 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeCo: Separating Unknown Musical Visual Sounds with Consistency Guidance
Mar 25, 2022
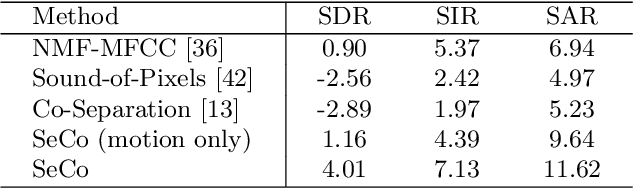
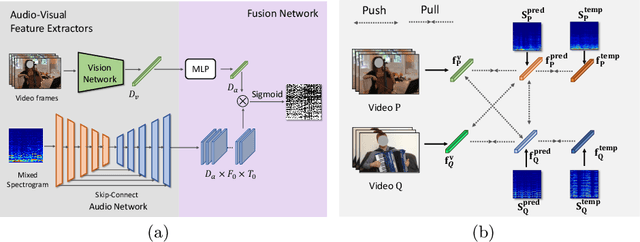

Recent years have witnessed the success of deep learning on the visual sound separation task. However, existing works follow similar settings where the training and testing datasets share the same musical instrument categories, which to some extent limits the versatility of this task. In this work, we focus on a more general and challenging scenario, namely the separation of unknown musical instruments, where the categories in training and testing phases have no overlap with each other. To tackle this new setting, we propose the Separation-with-Consistency (SeCo) framework, which can accomplish the separation on unknown categories by exploiting the consistency constraints. Furthermore, to capture richer characteristics of the novel melodies, we devise an online matching strategy, which can bring stable enhancements with no cost of extra parameters. Experiments demonstrate that our SeCo framework exhibits strong adaptation ability on the novel musical categories and outperforms the baseline methods by a significant margin.
3D Human Pose and Shape Regression with Pyramidal Mesh Alignment Feedback Loop
Apr 01, 2021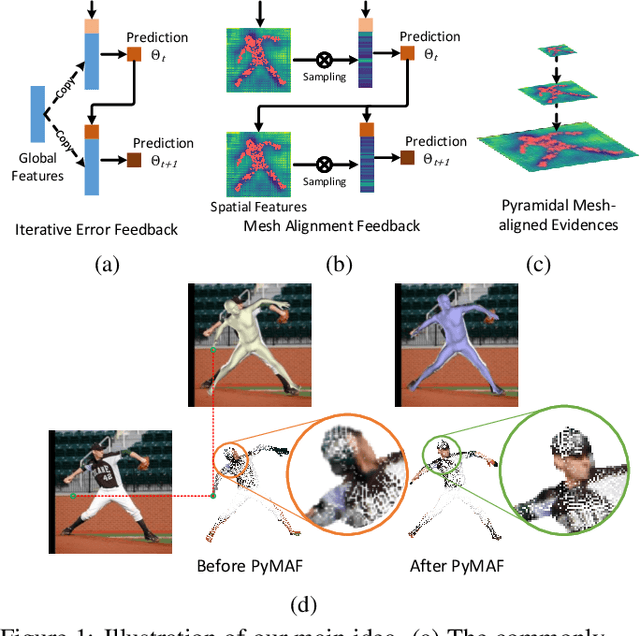



Regression-based methods have recently shown promising results in reconstructing human meshes from monocular images. By directly mapping from raw pixels to model parameters, these methods can produce parametric models in a feed-forward manner via neural networks. However, minor deviation in parameters may lead to noticeable misalignment between the estimated meshes and image evidences. To address this issue, we propose a Pyramidal Mesh Alignment Feedback (PyMAF) loop to leverage a feature pyramid and rectify the predicted parameters explicitly based on the mesh-image alignment status in our deep regressor. In PyMAF, given the currently predicted parameters, mesh-aligned evidences will be extracted from finer-resolution features accordingly and fed back for parameter rectification. To reduce noise and enhance the reliability of these evidences, an auxiliary pixel-wise supervision is imposed on the feature encoder, which provides mesh-image correspondence guidance for our network to preserve the most related information in spatial features. The efficacy of our approach is validated on several benchmarks, including Human3.6M, 3DPW, LSP, and COCO, where experimental results show that our approach consistently improves the mesh-image alignment of the reconstruction. Our code is publicly available at https://hongwenzhang.github.io/pymaf .
