 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Sentiment Analysis using a Graph-based Text Representation
Feb 23, 2019

Social media brings about new ways of communication among people and is influencing trading strategies in the market. The popularity of social networks produces a large collection of unstructured data such as text and image in a variety of disciplines like business and health. The main element of social media arises as text which provokes a set of challenges for traditional information retrieval and natural language processing tools. Informal language, spelling errors, abbreviations, and special characters are typical in social media posts. These features lead to a prohibitively large vocabulary size for text mining methods. Another problem with traditional social text mining techniques is that they fail to take semantic relations into account, which is essential in a domain of applications such as event detection, opinion mining, and news recommendation. This paper set out to employ a network-based viewpoint on text documents and investigate the usefulness of graph representation to exploit word relations and semantics of the textual data. Moreover, the proposed approach makes use of a random walker to extract deep features of a graph to facilitate the task of document classification. The experimental results indicate that the proposed approach defeats the earlier sentiment analysis methods based on several benchmark datasets, and it generalizes well on different datasets without dependency for pre-trained word embeddings.
Memory Enriched Big Bang Big Crunch Optimization Algorithm for Data Clustering
Mar 08, 2017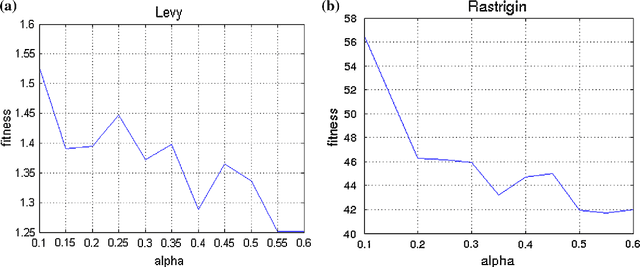

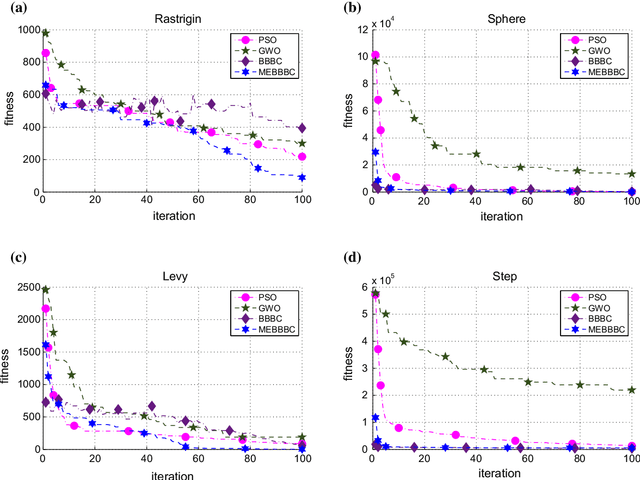
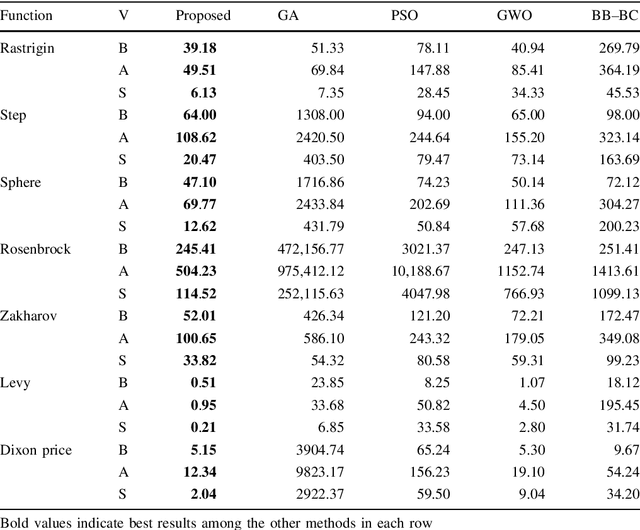
Cluster analysis plays an important role in decision making process for many knowledge-based systems. There exist a wide variety of different approaches for clustering applications including the heuristic techniques, probabilistic models, and traditional hierarchical algorithms. In this paper, a novel heuristic approach based on big bang-big crunch algorithm is proposed for clustering problems. The proposed method not only takes advantage of heuristic nature to alleviate typical clustering algorithms such as k-means, but it also benefits from the memory based scheme as compared to its similar heuristic techniques. Furthermore, the performance of the proposed algorithm is investigated based on several benchmark test functions as well as on the well-known datasets. The experimental results show the significant superiority of the proposed method over the similar algorithms.
* 17 pages, 3 figures, 8 tables