 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-rank Dictionary Learning for Unsupervised Feature Selection
Paper and Code
Jun 21, 2021
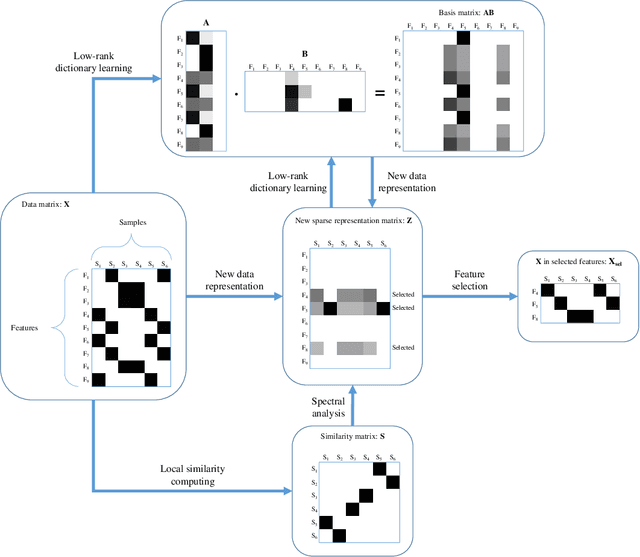

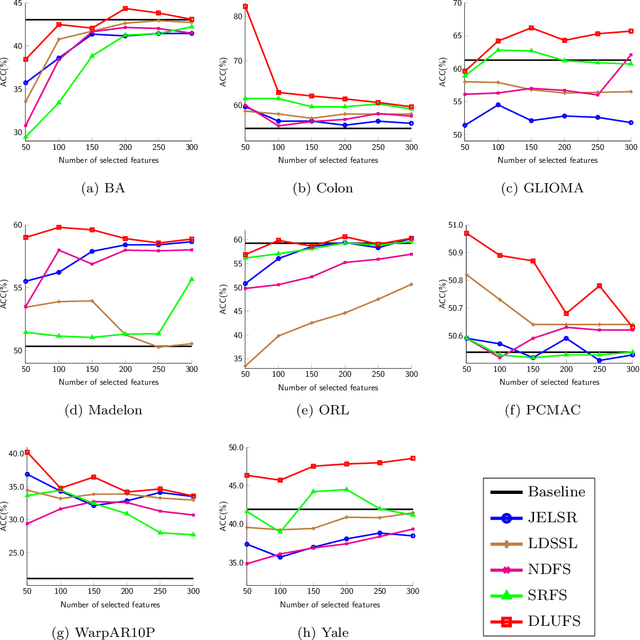
There exist many high-dimensional data in real-world applications such as biology, computer vision, and social networks. Feature selection approaches are devised to confront with high-dimensional data challenges with the aim of efficient learning technologies as well as reduction of models complexity. Due to the hardship of labeling on these datasets, there are a variety of approaches on feature selection process in an unsupervised setting by considering some important characteristics of data. In this paper, we introduce a novel unsupervised feature selection approach by applying dictionary learning ideas in a low-rank representation. Dictionary learning in a low-rank representation not only enables us to provide a new representation, but it also maintains feature correlation. Then, spectral analysis is employed to preserve sample similarities. Finally, a unified objective function for unsupervised feature selection is proposed in a sparse way by an $\ell_{2,1}$-norm regularization. Furthermore, an efficient numerical algorithm is designed to solve the corresponding optimization problem. We demonstrate the performance of the proposed method based on a variety of standard datasets from different applied domains. Our experimental findings reveal that the proposed method outperforms the state-of-the-art algorithm.