 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyHand: A Large-Scale Synthetic Dataset for RGB(-D) Hand Pose Estimation
Mar 26, 2026We present AnyHand, a large-scale synthetic dataset designed to advance the state of the art in 3D hand pose estimation from both RGB-only and RGB-D inputs. While recent works with foundation approaches have shown that an increase in the quantity and diversity of training data can markedly improve performance and robustness in hand pose estimation, existing real-world-collected datasets on this task are limited in coverage, and prior synthetic datasets rarely provide occlusions, arm details, and aligned depth together at scale. To address this bottleneck, our AnyHand contains 2.5M single-hand and 4.1M hand-object interaction RGB-D images, with rich geometric annotations. In the RGB-only setting, we show that extending the original training sets of existing baselines with AnyHand yields significant gains on multiple benchmarks (FreiHAND and HO-3D), even when keeping the architecture and training scheme fixed. More impressively, the model trained with AnyHand shows stronger generalization to the out-of-domain HO-Cap dataset, without any fine-tuning. We also contribute a lightweight depth fusion module that can be easily integrated into existing RGB-based models. Trained with AnyHand, the resulting RGB-D model achieves superior performance on the HO-3D benchmark, showing the benefits of depth integration and the effectiveness of our synthetic data.
Do You See What I Am Pointing At? Gesture-Based Egocentric Video Question Answering
Mar 13, 2026Understanding and answering questions based on a user's pointing gesture is essential for next-generation egocentric AI assistants. However, current Multimodal Large Language Models (MLLMs) struggle with such tasks due to the lack of gesture-rich data and their limited ability to infer fine-grained pointing intent from egocentric video. To address this, we introduce EgoPointVQA, a dataset and benchmark for gesture-grounded egocentric question answering, comprising 4000 synthetic and 400 real-world videos across multiple deictic reasoning tasks. Built upon it, we further propose Hand Intent Tokens (HINT), which encodes tokens derived from 3D hand keypoints using an off-the-shelf reconstruction model and interleaves them with the model input to provide explicit spatial and temporal context for interpreting pointing intent. We show that our model outperforms others in different backbones and model sizes. In particular, HINT-14B achieves 68.1% accuracy, on average over 6 tasks, surpassing the state-of-the-art, InternVL3-14B, by 6.6%. To further facilitate the open research, we will release the code, model, and dataset. Project page: https://yuuraa.github.io/papers/choi2026egovqa
UniMorphGrasp: Diffusion Model with Morphology-Awareness for Cross-Embodiment Dexterous Grasp Generation
Jan 31, 2026Cross-embodiment dexterous grasping aims to generate stable and diverse grasps for robotic hands with heterogeneous kinematic structures. Existing methods are often tailored to specific hand designs and fail to generalize to unseen hand morphologies outside the training distribution. To address these limitations, we propose \textbf{UniMorphGrasp}, a diffusion-based framework that incorporates hand morphological information into the grasp generation process for unified cross-embodiment grasp synthesis. The proposed approach maps grasps from diverse robotic hands into a unified human-like canonical hand pose representation, providing a common space for learning. Grasp generation is then conditioned on structured representations of hand kinematics, encoded as graphs derived from hand configurations, together with object geometry. In addition, a loss function is introduced that exploits the hierarchical organization of hand kinematics to guide joint-level supervision. Extensive experiments demonstrate that UniMorphGrasp achieves state-of-the-art performance on existing dexterous grasp benchmarks and exhibits strong zero-shot generalization to previously unseen hand structures, enabling scalable and practical cross-embodiment grasp deployment.
