a variety of standard datasets from different applied domains. Our experimental findings reveal that the proposed method outperforms the state-of-the-art algorithm.
Detection of Community Structures in Networks with Nodal Features based on Generative Probabilistic Approach
Dec 24, 2019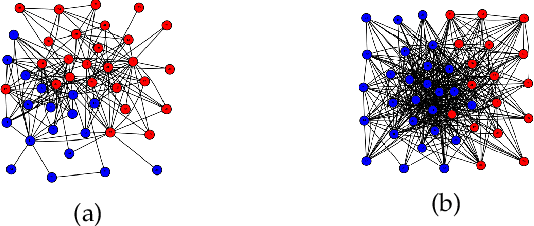

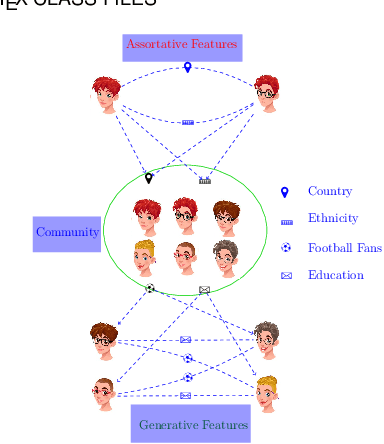
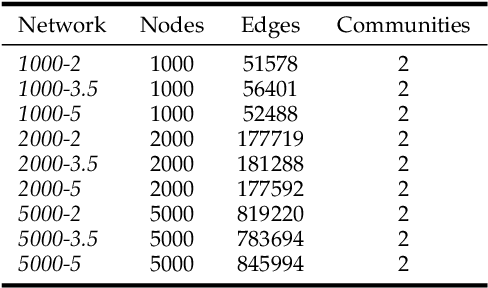
Community detection is considered as a fundamental task in analyzing social networks. Even though many techniques have been proposed for community detection, most of them are based exclusively on the connectivity structures. However, there are node features in real networks, such as gender types in social networks, feeding behavior in ecological networks, and location on e-trading networks, that can be further leveraged with the network structure to attain more accurate community detection methods. We propose a novel probabilistic graphical model to detect communities by taking into account both network structure and nodes' features. The proposed approach learns the relevant features of communities through a generative probabilistic model without any prior assumption on the communities. Furthermore, the model is capable of determining the strength of node features and structural elements of the networks on shaping the communities. The effectiveness of the proposed approach over the state-of-the-art algorithms is revealed on synthetic and benchmark networks.
* 12 pages, 13 figures, 6 tables
Unsupervised Feature Selection based on Adaptive Similarity Learning and Subspace Clustering
Dec 10, 2019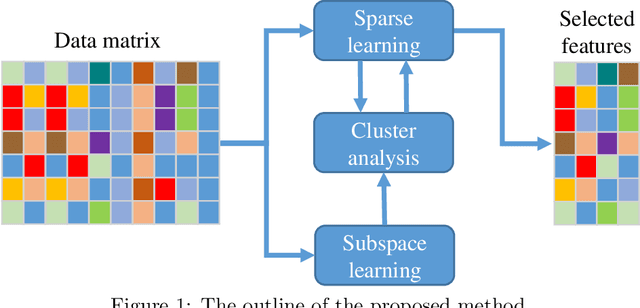



Feature selection methods have an important role on the readability of data and the reduction of complexity of learning algorithms. In recent years, a variety of efforts are investigated on feature selection problems based on unsupervised viewpoint due to the laborious labeling task on large datasets. In this paper, we propose a novel approach on unsupervised feature selection initiated from the subspace clustering to preserve the similarities by representation learning of low dimensional subspaces among the samples. A self-expressive model is employed to implicitly learn the cluster similarities in an adaptive manner. The proposed method not only maintains the sample similarities through subspace clustering, but it also captures the discriminative information based on a regularized regression model. In line with the convergence analysis of the proposed method, the experimental results on benchmark datasets demonstrate the effectiveness of our approach as compared with the state of the art methods.