BriNet: Towards Bridging the Intra-class and Inter-class Gaps in One-Shot Segmentation
Aug 14, 2020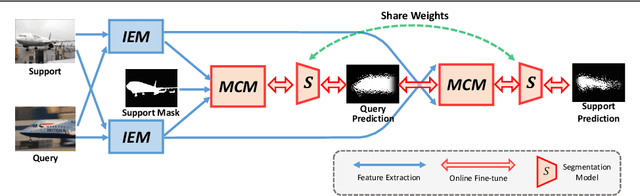


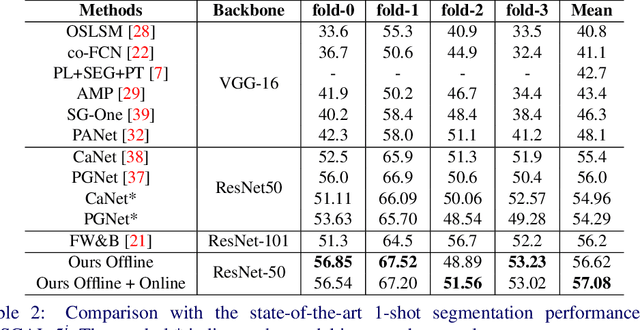
Few-shot segmentation focuses on the generalization of models to segment unseen object instances with limited training samples. Although tremendous improvements have been achieved, existing methods are still constrained by two factors. (1) The information interaction between query and support images is not adequate, leaving intra-class gap. (2) The object categories at the training and inference stages have no overlap, leaving the inter-class gap. Thus, we propose a framework, BriNet, to bridge these gaps. First, more information interactions are encouraged between the extracted features of the query and support images, i.e., using an Information Exchange Module to emphasize the common objects. Furthermore, to precisely localize the query objects, we design a multi-path fine-grained strategy which is able to make better use of the support feature representations. Second, a new online refinement strategy is proposed to help the trained model adapt to unseen classes, achieved by switching the roles of the query and the support images at the inference stage. The effectiveness of our framework is demonstrated by experimental results, which outperforms other competitive methods and leads to a new state-of-the-art on both PASCAL VOC and MSCOCO dataset.
Cheaper Pre-training Lunch: An Efficient Paradigm for Object Detection
Apr 25, 2020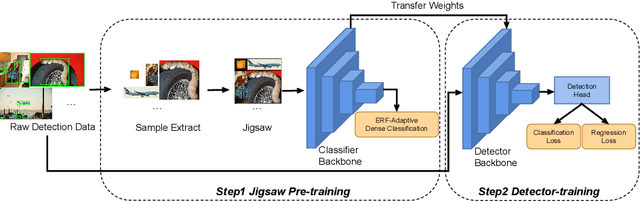



In this paper, we propose a general and efficient pre-training paradigm, Jigsaw pre-training, for object detection. Jigsaw pre-training needs only the target detection dataset while taking only 1/4 computational resources compared to the widely adopted ImageNet pre-training. To build such an efficient paradigm, we reduce the potential redundancy by carefully extracting useful samples from the original images, assembling samples in a Jigsaw manner as input, and using an ERF-adaptive dense classification strategy for model pre-training. These designs include not only a new input pattern to improve the spatial utilization but also a novel learning objective to expand the effective receptive field of the pre-trained model. The efficiency and superiority of Jigsaw pre-training are validated by extensive experiments on the MS-COCO dataset, where the results indicate that the models using Jigsaw pre-training are able to achieve on-par or even better detection performances compared with the ImageNet pre-trained counterparts.
