 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Clinical Data Extraction with Knowledge Conditioned LLMs
Jun 26, 2024



The extraction of lung lesion information from clinical and medical imaging reports is crucial for research on and clinical care of lung-related diseases. Large language models (LLMs) can be effective at interpreting unstructured text in reports, but they often hallucinate due to a lack of domain-specific knowledge, leading to reduced accuracy and posing challenges for use in clinical settings. To address this, we propose a novel framework that aligns generated internal knowledge with external knowledge through in-context learning (ICL). Our framework employs a retriever to identify relevant units of internal or external knowledge and a grader to evaluate the truthfulness and helpfulness of the retrieved internal-knowledge rules, to align and update the knowledge bases. Our knowledge-conditioned approach also improves the accuracy and reliability of LLM outputs by addressing the extraction task in two stages: (i) lung lesion finding detection and primary structured field parsing, followed by (ii) further parsing of lesion description text into additional structured fields. Experiments with expert-curated test datasets demonstrate that this ICL approach can increase the F1 score for key fields (lesion size, margin and solidity) by an average of 12.9% over existing ICL methods.
Hateful Memes Challenge: An Enhanced Multimodal Framework
Dec 20, 2021


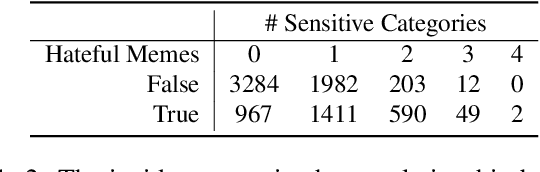
Hateful Meme Challenge proposed by Facebook AI has attracted contestants around the world. The challenge focuses on detecting hateful speech in multimodal memes. Various state-of-the-art deep learning models have been applied to this problem and the performance on challenge's leaderboard has also been constantly improved. In this paper, we enhance the hateful detection framework, including utilizing Detectron for feature extraction, exploring different setups of VisualBERT and UNITER models with different loss functions, researching the association between the hateful memes and the sensitive text features, and finally building ensemble method to boost model performance. The AUROC of our fine-tuned VisualBERT, UNITER, and ensemble method achieves 0.765, 0.790, and 0.803 on the challenge's test set, respectively, which beats the baseline models. Our code is available at https://github.com/yatingtian/hateful-meme