Deep Sentiment Analysis using a Graph-based Text Representation
Feb 23, 2019
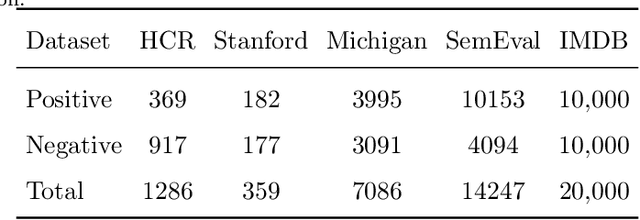
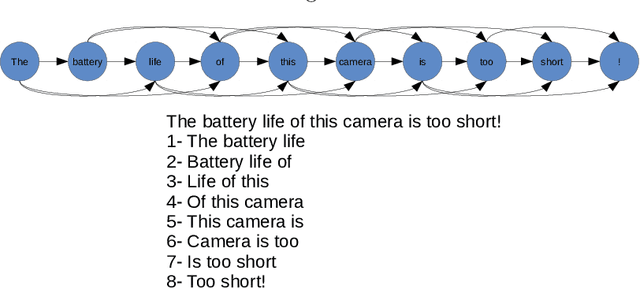

Social media brings about new ways of communication among people and is influencing trading strategies in the market. The popularity of social networks produces a large collection of unstructured data such as text and image in a variety of disciplines like business and health. The main element of social media arises as text which provokes a set of challenges for traditional information retrieval and natural language processing tools. Informal language, spelling errors, abbreviations, and special characters are typical in social media posts. These features lead to a prohibitively large vocabulary size for text mining methods. Another problem with traditional social text mining techniques is that they fail to take semantic relations into account, which is essential in a domain of applications such as event detection, opinion mining, and news recommendation. This paper set out to employ a network-based viewpoint on text documents and investigate the usefulness of graph representation to exploit word relations and semantics of the textual data. Moreover, the proposed approach makes use of a random walker to extract deep features of a graph to facilitate the task of document classification. The experimental results indicate that the proposed approach defeats the earlier sentiment analysis methods based on several benchmark datasets, and it generalizes well on different datasets without dependency for pre-trained word embeddings.
Deep Learning Approach on Information Diffusion in Heterogeneous Networks
Feb 23, 2019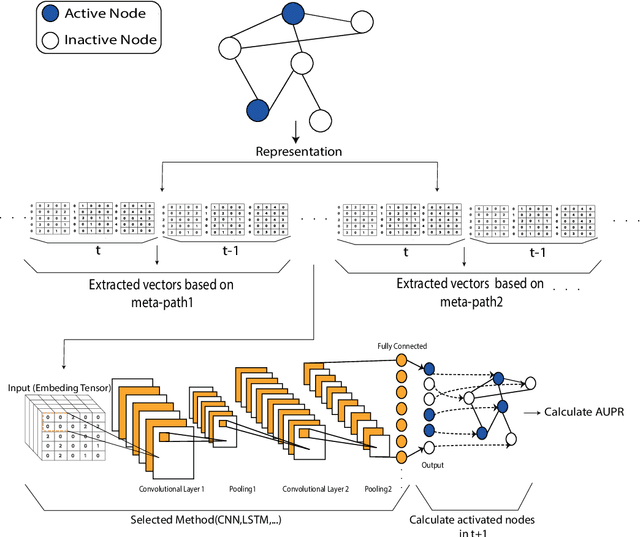
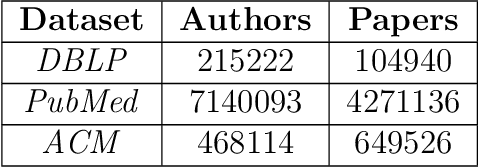
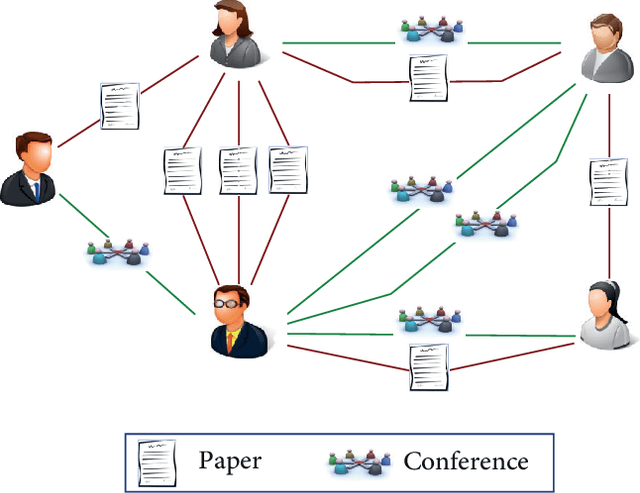
There are many real-world knowledge based networked systems with multi-type interacting entities that can be regarded as heterogeneous networks including human connections and biological evolutions. One of the main issues in such networks is to predict information diffusion such as shape, growth and size of social events and evolutions in the future. While there exist a variety of works on this topic