MagnifierNet: Towards Semantic Regularization and Fusion for Person Re-identification
Feb 26, 2020
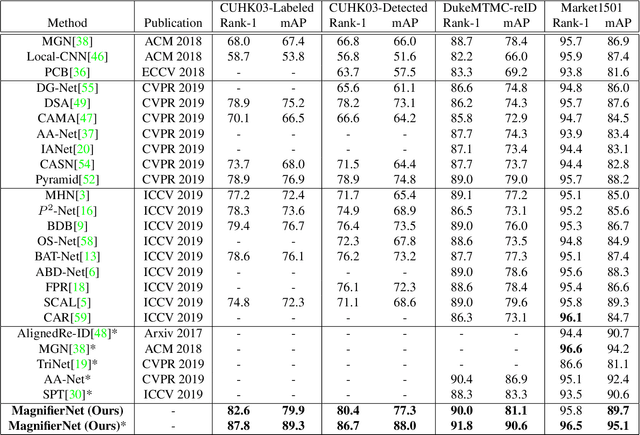
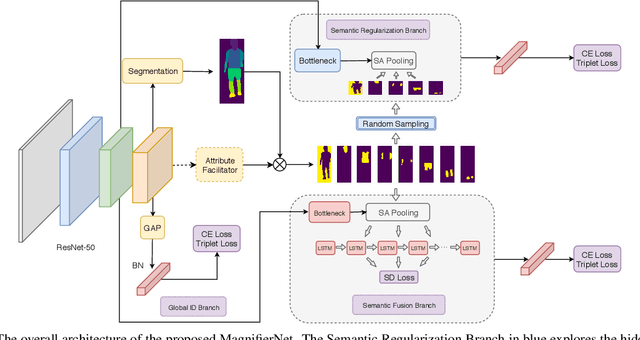
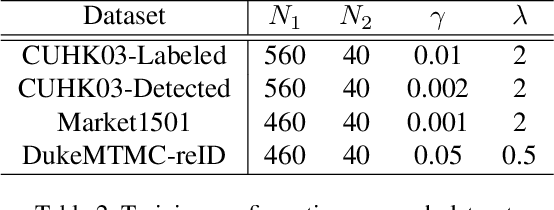
Although person re-identification (ReID) has achieved significant improvement recently by enforcing part alignment, it is still a challenging task when it comes to distinguishing visually similar identities or identifying occluded person. In these scenarios, magnifying details in each part features and selectively fusing them together may provide a feasible solution. In this paper, we propose MagnifierNet, a novel network which accurately mines details for each semantic region and selectively fuse all semantic feature representations. Apart from conventional global branch, our proposed network is composed of a Semantic Regularization Branch (SRB) as learning regularizer and a Semantic Fusion Branch (SFB) towards selectively semantic fusion. The SRB learns with limited number of semantic regions randomly sampled in each batch, which forces the network to learn detailed representation for each semantic region, and the SFB selectively fuses semantic region information in a sequential manner, focusing on beneficial information while neglecting irrelevant features or noises. In addition, we introduce a novel loss function "Semantic Diversity Loss" (SD Loss) to facilitate feature diversity and improves regularization among all semantic regions. State-of-the-art performance has been achieved on multiple datasets by large margins. Notably, we improve SOTA on CUHK03-Labeled Dataset by 12.6% in mAP and 8.9% in Rank-1. We also outperform existing works on CUHK03-Detected Dataset by 13.2% in mAP and 7.8% in Rank-1 respectively, which demonstrates the effectiveness of our method.
