 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextDestroyer: A Training- and Annotation-Free Diffusion Method for Destroying Anomal Text from Images
Nov 01, 2024In this paper, we propose TextDestroyer, the first training- and annotation-free method for scene text destruction using a pre-trained diffusion model. Existing scene text removal models require complex annotation and retraining, and may leave faint yet recognizable text information, compromising privacy protection and content concealment. TextDestroyer addresses these issues by employing a three-stage hierarchical process to obtain accurate text masks. Our method scrambles text areas in the latent start code using a Gaussian distribution before reconstruction. During the diffusion denoising process, self-attention key and value are referenced from the original latent to restore the compromised background. Latent codes saved at each inversion step are used for replacement during reconstruction, ensuring perfect background restoration. The advantages of TextDestroyer include: (1) it eliminates labor-intensive data annotation and resource-intensive training; (2) it achieves more thorough text destruction, preventing recognizable traces; and (3) it demonstrates better generalization capabilities, performing well on both real-world scenes and generated images.
ManiDext: Hand-Object Manipulation Synthesis via Continuous Correspondence Embeddings and Residual-Guided Diffusion
Sep 14, 2024Dynamic and dexterous manipulation of objects presents a complex challenge, requiring the synchronization of hand motions with the trajectories of objects to achieve seamless and physically plausible interactions. In this work, we introduce ManiDext, a unified hierarchical diffusion-based framework for generating hand manipulation and grasp poses based on 3D object trajectories. Our key insight is that accurately modeling the contact correspondences between objects and hands during interactions is crucial. Therefore, we propose a continuous correspondence embedding representation that specifies detailed hand correspondences at the vertex level between the object and the hand. This embedding is optimized directly on the hand mesh in a self-supervised manner, with the distance between embeddings reflecting the geodesic distance. Our framework first generates contact maps and correspondence embeddings on the object's surface. Based on these fine-grained correspondences, we introduce a novel approach that integrates the iterative refinement process into the diffusion process during the second stage of hand pose generation. At each step of the denoising process, we incorporate the current hand pose residual as a refinement target into the network, guiding the network to correct inaccurate hand poses. Introducing residuals into each denoising step inherently aligns with traditional optimization process, effectively merging generation and refinement into a single unified framework. Extensive experiments demonstrate that our approach can generate physically plausible and highly realistic motions for various tasks, including single and bimanual hand grasping as well as manipulating both rigid and articulated objects. Code will be available for research purposes.
HHMR: Holistic Hand Mesh Recovery by Enhancing the Multimodal Controllability of Graph Diffusion Models
Jun 03, 2024Recent years have witnessed a trend of the deep integration of the generation and reconstruction paradigms. In this paper, we extend the ability of controllable generative models for a more comprehensive hand mesh recovery task: direct hand mesh generation, inpainting, reconstruction, and fitting in a single framework, which we name as Holistic Hand Mesh Recovery (HHMR). Our key observation is that different kinds of hand mesh recovery tasks can be achieved by a single generative model with strong multimodal controllability, and in such a framework, realizing different tasks only requires giving different signals as conditions. To achieve this goal, we propose an all-in-one diffusion framework based on graph convolution and attention mechanisms for holistic hand mesh recovery. In order to achieve strong control generation capability while ensuring the decoupling of multimodal control signals, we map different modalities to a shared feature space and apply cross-scale random masking in both modality and feature levels. In this way, the correlation between different modalities can be fully exploited during the learning of hand priors. Furthermore, we propose Condition-aligned Gradient Guidance to enhance the alignment of the generated model with the control signals, which significantly improves the accuracy of the hand mesh reconstruction and fitting. Experiments show that our novel framework can realize multiple hand mesh recovery tasks simultaneously and outperform the existing methods in different tasks, which provides more possibilities for subsequent downstream applications including gesture recognition, pose generation, mesh editing, and so on.
