 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioViewer: Learning to Visualize Sound
Dec 28, 2020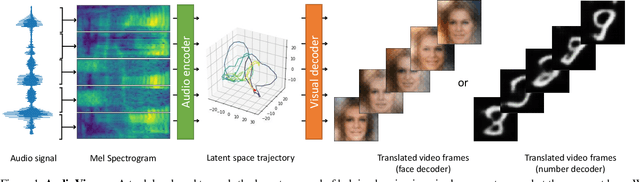
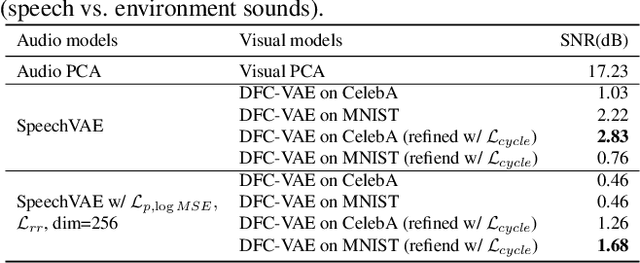

Sensory substitution can help persons with perceptual deficits. In this work, we attempt to visualize audio with video. Our long-term goal is to create sound perception for hearing impaired people, for instance, to facilitate feedback for training deaf speech. Different from existing models that translate between speech and text or text and images, we target an immediate and low-level translation that applies to generic environment sounds and human speech without delay. No canonical mapping is known for this artificial translation task. Our design is to translate from audio to video by compressing both into a common latent space with shared structure. Our core contribution is the development and evaluation of learned mappings that respect human perception limits and maximize user comfort by enforcing priors and combining strategies from unpaired image translation and disentanglement. We demonstrate qualitatively and quantitatively that our AudioViewer model maintains important audio features in the generated video and that generated videos of faces and numbers are well suited for visualizing high-dimensional audio features since they can easily be parsed by humans to match and distinguish between sounds, words, and speakers.