 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyMAF-X: Towards Well-aligned Full-body Model Regression from Monocular Images
Jul 18, 2022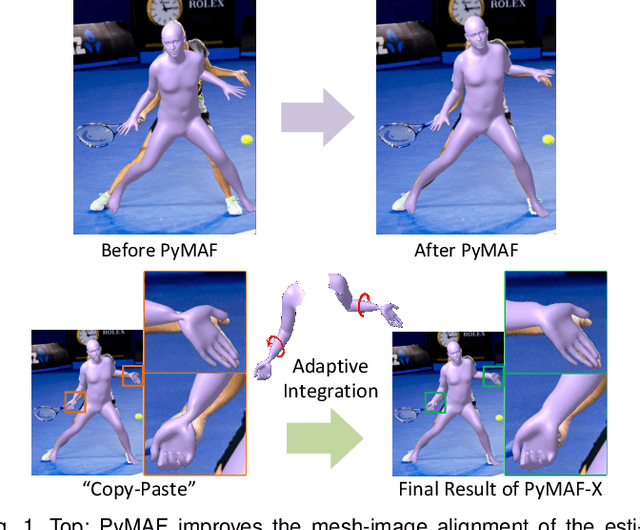
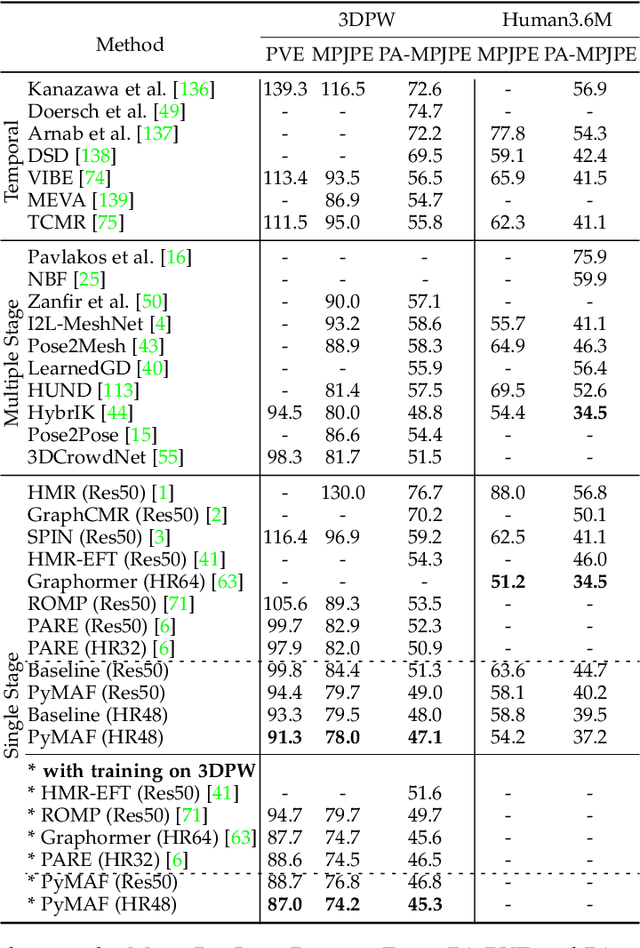
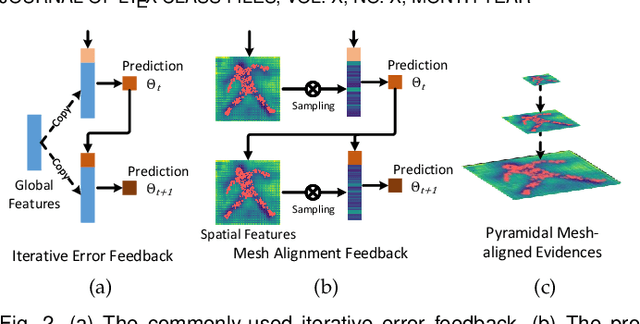
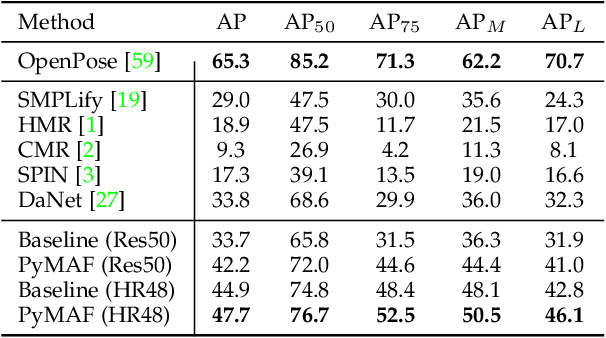
We present PyMAF-X, a regression-based approach to recovering a full-body parametric model from a single image. This task is very challenging since minor parametric deviation may lead to noticeable misalignment between the estimated mesh and the input image. Moreover, when integrating part-specific estimations to the full-body model, existing solutions tend to either degrade the alignment or produce unnatural wrist poses. To address these issues, we propose a Pyramidal Mesh Alignment Feedback (PyMAF) loop in our regression network for well-aligned human mesh recovery and extend it as PyMAF-X for the recovery of expressive full-body models. The core idea of PyMAF is to leverage a feature pyramid and rectify the predicted parameters explicitly based on the mesh-image alignment status. Specifically, given the currently predicted parameters, mesh-aligned evidence will be extracted from finer-resolution features accordingly and fed back for parameter rectification. To enhance the alignment perception, an auxiliary dense supervision is employed to provide mesh-image correspondence guidance while spatial alignment attention is introduced to enable the awareness of the global contexts for our network. When extending PyMAF for full-body mesh recovery, an adaptive integration strategy is proposed in PyMAF-X to produce natural wrist poses while maintaining the well-aligned performance of the part-specific estimations. The efficacy of our approach is validated on several benchmark datasets for body-only and full-body mesh recovery, where PyMAF and PyMAF-X effectively improve the mesh-image alignment and achieve new state-of-the-art results. The project page with code and video results can be found at https://www.liuyebin.com/pymaf-x.
