 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC2L-GAD: Active Counterfactual Contrastive Learning for Graph Anomaly Detection
Jan 29, 2026Graph anomaly detection aims to identify abnormal patterns in networks, but faces significant challenges from label scarcity and extreme class imbalance. While graph contrastive learning offers a promising unsupervised solution, existing methods suffer from two critical limitations: random augmentations break semantic consistency in positive pairs, while naive negative sampling produces trivial, uninformative contrasts. We propose AC2L-GAD, an Active Counterfactual Contrastive Learning framework that addresses both limitations through principled counterfactual reasoning. By combining information-theoretic active selection with counterfactual generation, our approach identifies structurally complex nodes and generates anomaly-preserving positive augmentations alongside normal negative counterparts that provide hard contrasts, while restricting expensive counterfactual generation to a strategically selected subset. This design reduces computational overhead by approximately 65% compared to full-graph counterfactual generation while maintaining detection quality. Experiments on nine benchmark datasets, including real-world financial transaction graphs from GADBench, show that AC2L-GAD achieves competitive or superior performance compared to state-of-the-art baselines, with notable gains in datasets where anomalies exhibit complex attribute-structure interactions.
Learning Hierarchical Procedural Memory for LLM Agents through Bayesian Selection and Contrastive Refinement
Dec 22, 2025We present MACLA, a framework that decouples reasoning from learning by maintaining a frozen large language model while performing all adaptation in an external hierarchical procedural memory. MACLA extracts reusable procedures from trajectories, tracks reliability via Bayesian posteriors, selects actions through expected-utility scoring, and refines procedures by contrasting successes and failures. Across four benchmarks (ALFWorld, WebShop, TravelPlanner, InterCodeSQL), MACLA achieves 78.1 percent average performance, outperforming all baselines. On ALFWorld unseen tasks, MACLA reaches 90.3 percent with 3.1 percent positive generalization. The system constructs memory in 56 seconds, 2800 times faster than the state-of-the-art LLM parameter-training baseline, compressing 2851 trajectories into 187 procedures. Experimental results demonstrate that structured external memory with Bayesian selection and contrastive refinement enables sample-efficient, interpretable, and continually improving agents without LLM parameter updates.
Neural Graph Collaborative Filtering Using Variational Inference
Dec 02, 2023The customization of recommended content to users holds significant importance in enhancing user experiences across a wide spectrum of applications such as e-commerce, music, and shopping. Graph-based methods have achieved considerable performance by capturing user-item interactions. However, these methods tend to utilize randomly constructed embeddings in the dataset used for training the recommender, which lacks any user preferences. Here, we propose the concept of variational embeddings as a means of pre-training the recommender system to improve the feature propagation through the layers of graph convolutional networks (GCNs). The graph variational embedding collaborative filtering (GVECF) is introduced as a novel framework to incorporate representations learned through a variational graph auto-encoder which are embedded into a GCN-based collaborative filtering. This approach effectively transforms latent high-order user-item interactions into more trainable vectors, ultimately resulting in better performance in terms of recall and normalized discounted cumulative gain(NDCG) metrics. The experiments conducted on benchmark datasets demonstrate that our proposed method achieves up to 13.78% improvement in the recall over the test data.
Universal Feature Selection Tool (UniFeat): An Open-Source Tool for Dimensionality Reduction
Nov 30, 2022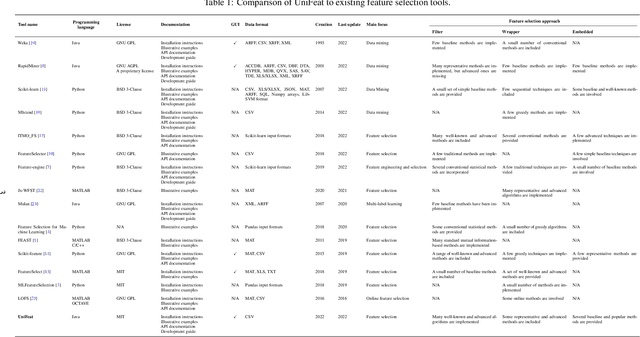



The Universal Feature Selection Tool (UniFeat) is an open-source tool developed entirely in Java for performing feature selection processes in various research areas. It provides a set of well-known and advanced feature selection methods within its significant auxiliary tools. This allows users to compare the performance of feature selection methods. Moreover, due to the open-source nature of UniFeat, researchers can use and modify it in their research, which facilitates the rapid development of new feature selection algorithms.