MaDiS: Taming Masked Diffusion Language Models for Sign Language Generation
Jan 27, 2026Sign language generation (SLG) aims to translate written texts into expressive sign motions, bridging communication barriers for the Deaf and Hard-of-Hearing communities. Recent studies formulate SLG within the language modeling framework using autoregressive language models, which suffer from unidirectional context modeling and slow token-by-token inference. To address these limitations, we present MaDiS, a masked-diffusion-based language model for SLG that captures bidirectional dependencies and supports efficient parallel multi-token generation. We further introduce a tri-level cross-modal pretraining scheme that jointly learns from token-, latent-, and 3D physical-space objectives, leading to richer and more grounded sign representations. To accelerate model convergence in the fine-tuning stage, we design a novel unmasking strategy with temporal checkpoints, reducing the combinatorial complexity of unmasking orders by over $10^{41}$ times. In addition, a mixture-of-parts embedding layer is developed to effectively fuse information stored in different part-wise sign tokens through learnable gates and well-optimized codebooks. Extensive experiments on CSL-Daily, Phoenix-2014T, and How2Sign demonstrate that MaDiS achieves superior performance across multiple metrics, including DTW error and two newly introduced metrics, SiBLEU and SiCLIP, while reducing inference latency by nearly 30%. Code and models will be released on our project page.
Interact2Ar: Full-Body Human-Human Interaction Generation via Autoregressive Diffusion Models
Dec 22, 2025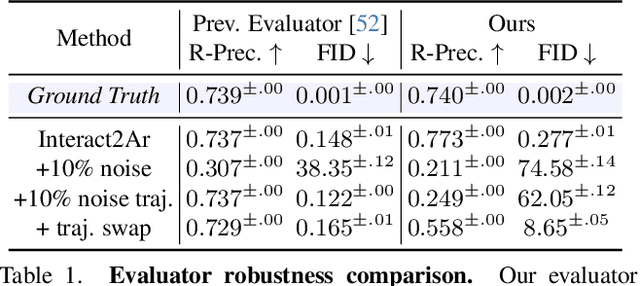
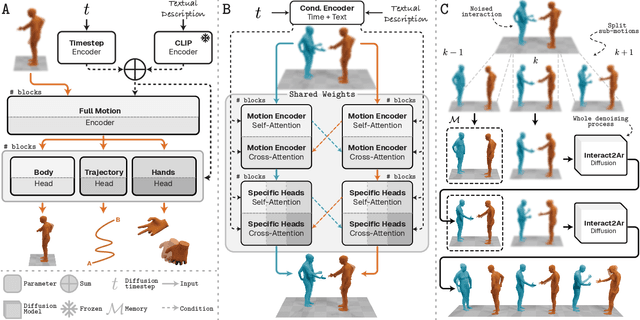
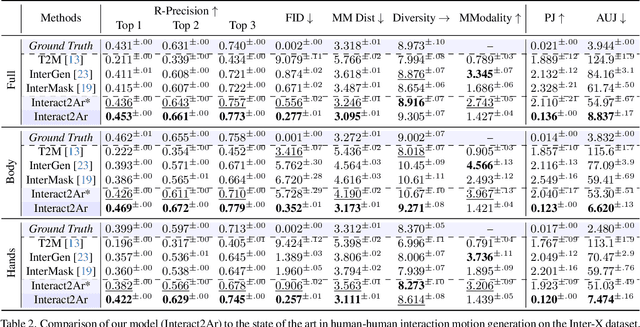
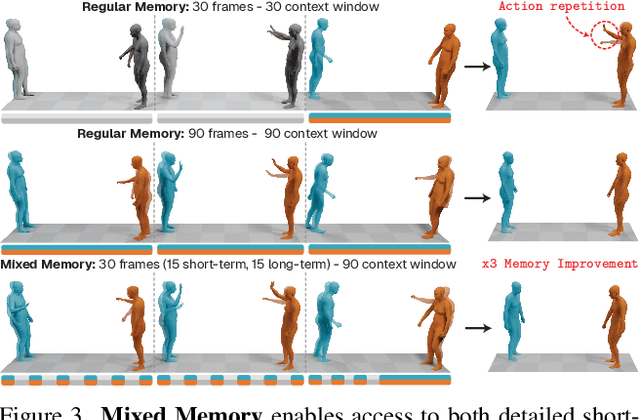
Generating realistic human-human interactions is a challenging task that requires not only high-quality individual body and hand motions, but also coherent coordination among all interactants. Due to limitations in available data and increased learning complexity, previous methods tend to ignore hand motions, limiting the realism and expressivity of the interactions. Additionally, current diffusion-based approaches generate entire motion sequences simultaneously, limiting their ability to capture the reactive and adaptive nature of human interactions. To address these limitations, we introduce Interact2Ar, the first end-to-end text-conditioned autoregressive diffusion model for generating full-body, human-human interactions. Interact2Ar incorporates detailed hand kinematics through dedicated parallel branches, enabling high-fidelity full-body generation. Furthermore, we introduce an autoregressive pipeline coupled with a novel memory technique that facilitates adaptation to the inherent variability of human interactions using efficient large context windows. The adaptability of our model enables a series of downstream applications, including temporal motion composition, real-time adaptation to disturbances, and extension beyond dyadic to multi-person scenarios. To validate the generated motions, we introduce a set of robust evaluators and extended metrics designed specifically for assessing full-body interactions. Through quantitative and qualitative experiments, we demonstrate the state-of-the-art performance of Interact2Ar.