Recovering 3D Human Mesh from Monocular Images: A Survey
Mar 08, 2022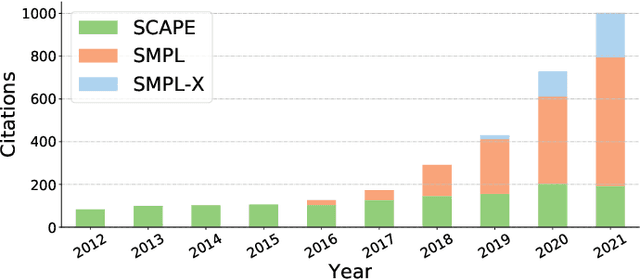



Estimating human pose and shape from monocular images is a long-standing problem in computer vision. Since the release of statistical body models, 3D human mesh recovery has been drawing broader attention. With the same goal of obtaining well-aligned and physically plausible mesh results, two paradigms have been developed to overcome challenges in the 2D-to-3D lifting process: i) an optimization-based paradigm, where different data terms and regularization terms are exploited as optimization objectives; and ii) a regression-based paradigm, where deep learning techniques are embraced to solve the problem in an end-to-end fashion. Meanwhile, continuous efforts are devoted to improving the quality of 3D mesh labels for a wide range of datasets. Though remarkable progress has been achieved in the past decade, the task is still challenging due to flexible body motions, diverse appearances, complex environments, and insufficient in-the-wild annotations. To the best of our knowledge, this is the first survey to focus on the task of monocular 3D human mesh recovery. We start with the introduction of body models and then elaborate recovery frameworks and training objectives by providing in-depth analyses of their strengths and weaknesses. We also summarize datasets, evaluation metrics, and benchmark results. Open issues and future directions are discussed in the end, hoping to motivate researchers and facilitate their research in this area. A regularly updated project page can be found at https://github.com/tinatiansjz/hmr-survey.