EcoNAS: Finding Proxies for Economical Neural Architecture Search
Jan 05, 2020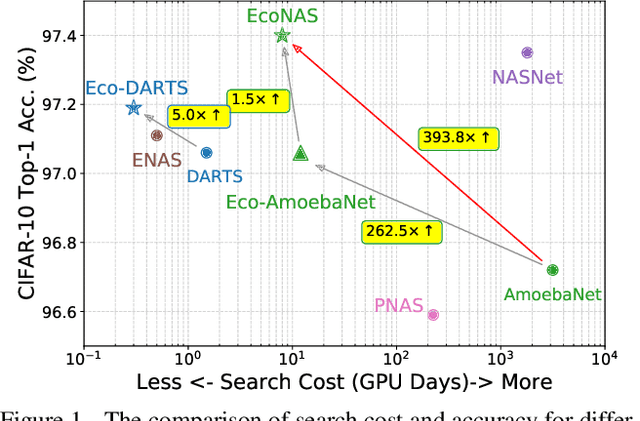
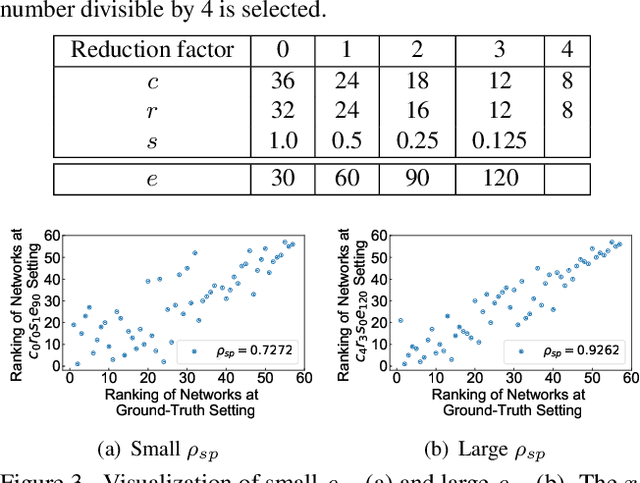
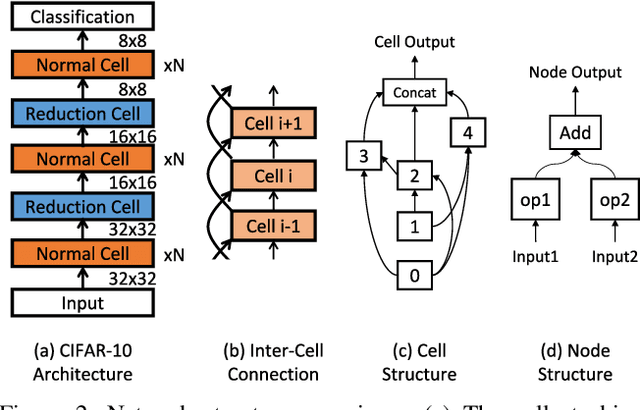
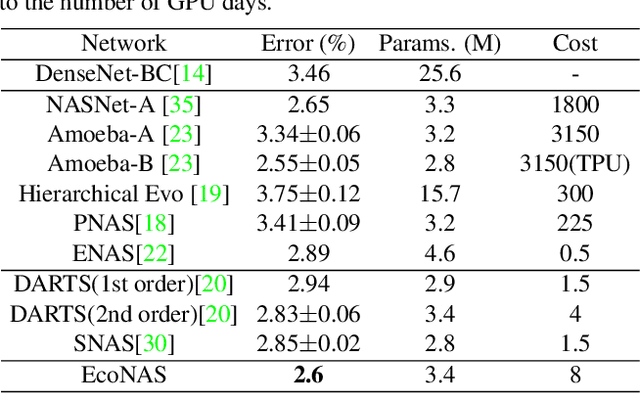
Neural Architecture Search (NAS) achieves significant progress in many computer vision tasks. While many methods have been proposed to improve the efficiency of NAS, the search progress is still laborious because training and evaluating plausible architectures over large search space is time-consuming. Assessing network candidates under a proxy (i.e., computationally reduced setting) thus becomes inevitable. In this paper, we observe that most existing proxies exhibit different behaviors in maintaining the rank consistency among network candidates. In particular, some proxies can be more reliable -- the rank of candidates does not differ much comparing their reduced setting performance and final performance. In this paper, we systematically investigate some widely adopted reduction factors and report our observations. Inspired by these observations, we present a reliable proxy and further formulate a hierarchical proxy strategy. The strategy spends more computations on candidate networks that are potentially more accurate, while discards unpromising ones in early stage with a fast proxy. This leads to an economical evolutionary-based NAS (EcoNAS), which achieves an impressive 400x search time reduction in comparison to the evolutionary-based state of the art (8 vs. 3150 GPU days). Some new proxies led by our observations can also be applied to accelerate other NAS methods while still able to discover good candidate networks with performance matching those found by previous proxy strategies.