4DHands: Reconstructing Interactive Hands in 4D with Transformers
May 31, 2024In this paper, we introduce 4DHands, a robust approach to recovering interactive hand meshes and their relative movement from monocular inputs. Our approach addresses two major limitations of previous methods: lacking a unified solution for handling various hand image inputs and neglecting the positional relationship of two hands within images. To overcome these challenges, we develop a transformer-based architecture with novel tokenization and feature fusion strategies. Specifically, we propose a Relation-aware Two-Hand Tokenization (RAT) method to embed positional relation information into the hand tokens. In this way, our network can handle both single-hand and two-hand inputs and explicitly leverage relative hand positions, facilitating the reconstruction of intricate hand interactions in real-world scenarios. As such tokenization indicates the relative relationship of two hands, it also supports more effective feature fusion. To this end, we further develop a Spatio-temporal Interaction Reasoning (SIR) module to fuse hand tokens in 4D with attention and decode them into 3D hand meshes and relative temporal movements. The efficacy of our approach is validated on several benchmark datasets. The results on in-the-wild videos and real-world scenarios demonstrate the superior performances of our approach for interactive hand reconstruction. More video results can be found on the project page: https://4dhands.github.io.
Learning Explicit Contact for Implicit Reconstruction of Hand-held Objects from Monocular Images
May 31, 2023Reconstructing hand-held objects from monocular RGB images is an appealing yet challenging task. In this task, contacts between hands and objects provide important cues for recovering the 3D geometry of the hand-held objects. Though recent works have employed implicit functions to achieve impressive progress, they ignore formulating contacts in their frameworks, which results in producing less realistic object meshes. In this work, we explore how to model contacts in an explicit way to benefit the implicit reconstruction of hand-held objects. Our method consists of two components: explicit contact prediction and implicit shape reconstruction. In the first part, we propose a new subtask of directly estimating 3D hand-object contacts from a single image. The part-level and vertex-level graph-based transformers are cascaded and jointly learned in a coarse-to-fine manner for more accurate contact probabilities. In the second part, we