Hateful Memes Challenge: An Enhanced Multimodal Framework
Dec 20, 2021


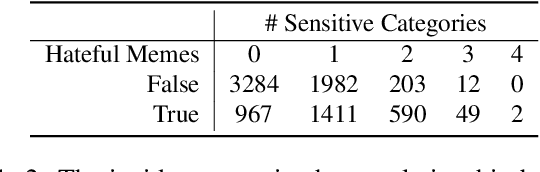
Hateful Meme Challenge proposed by Facebook AI has attracted contestants around the world. The challenge focuses on detecting hateful speech in multimodal memes. Various state-of-the-art deep learning models have been applied to this problem and the performance on challenge's leaderboard has also been constantly improved. In this paper, we enhance the hateful detection framework, including utilizing Detectron for feature extraction, exploring different setups of VisualBERT and UNITER models with different loss functions, researching the association between the hateful memes and the sensitive text features, and finally building ensemble method to boost model performance. The AUROC of our fine-tuned VisualBERT, UNITER, and ensemble method achieves 0.765, 0.790, and 0.803 on the challenge's test set, respectively, which beats the baseline models. Our code is available at https://github.com/yatingtian/hateful-meme
3D Human Pose and Shape Regression with Pyramidal Mesh Alignment Feedback Loop
Apr 01, 2021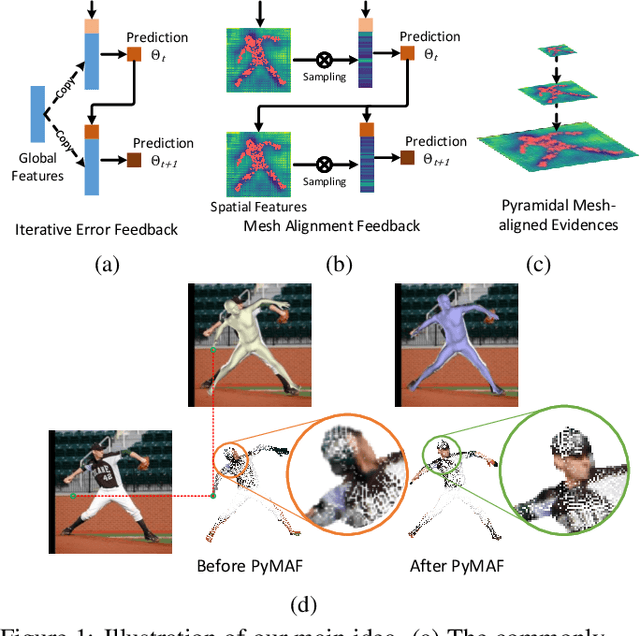



Regression-based methods have recently shown promising results in reconstructing human meshes from monocular images. By directly mapping from raw pixels to model parameters, these methods can produce parametric models in a feed-forward manner via neural networks. However, minor deviation in parameters may lead to noticeable misalignment between the estimated meshes and image evidences. To address this issue, we propose a Pyramidal Mesh Alignment Feedback (PyMAF) loop to leverage a feature pyramid and rectify the predicted parameters explicitly based on the mesh-image alignment status in our deep regressor. In PyMAF, given the currently predicted parameters, mesh-aligned evidences will be extracted from finer-resolution features accordingly and fed back for parameter rectification. To reduce noise and enhance the reliability of these evidences, an auxiliary pixel-wise supervision is imposed on the feature encoder, which provides mesh-image correspondence guidance for our network to preserve the most related information in spatial features. The efficacy of our approach is validated on several benchmarks, including Human3.6M, 3DPW, LSP, and COCO, where experimental results show that our approach consistently improves the mesh-image alignment of the reconstruction. Our code is publicly available at https://hongwenzhang.github.io/pymaf .