 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS-Playground: A High-Throughput Photorealistic Simulator for Vision-Informed Robot Learning
Apr 28, 2026Embodied AI research is undergoing a shift toward vision-centric perceptual paradigms. While massively parallel simulators have catalyzed breakthroughs in proprioception-based locomotion, their potential remains largely untapped for vision-informed tasks due to the prohibitive computational overhead of large-scale photorealistic rendering. Furthermore, the creation of simulation-ready 3D assets heavily relies on labor-intensive manual modeling, while the significant sim-to-real physical gap hinders the transfer of contact-rich manipulation policies. To address these bottlenecks, we propose GS-Playground, a multi-modal simulation framework designed to accelerate end-to-end perceptual learning. We develop a novel high-performance parallel physics engine, specifically designed to integrate with a batch 3D Gaussian Splatting (3DGS) rendering pipeline to ensure high-fidelity synchronization. Our system achieves a breakthrough throughput of 10^4 FPS at 640x480 resolution, significantly lowering the barrier for large-scale visual RL. Additionally, we introduce an automated Real2Sim workflow that reconstructs photorealistic, physically consistent, and memory-efficient environments, streamlining the generation of complex simulation-ready scenes. Extensive experiments on locomotion, navigation, and manipulation demonstrate that GS-Playground effectively bridges the perceptual and physical gaps across diverse embodied tasks. Project homepage: https://gsplayground.github.io.
ProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn LLM Agents
Mar 19, 2026Multi-turn LLM agents are increasingly important for solving complex, interactive tasks, and reinforcement learning (RL) is a key ingredient for improving their long-horizon behavior. However, RL training requires generating large numbers of sandboxed rollout trajectories, and existing infrastructures often couple rollout orchestration with the training loop, making systems hard to migrate and maintain. Under the rollout-as-a-service philosophy, we present ProRL Agent , a scalable infrastructure that serves the full agentic rollout lifecycle through an API service. ProRL Agent also provides standardized and extensible sandbox environments that support diverse agentic tasks in rootless HPC settings. We validate ProRL Agent through RL training on software engineering, math, STEM, and coding tasks. ProRL Agent is open-sourced and integrated as part of NVIDIA NeMo Gym.
Bridging Scale Discrepancies in Robotic Control via Language-Based Action Representations
Dec 09, 2025Recent end-to-end robotic manipulation research increasingly adopts architectures inspired by large language models to enable robust manipulation. However, a critical challenge arises from severe distribution shifts between robotic action data, primarily due to substantial numerical variations in action commands across diverse robotic platforms and tasks, hindering the effective transfer of pretrained knowledge. To address this limitation, we propose a semantically grounded linguistic representation to normalize actions for efficient pretraining. Unlike conventional discretized action representations that are sensitive to numerical scales, the motion representation specifically disregards numeric scale effects, emphasizing directionality instead. This abstraction mitigates distribution shifts, yielding a more generalizable pretraining representation. Moreover, using the motion representation narrows the feature distance between action tokens and standard vocabulary tokens, mitigating modality gaps. Multi-task experiments on two benchmarks demonstrate that the proposed method significantly improves generalization performance and transferability in robotic manipulation tasks.
MoE-GraphSAGE-Based Integrated Evaluation of Transient Rotor Angle and Voltage Stability in Power Systems
Nov 05, 2025The large-scale integration of renewable energy and power electronic devices has increased the complexity of power system stability, making transient stability assessment more challenging. Conventional methods are limited in both accuracy and computational efficiency. To address these challenges, this paper proposes MoE-GraphSAGE, a graph neural network framework based on the MoE for unified TAS and TVS assessment. The framework leverages GraphSAGE to capture the power grid's spatiotemporal topological features and employs multi-expert networks with a gating mechanism to model distinct instability modes jointly. Experimental results on the IEEE 39-bus system demonstrate that MoE-GraphSAGE achieves superior accuracy and efficiency, offering an effective solution for online multi-task transient stability assessment in complex power systems.
Conversational Recommender System and Large Language Model Are Made for Each Other in E-commerce Pre-sales Dialogue
Oct 23, 2023



