 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCOR: Anomaly Detection in Attributed Networks via Dual Contrastive Learning Reconstruction
Dec 21, 2024



Anomaly detection using a network-based approach is one of the most efficient ways to identify abnormal events such as fraud, security breaches, and system faults in a variety of applied domains. While most of the earlier works address the complex nature of graph-structured data and predefined anomalies, the impact of data attributes and emerging anomalies are often neglected. This paper introduces DCOR, a novel approach on attributed networks that integrates reconstruction-based anomaly detection with Contrastive Learning. Utilizing a Graph Neural Network (GNN) framework, DCOR contrasts the reconstructed adjacency and feature matrices from both the original and augmented graphs to detect subtle anomalies. We employed comprehensive experimental studies on benchmark datasets through standard evaluation measures. The results show that DCOR significantly outperforms state-of-the-art methods. Obtained results demonstrate the efficacy of proposed approach in attributed networks with the potential of uncovering new patterns of anomalies.
Low-rank Dictionary Learning for Unsupervised Feature Selection
Jun 21, 2021
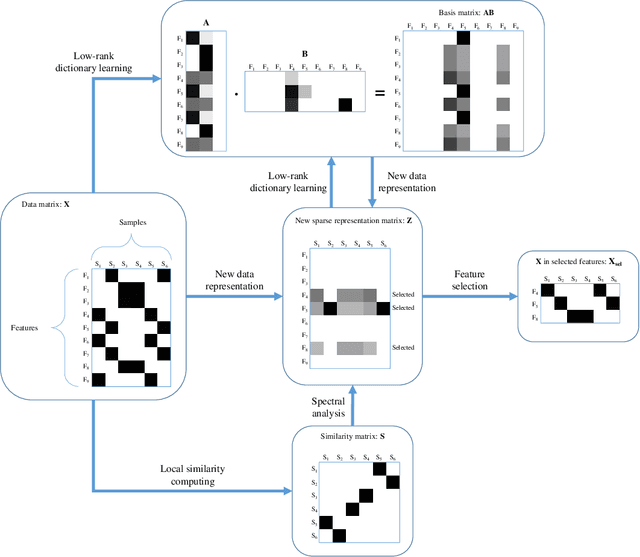

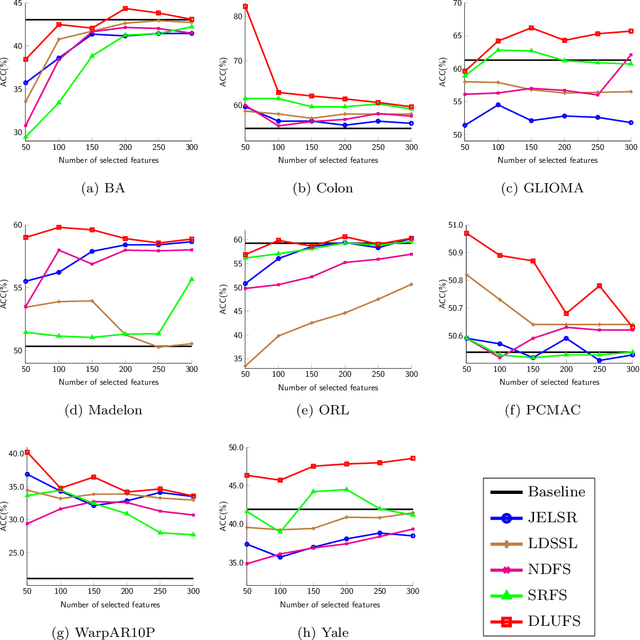
There exist many high-dimensional data in real-world applications such as biology, computer vision, and social networks. Feature selection approaches are devised to confront with high-dimensional data challenges with the aim of efficient learning technologies as well as reduction of models complexity. Due to the hardship of labeling on these datasets, there are a variety of approaches on feature selection process in an unsupervised setting by considering some important characteristics of data. In this paper, we introduce a novel unsupervised feature selection approach by applying dictionary learning ideas in a low-rank representation. Dictionary learning in a low-rank representation not only enables us to provide a new representation, but it also maintains feature correlation. Then, spectral analysis is employed to preserve sample similarities. Finally, a unified objective function for unsupervised feature selection is proposed in a sparse way by an $\ell_{2,1}$-norm regularization. Furthermore, an efficient numerical algorithm is designed to solve the corresponding optimization problem. We demonstrate the performance of the proposed method based on a variety of standard datasets from different applied domains. Our experimental findings reveal that the proposed method outperforms the state-of-the-art algorithm.
Unsupervised Feature Selection based on Adaptive Similarity Learning and Subspace Clustering
Dec 10, 2019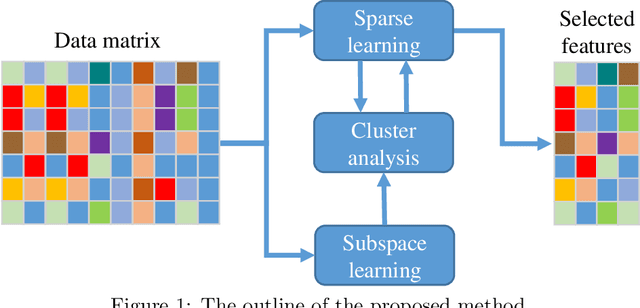



Feature selection methods have an important role on the readability of data and the reduction of complexity of learning algorithms. In recent years, a variety of efforts are investigated on feature selection problems based on unsupervised viewpoint due to the laborious labeling task on large datasets. In this paper, we propose a novel approach on unsupervised feature selection initiated from the subspace clustering to preserve the similarities by representation learning of low dimensional subspaces among the samples. A self-expressive model is employed to implicitly learn the cluster similarities in an adaptive manner. The proposed method not only maintains the sample similarities through subspace clustering, but it also captures the discriminative information based on a regularized regression model. In line with the convergence analysis of the proposed method, the experimental results on benchmark datasets demonstrate the effectiveness of our approach as compared with the state of the art methods.