STARCaster: Spatio-Temporal AutoRegressive Video Diffusion for Identity- and View-Aware Talking Portraits
Dec 15, 2025


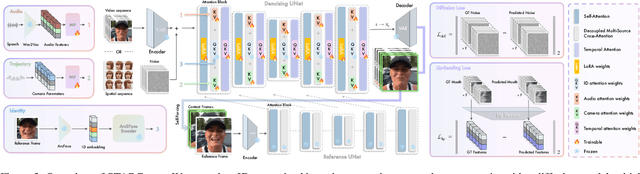
This paper presents STARCaster, an identity-aware spatio-temporal video diffusion model that addresses both speech-driven portrait animation and free-viewpoint talking portrait synthesis, given an identity embedding or reference image, within a unified framework. Existing 2D speech-to-video diffusion models depend heavily on reference guidance, leading to limited motion diversity. At the same time, 3D-aware animation typically relies on inversion through pre-trained tri-plane generators, which often leads to imperfect reconstructions and identity drift. We rethink reference- and geometry-based paradigms in two ways. First, we deviate from strict reference conditioning at pre-training by introducing softer identity constraints. Second, we address 3D awareness implicitly within the 2D video domain by leveraging the inherent multi-view nature of video data. STARCaster adopts a compositional approach progressing from ID-aware motion modeling, to audio-visual synchronization via lip reading-based supervision, and finally to novel view animation through temporal-to-spatial adaptation. To overcome the scarcity of 4D audio-visual data, we propose a decoupled learning approach in which view consistency and temporal coherence are trained independently. A self-forcing training scheme enables the model to learn from longer temporal contexts than those generated at inference, mitigating the overly static animations common in existing autoregressive approaches. Comprehensive evaluations demonstrate that STARCaster generalizes effectively across tasks and identities, consistently surpassing prior approaches in different benchmarks.
HORT: Monocular Hand-held Objects Reconstruction with Transformers
Mar 27, 2025



Reconstructing hand-held objects in 3D from monocular images remains a significant challenge in computer vision. Most existing approaches rely on implicit 3D representations, which produce overly smooth reconstructions and are time-consuming to generate explicit 3D shapes. While more recent methods directly reconstruct point clouds with diffusion models, the multi-step denoising makes high-resolution reconstruction inefficient. To address these limitations, we propose a transformer-based model to efficiently reconstruct dense 3D point clouds of hand-held objects. Our method follows a coarse-to-fine strategy, first generating a sparse point cloud from the image and progressively refining it into a dense representation using pixel-aligned image features. To enhance reconstruction accuracy, we integrate image features with 3D hand geometry to jointly predict the object point cloud and its pose relative to the hand. Our model is trained end-to-end for optimal performance. Experimental results on both synthetic and real datasets demonstrate that our method achieves state-of-the-art accuracy with much faster inference speed, while generalizing well to in-the-wild images.
Arc2Avatar: Generating Expressive 3D Avatars from a Single Image via ID Guidance
Jan 09, 2025Inspired by the effectiveness of 3D Gaussian Splatting (3DGS) in reconstructing detailed 3D scenes within multi-view setups and the emergence of large 2D human foundation models, we introduce Arc2Avatar, the first SDS-based method utilizing a human face foundation model as guidance with just a single image as input. To achieve that, we extend such a model for diverse-view human head generation by fine-tuning on synthetic data and modifying its conditioning. Our avatars maintain a dense correspondence with a human face mesh template, allowing blendshape-based expression generation. This is achieved through a modified 3DGS approach, connectivity regularizers, and a strategic initialization tailored for our task. Additionally, we propose an optional efficient SDS-based correction step to refine the blendshape expressions, enhancing realism and diversity. Experiments demonstrate that Arc2Avatar achieves state-of-the-art realism and identity preservation, effectively addressing color issues by allowing the use of very low guidance, enabled by our strong identity prior and initialization strategy, without compromising detail.