Self-Paced Multi-Label Learning with Diversity
Oct 08, 2019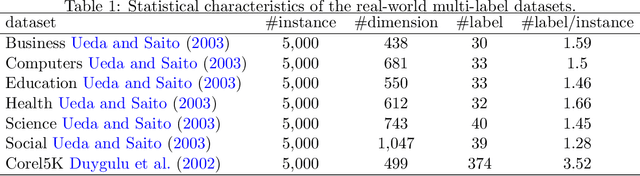
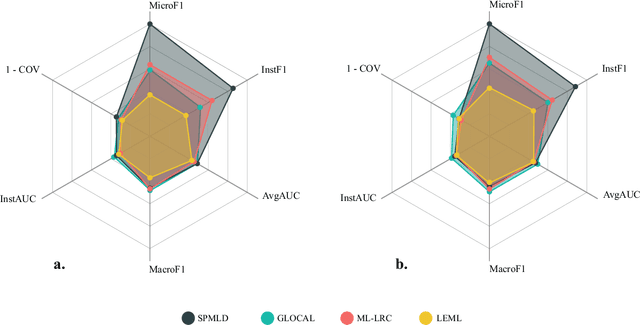
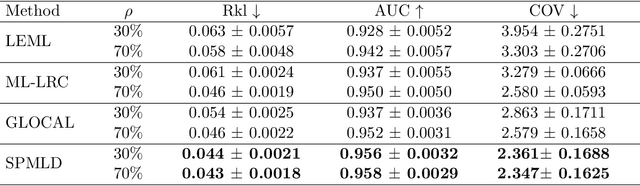
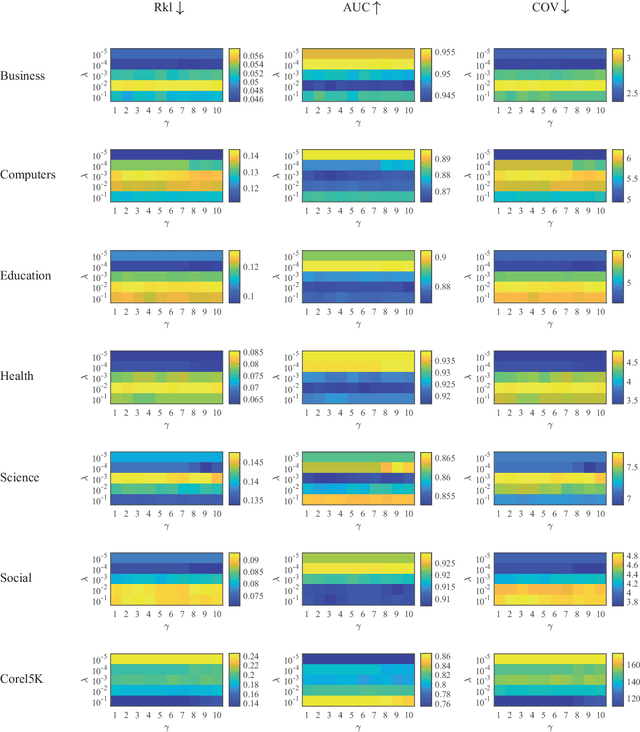
The major challenge of learning from multi-label data has arisen from the overwhelming size of label space which makes this problem NP-hard. This problem can be alleviated by gradually involving easy to hard tags into the learning process. Besides, the utilization of a diversity maintenance approach avoids overfitting on a subset of easy labels. In this paper, we propose a self-paced multi-label learning with diversity (SPMLD) which aims to cover diverse labels with respect to its learning pace. In addition, the proposed framework is applied to an efficient correlation-based multi-label method. The non-convex objective function is optimized by an extension of the block coordinate descent algorithm. Empirical evaluations on real-world datasets with different dimensions of features and labels imply the effectiveness of the proposed predictive model.