introduce a novel method to diffuse estimated contact states from the hand mesh surface to nearby 3D space and leverage diffused contact probabilities to construct the implicit neural representation for the manipulated object. Benefiting from estimating the interaction patterns between the hand and the object, our method can reconstruct more realistic object meshes, especially for object parts that are in contact with hands. Extensive experiments on challenging benchmarks show that the proposed method outperforms the current state of the arts by a great margin.
PyMAF-X: Towards Well-aligned Full-body Model Regression from Monocular Images
Jul 18, 2022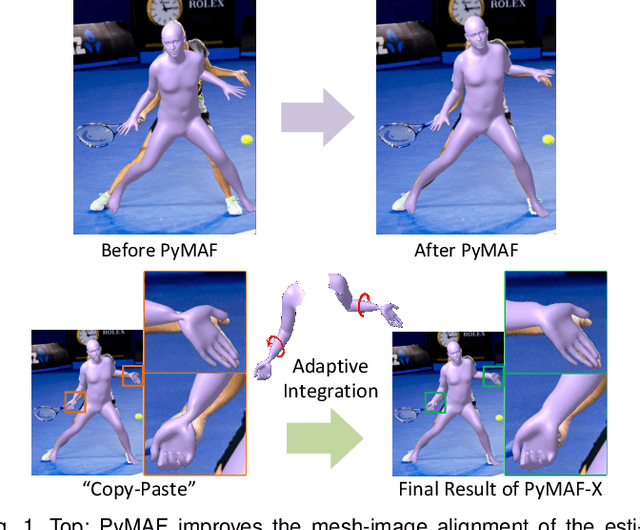
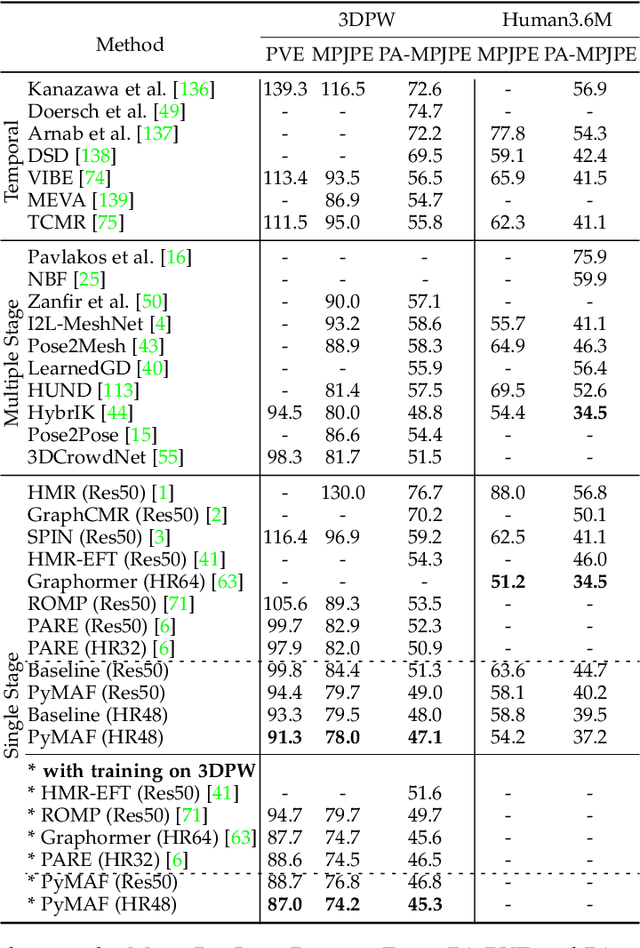
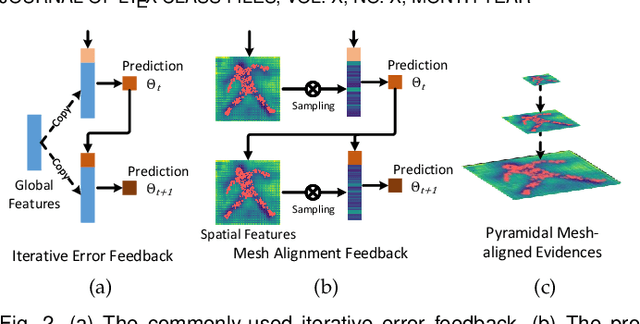
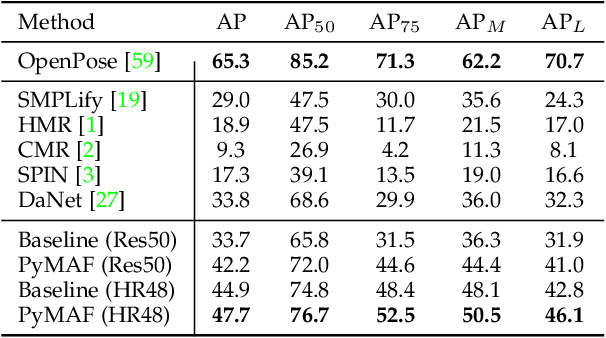
We present PyMAF-X, a regression-based approach to recovering a full-body parametric model from a single image. This task is very challenging since minor parametric deviation may lead to noticeable misalignment between the estimated mesh and the input image. Moreover, when integrating part-specific estimations to the full-body model, existing solutions tend to either degrade the alignment or produce unnatural wrist poses. To address these issues, we propose a Pyramidal Mesh Alignment Feedback (PyMAF) loop in our regression network for well-aligned human mesh recovery and extend it as PyMAF-X for the recovery of expressive full-body models. The core idea of PyMAF is to leverage a feature pyramid and rectify the predicted parameters explicitly based on the mesh-image alignment status. Specifically, given the currently predicted parameters, mesh-aligned evidence will be extracted from finer-resolution features accordingly and fed back for parameter rectification. To enhance the alignment perception, an auxiliary dense supervision is employed to provide mesh-image correspondence guidance while spatial alignment attention is introduced to enable the awareness of the global contexts for our network. When extending PyMAF for full-body mesh recovery, an adaptive integration strategy is proposed in PyMAF-X to produce natural wrist poses while maintaining the well-aligned performance of the part-specific estimations. The efficacy of our approach is validated on several benchmark datasets for body-only and full-body mesh recovery, where PyMAF and PyMAF-X effectively improve the mesh-image alignment and achieve new state-of-the-art results. The project page with code and video results can be found at https://www.liuyebin.com/pymaf-x.