HaWoR: World-Space Hand Motion Reconstruction from Egocentric Videos
Jan 06, 2025Despite the advent in 3D hand pose estimation, current methods predominantly focus on single-image 3D hand reconstruction in the camera frame, overlooking the world-space motion of the hands. Such limitation prohibits their direct use in egocentric video settings, where hands and camera are continuously in motion. In this work, we propose HaWoR, a high-fidelity method for hand motion reconstruction in world coordinates from egocentric videos. We propose to decouple the task by reconstructing the hand motion in the camera space and estimating the camera trajectory in the world coordinate system. To achieve precise camera trajectory estimation, we propose an adaptive egocentric SLAM framework that addresses the shortcomings of traditional SLAM methods, providing robust performance under challenging camera dynamics. To ensure robust hand motion trajectories, even when the hands move out of view frustum, we devise a novel motion infiller network that effectively completes the missing frames of the sequence. Through extensive quantitative and qualitative evaluations, we demonstrate that HaWoR achieves state-of-the-art performance on both hand motion reconstruction and world-frame camera trajectory estimation under different egocentric benchmark datasets. Code and models are available on https://hawor-project.github.io/ .
Signs as Tokens: An Autoregressive Multilingual Sign Language Generator
Nov 26, 2024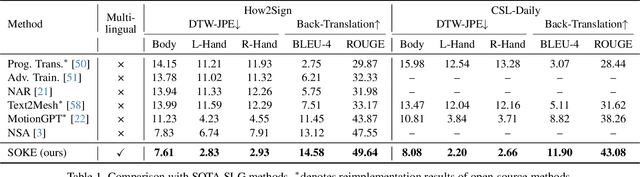
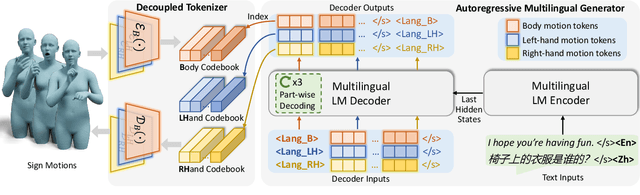
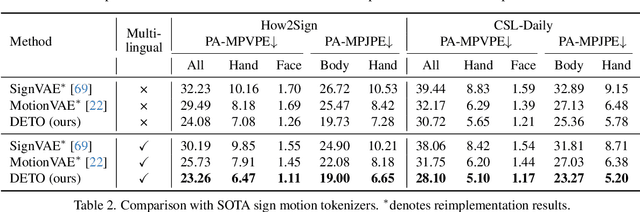

Sign language is a visual language that encompasses all linguistic features of natural languages and serves as the primary communication method for the deaf and hard-of-hearing communities. While many studies have successfully adapted pretrained language models (LMs) for sign language translation (sign-to-text), drawing inspiration from its linguistic characteristics, the reverse task of sign language generation (SLG, text-to-sign) remains largely unexplored. Most existing approaches treat SLG as a visual content generation task, employing techniques such as diffusion models to produce sign videos, 2D keypoints, or 3D avatars based on text inputs, overlooking the linguistic properties of sign languages. In this work, we introduce a multilingual sign language model, Signs as Tokens (SOKE), which can generate 3D sign avatars autoregressively from text inputs using a pretrained LM. To align sign language with the LM, we develop a decoupled tokenizer that discretizes continuous signs into token sequences representing various body parts. These sign tokens are integrated into the raw text vocabulary of the LM, allowing for supervised fine-tuning on sign language datasets. To facilitate multilingual SLG research, we further curate a large-scale Chinese sign language dataset, CSL-Daily, with high-quality 3D pose annotations. Extensive qualitative and quantitative evaluations demonstrate the effectiveness of SOKE. The project page is available at https://2000zrl.github.io/soke/.