 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagnifierNet: Towards Semantic Regularization and Fusion for Person Re-identification
Paper and Code

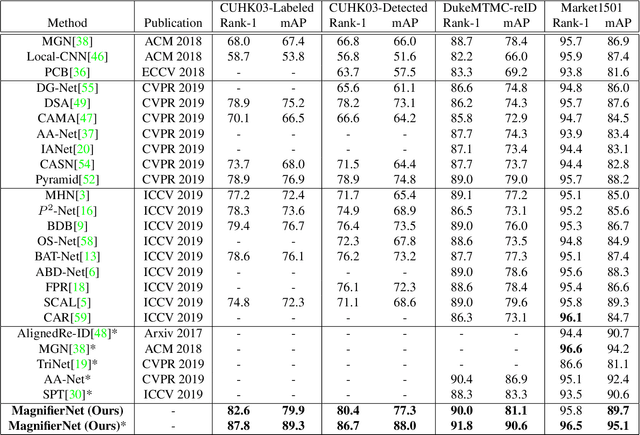
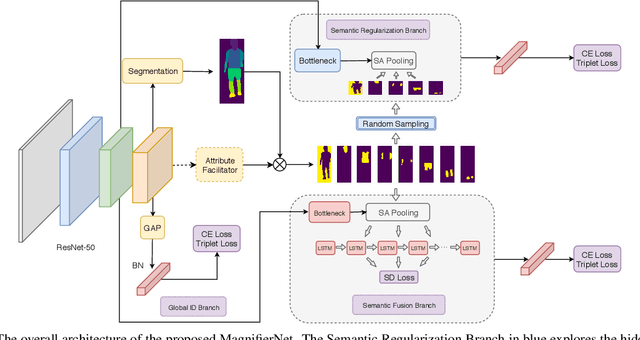
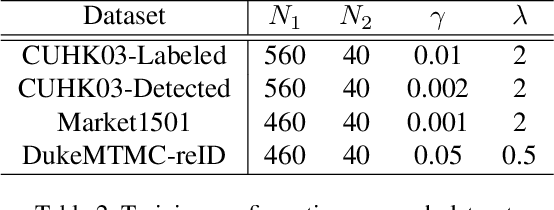
Although person re-identification (ReID) has achieved significant improvement recently by enforcing part alignment, it is still a challenging task when it comes to distinguishing visually similar identities or identifying occluded person. In these scenarios, magnifying details in each part features and selectively fusing them together may provide a feasible solution. In this paper, we propose MagnifierNet, a novel network which accurately mines details for each semantic region and selectively fuse all semantic feature representations. Apart from conventional global branch, our proposed network is composed of a Semantic Regularization Branch (SRB) as learning regularizer and a Semantic Fusion Branch (SFB) towards selectively semantic fusion. The SRB learns with limited number of semantic regions randomly sampled in each batch, which forces the network to learn detailed representation for each semantic region, and the SFB selectively fuses semantic region information in a sequential manner, focusing on beneficial information while neglecting irrelevant features or noises. In addition, we introduce a novel loss function "Semantic Diversity Loss" (SD Loss) to facilitate feature diversity and improves regularization among all semantic regions. State-of-the-art performance has been achieved on multiple datasets by large margins. Notably, we improve SOTA on CUHK03-Labeled Dataset by 12.6% in mAP and 8.9% in Rank-1. We also outperform existing works on CUHK03-Detected Dataset by 13.2% in mAP and 7.8% in Rank-1 respectively, which demonstrates the effectiveness of our method.