Interacting Attention Graph for Single Image Two-Hand Reconstruction
Mar 18, 2022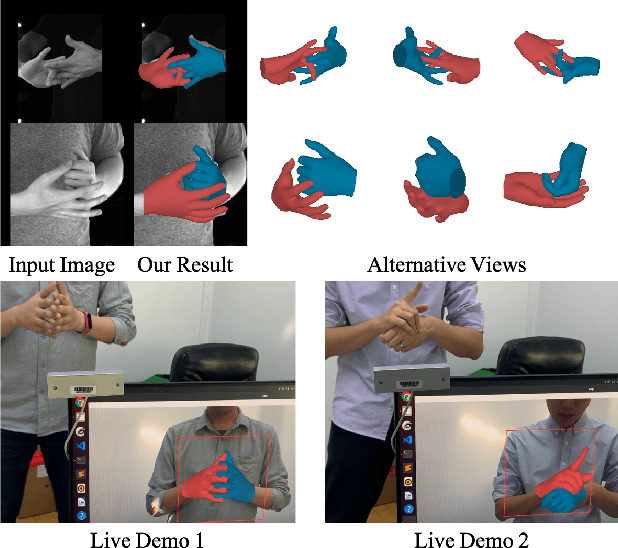
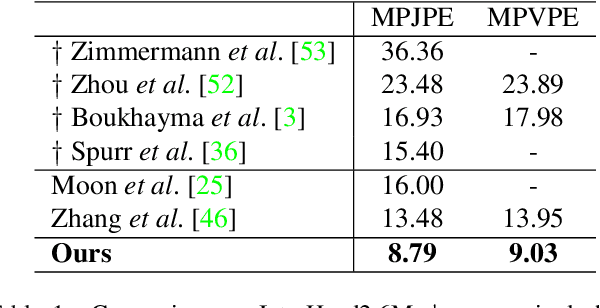
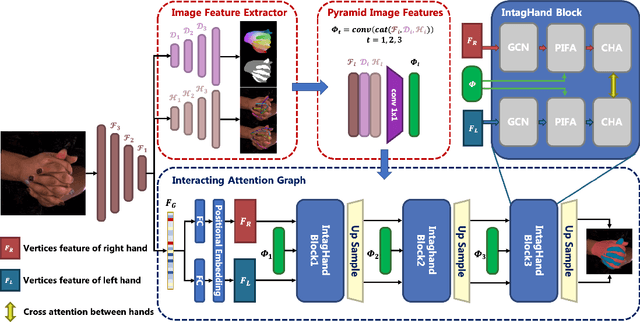
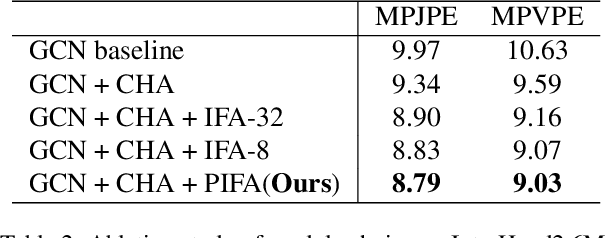
Graph convolutional network (GCN) has achieved great success in single hand reconstruction task, while interacting two-hand reconstruction by GCN remains unexplored. In this paper, we present Interacting Attention Graph Hand (IntagHand), the first graph convolution based network that reconstructs two interacting hands from a single RGB image. To solve occlusion and interaction challenges of two-hand reconstruction, we introduce two novel attention based modules in each upsampling step of the original GCN. The first module is the pyramid image feature attention (PIFA) module, which utilizes multiresolution features to implicitly obtain vertex-to-image alignment. The second module is the cross hand attention (CHA) module that encodes the coherence of interacting hands by building dense cross-attention between two hand vertices. As a result, our model outperforms all existing two-hand reconstruction methods by a large margin on InterHand2.6M benchmark. Moreover, ablation studies verify the effectiveness of both PIFA and CHA modules for improving the reconstruction accuracy. Results on in-the-wild images and live video streams further demonstrate the generalization ability of our network. Our code is available at https://github.com/Dw1010/IntagHand.