mainly using a threshold-based approach, they suffer from the local viewpoint on the network and sensitivity to the threshold parameters. In this paper, information diffusion is considered through a latent representation learning of the heterogeneous networks to encode in a deep learning model. To this end, we propose a novel meta-path representation learning approach, Heterogeneous Deep Diffusion(HDD), to exploit meta-paths as main entities in networks. At first, the functional heterogeneous structures of the network are learned by a continuous latent representation through traversing meta-paths with the aim of global end-to-end viewpoint. Then, the well-known deep learning architectures are employed on our generated features to predict diffusion processes in the network. The proposed approach enables us to apply it on different information diffusion tasks such as topic diffusion and cascade prediction. We demonstrate the proposed approach on benchmark network datasets through the well-known evaluation measures. The experimental results show that our approach outperforms the earlier state-of-the-art methods.
Memory Enriched Big Bang Big Crunch Optimization Algorithm for Data Clustering
Mar 08, 2017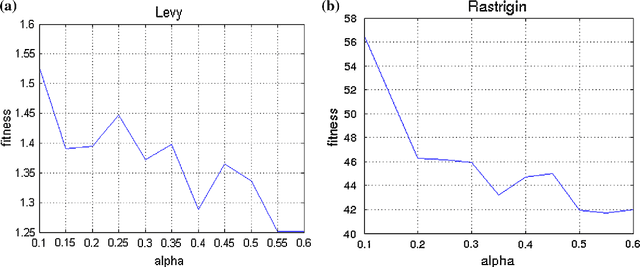

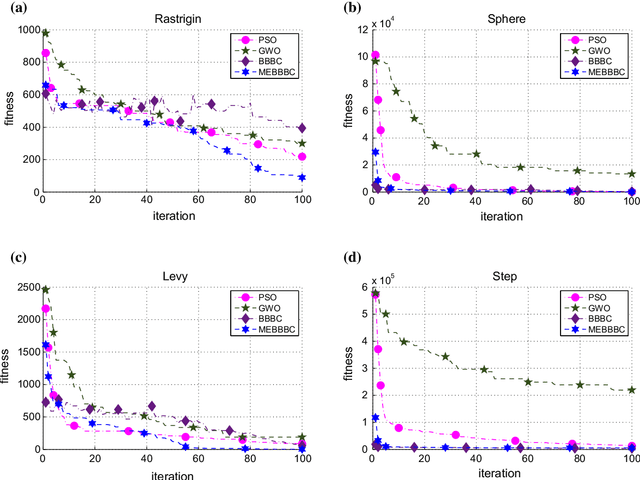
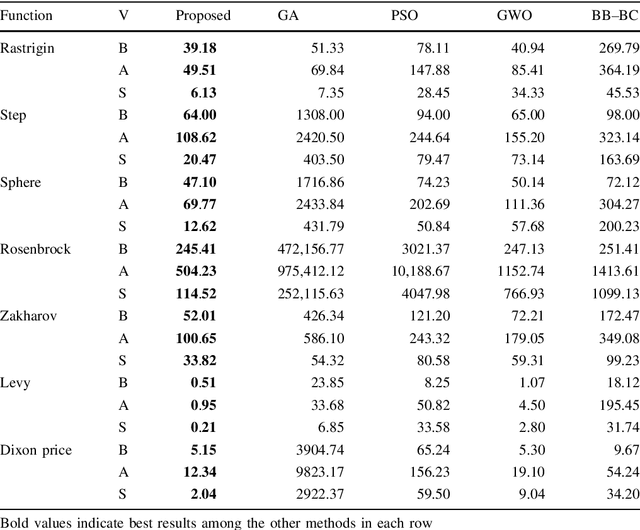
Cluster analysis plays an important role in decision making process for many knowledge-based systems. There exist a wide variety of different approaches for clustering applications including the heuristic techniques, probabilistic models, and traditional hierarchical algorithms. In this paper, a novel heuristic approach based on big bang-big crunch algorithm is proposed for clustering problems. The proposed method not only takes advantage of heuristic nature to alleviate typical clustering algorithms such as k-means, but it also benefits from the memory based scheme as compared to its similar heuristic techniques. Furthermore, the performance of the proposed algorithm is investigated based on several benchmark test functions as well as on the well-known datasets. The experimental results show the significant superiority of the proposed method over the similar algorithms.