E-commerce pre-sales dialogue aims to understand and elicit user needs and preferences for the items they are seeking so as to provide appropriate recommendations. Conversational recommender systems (CRSs) learn user representation and provide accurate recommendations based on dialogue context, but rely on external knowledge. Large language models (LLMs) generate responses that mimic pre-sales dialogues after fine-tuning, but lack domain-specific knowledge for accurate recommendations. Intuitively, the strengths of LLM and CRS in E-commerce pre-sales dialogues are complementary, yet no previous work has explored this. This paper investigates the effectiveness of combining LLM and CRS in E-commerce pre-sales dialogues, proposing two collaboration methods: CRS assisting LLM and LLM assisting CRS. We conduct extensive experiments on a real-world dataset of Ecommerce pre-sales dialogues. We analyze the impact of two collaborative approaches with two CRSs and two LLMs on four tasks of Ecommerce pre-sales dialogue. We find that collaborations between CRS and LLM can be very effective in some cases.
Towards Personalized Review Summarization by Modeling Historical Reviews from Customer and Product Separately
Jan 27, 2023Review summarization is a non-trivial task that aims to summarize the main idea of the product review in the E-commerce website. Different from the document summary which only needs to focus on the main facts described in the document, review summarization should not only summarize the main aspects mentioned in the review but also reflect the personal style of the review author. Although existing review summarization methods have incorporated the historical reviews of both customer and product, they usually simply concatenate and indiscriminately model this two heterogeneous information into a long sequence. Moreover, the rating information can also provide a high-level abstraction of customer preference, it has not been used by the majority of methods. In this paper, we propose the Heterogeneous Historical Review aware Review Summarization Model (HHRRS) which separately models the two types of historical reviews with the rating information by a graph reasoning module with a contrastive loss. We employ a multi-task framework that conducts the review sentiment classification and summarization jointly. Extensive experiments on four benchmark datasets demonstrate the superiority of HHRRS on both tasks.
Towards Generalized Models for Task-oriented Dialogue Modeling on Spoken Conversations
Mar 08, 2022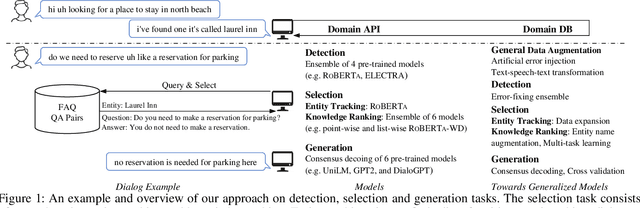


Building robust and general dialogue models for spoken conversations is challenging due to the gap in distributions of spoken and written data. This paper presents our approach to build generalized models for the Knowledge-grounded Task-oriented Dialogue Modeling on Spoken Conversations Challenge of DSTC-10. In order to mitigate the discrepancies between spoken and written text, we mainly employ extensive data augmentation strategies on written data, including artificial error injection and round-trip text-speech transformation. To train robust models for spoken conversations, we improve pre-trained language models, and apply ensemble algorithms for each sub-task. Typically, for the detection task, we fine-tune \roberta and ELECTRA, and run an error-fixing ensemble algorithm. For the selection task, we adopt a two-stage framework that consists of entity tracking and knowledge ranking, and propose a multi-task learning method to learn multi-level semantic information by domain classification and entity selection. For the generation task, we adopt a cross-validation data process to improve pre-trained generative language models, followed by a consensus decoding algorithm, which can add arbitrary features like relative \rouge metric, and tune associated feature weights toward \bleu directly. Our approach ranks third on the objective evaluation and second on the final official human evaluation.
Precognition in Task-oriented Dialogue Understanding: Posterior Regularization by Future Context
Mar 07, 2022
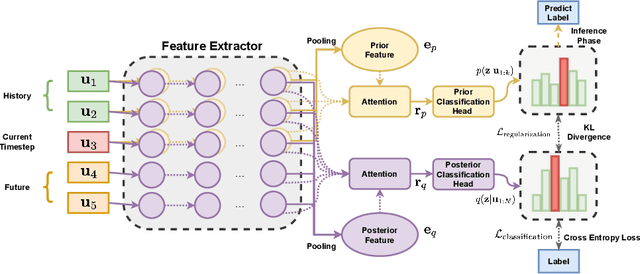

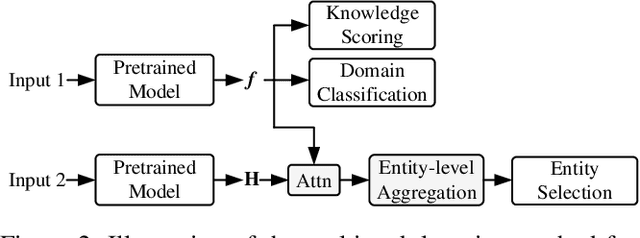
Task-oriented dialogue systems have become overwhelmingly popular in recent researches. Dialogue understanding is widely used to comprehend users' intent, emotion and dialogue state in task-oriented dialogue systems. Most previous works on such discriminative tasks only models current query or historical conversations. Even if in some work the entire dialogue flow was modeled, it is not suitable for the real-world task-oriented conversations as the future contexts are not visible in such cases. In this paper, we propose to jointly model historical and future information through the posterior regularization method. More specifically, by modeling the current utterance and past contexts as prior, and the entire dialogue flow as posterior, we optimize the KL distance between these distributions to regularize our model during training. And only historical information is used for inference. Extensive experiments on two dialogue datasets validate the effectiveness of our proposed method, achieving superior results compared with all baseline models.
HeteroQA: Learning towards Question-and-Answering through Multiple Information Sources via Heterogeneous Graph Modeling
Dec 27, 2021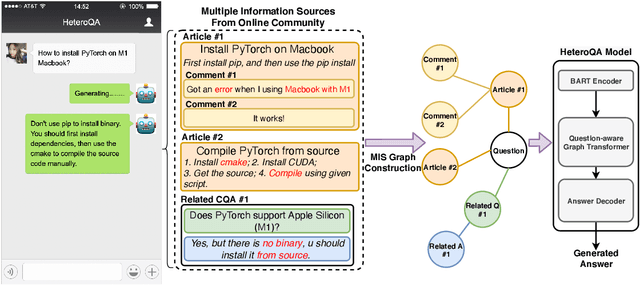