Lightweight Multi-person Total Motion Capture Using Sparse Multi-view Cameras
Aug 23, 2021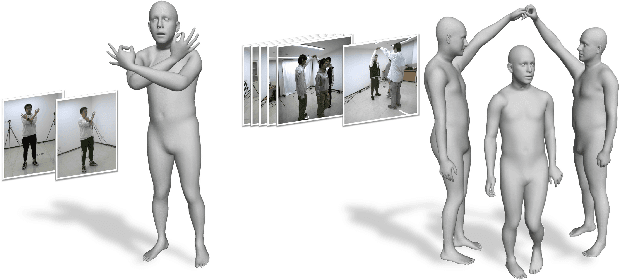
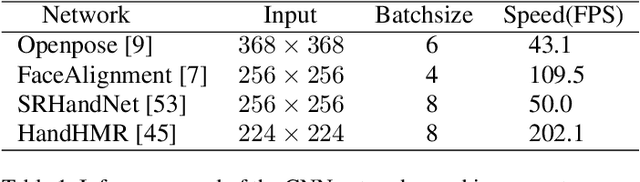
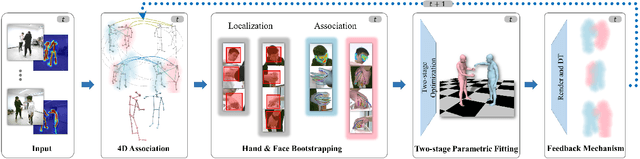
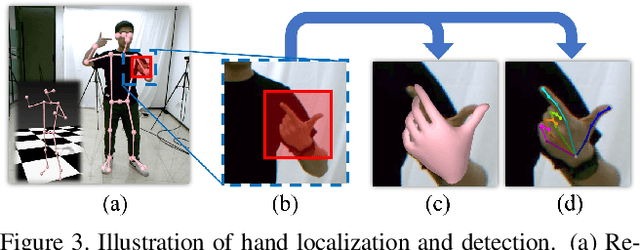
Multi-person total motion capture is extremely challenging when it comes to handle severe occlusions, different reconstruction granularities from body to face and hands, drastically changing observation scales and fast body movements. To overcome these challenges above, we contribute a lightweight total motion capture system for multi-person interactive scenarios using only sparse multi-view cameras. By contributing a novel hand and face bootstrapping algorithm, our method is capable of efficient localization and accurate association of the hands and faces even on severe occluded occasions. We leverage both pose regression and keypoints detection methods and further propose a unified two-stage parametric fitting method for achieving pixel-aligned accuracy. Moreover, for extremely self-occluded poses and close interactions, a novel feedback mechanism is proposed to propagate the pixel-aligned reconstructions into the next frame for more accurate association. Overall, we propose the first light-weight total capture system and achieves fast, robust and accurate multi-person total motion capture performance. The results and experiments show that our method achieves more accurate results than existing methods under sparse-view setups.