* 17 pages, 3 figures, 8 tables
IEDC: An Integrated Approach for Overlapping and Non-overlapping Community Detection
Feb 13, 2017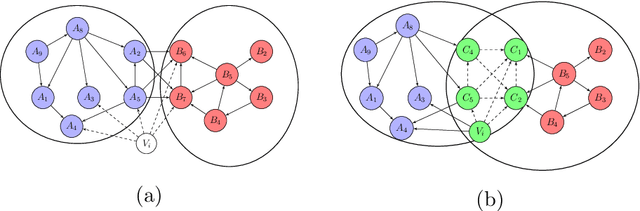
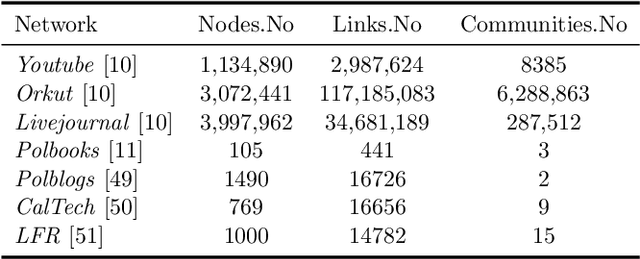
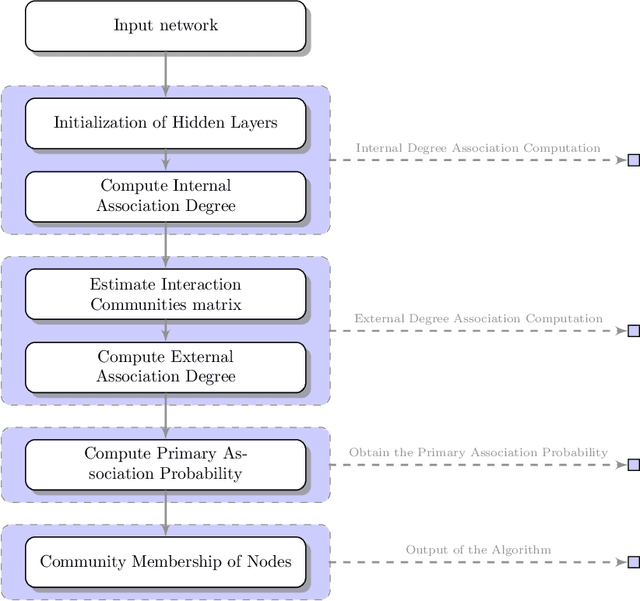
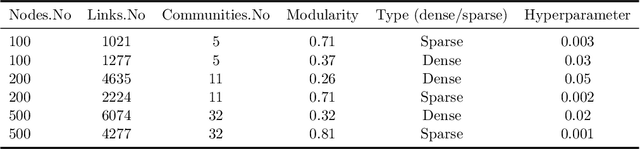
Community detection is a task of fundamental importance in social network analysis that can be used in a variety of knowledge-based domains. While there exist many works on community detection based on connectivity structures, they suffer from either considering the overlapping or non-overlapping communities. In this work, we propose a novel approach for general community detection through an integrated framework to extract the overlapping and non-overlapping community structures without assuming prior structural connectivity on networks. Our general framework is based on a primary node based criterion which consists of the internal association degree along with the external association degree. The evaluation of the proposed method is investigated through the extensive simulation experiments and several benchmark real network datasets. The experimental results show that the proposed method outperforms the earlier state-of-the-art algorithms based on the well-known evaluation criteria.