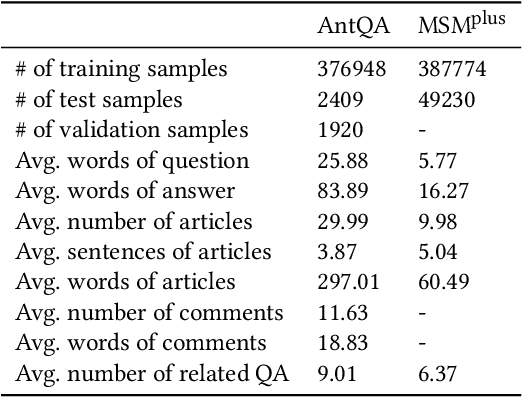
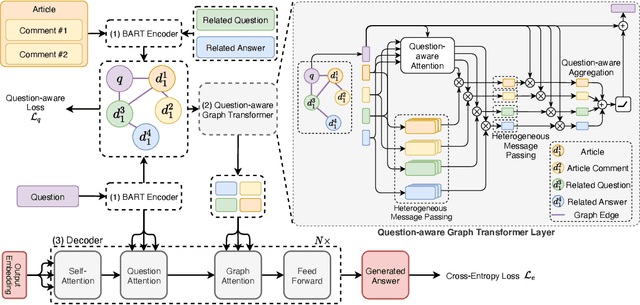
Community Question Answering (CQA) is a well-defined task that can be used in many scenarios, such as E-Commerce and online user community for special interests. In these communities, users can post articles, give comment, raise a question and answer it. These data form the heterogeneous information sources where each information source have their own special structure and context (comments attached to an article or related question with answers). Most of the CQA methods only incorporate articles or Wikipedia to extract knowledge and answer the user's question. However, various types of information sources in the community are not fully explored by these CQA methods and these multiple information sources (MIS) can provide more related knowledge to user's questions. Thus, we propose a question-aware heterogeneous graph transformer to incorporate the MIS in the user community to automatically generate the answer. To evaluate our proposed method, we conduct the experiments on two datasets: $\text{MSM}^{\text{plus}}$ the modified version of benchmark dataset MS-MARCO and the AntQA dataset which is the first large-scale CQA dataset with four types of MIS. Extensive experiments on two datasets show that our model outperforms all the baselines in terms of all the metrics.
AudioViewer: Learning to Visualize Sound
Dec 28, 2020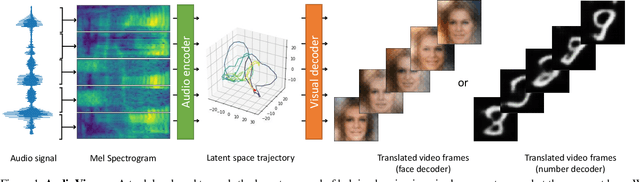
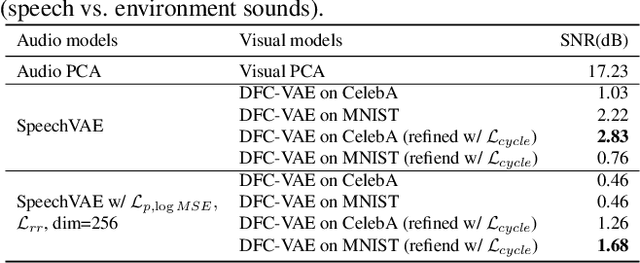

Sensory substitution can help persons with perceptual deficits. In this work, we attempt to visualize audio with video. Our long-term goal is to create sound perception for hearing impaired people, for instance, to facilitate feedback for training deaf speech. Different from existing models that translate between speech and text or text and images, we target an immediate and low-level translation that applies to generic environment sounds and human speech without delay. No canonical mapping is known for this artificial translation task. Our design is to translate from audio to video by compressing both into a common latent space with shared structure. Our core contribution is the development and evaluation of learned mappings that respect human perception limits and maximize user comfort by enforcing priors and combining strategies from unpaired image translation and disentanglement. We demonstrate qualitatively and quantitatively that our AudioViewer model maintains important audio features in the generated video and that generated videos of faces and numbers are well suited for visualizing high-dimensional audio features since they can easily be parsed by humans to match and distinguish between sounds, words, and speakers.