 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAVEN: Real-time Autoregressive Video Extrapolation with Consistency-model GRPO
May 14, 2026Causal autoregressive video diffusion models support real-time streaming generation by extrapolating future chunks from previously generated content. Distilling such generators from high-fidelity bidirectional teachers yields competitive few-step models, yet a persistent gap between the history distributions encountered during training and those arising at inference constrains generation quality over long horizons. We introduce the Real-time Autoregressive Video Extrapolation Network (RAVEN), a training-time test framework that repacks each self rollout into an interleaved sequence of clean historical endpoints and noisy denoising states. This formulation aligns training attention with inference-time extrapolation and allows downstream chunk losses to supervise the history representations on which future predictions depend. We further propose Consistency-model Group Relative Policy Optimization (CM-GRPO), which reformulates a consistency sampling step as a conditional Gaussian transition and applies online Reinforcement Learning (RL) directly to this kernel, avoiding the Euler-Maruyama auxiliary process adopted in prior flow-model RL formulations. Experiments demonstrate that RAVEN surpasses recent causal video distillation baselines across quality, semantic, and dynamic degree evaluations, and that CM-GRPO provides further gains when combined with RAVEN.
MaDiS: Taming Masked Diffusion Language Models for Sign Language Generation
Jan 27, 2026Sign language generation (SLG) aims to translate written texts into expressive sign motions, bridging communication barriers for the Deaf and Hard-of-Hearing communities. Recent studies formulate SLG within the language modeling framework using autoregressive language models, which suffer from unidirectional context modeling and slow token-by-token inference. To address these limitations, we present MaDiS, a masked-diffusion-based language model for SLG that captures bidirectional dependencies and supports efficient parallel multi-token generation. We further introduce a tri-level cross-modal pretraining scheme that jointly learns from token-, latent-, and 3D physical-space objectives, leading to richer and more grounded sign representations. To accelerate model convergence in the fine-tuning stage, we design a novel unmasking strategy with temporal checkpoints, reducing the combinatorial complexity of unmasking orders by over $10^{41}$ times. In addition, a mixture-of-parts embedding layer is developed to effectively fuse information stored in different part-wise sign tokens through learnable gates and well-optimized codebooks. Extensive experiments on CSL-Daily, Phoenix-2014T, and How2Sign demonstrate that MaDiS achieves superior performance across multiple metrics, including DTW error and two newly introduced metrics, SiBLEU and SiCLIP, while reducing inference latency by nearly 30%. Code and models will be released on our project page.
Signs as Tokens: An Autoregressive Multilingual Sign Language Generator
Nov 26, 2024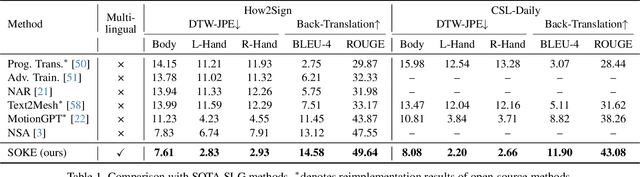
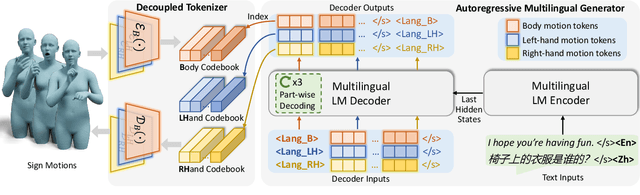

Sign language is a visual language that encompasses all linguistic features of natural languages and serves as the primary communication method for the deaf and hard-of-hearing communities. While many studies have successfully adapted pretrained language models (LMs) for sign language translation (sign-to-text), drawing inspiration from its linguistic characteristics, the reverse task of sign language generation (SLG, text-to-sign) remains largely unexplored. Most existing approaches treat SLG as a visual content generation task, employing techniques such as diffusion models to produce sign videos, 2D keypoints, or 3D avatars based on text inputs, overlooking the linguistic properties of sign languages. In this work, we introduce a multilingual sign language model, Signs as Tokens (SOKE), which can generate 3D sign avatars autoregressively from text inputs using a pretrained LM. To align sign language with the LM, we develop a decoupled tokenizer that discretizes continuous signs into token sequences representing various body parts. These sign tokens are integrated into the raw text vocabulary of the LM, allowing for supervised fine-tuning on sign language datasets. To facilitate multilingual SLG research, we further curate a large-scale Chinese sign language dataset, CSL-Daily, with high-quality 3D pose annotations. Extensive qualitative and quantitative evaluations demonstrate the effectiveness of SOKE. The project page is available at https://2000zrl.github.io/soke/.
A Hong Kong Sign Language Corpus Collected from Sign-interpreted TV News
May 02, 2024



This paper introduces TVB-HKSL-News, a new Hong Kong sign language (HKSL) dataset collected from a TV news program over a period of 7 months. The dataset is collected to enrich resources for HKSL and support research in large-vocabulary continuous sign language recognition (SLR) and translation (SLT). It consists of 16.07 hours of sign videos of two signers with a vocabulary of 6,515 glosses (for SLR) and 2,850 Chinese characters or 18K Chinese words (for SLT). One signer has 11.66 hours of sign videos and the other has 4.41 hours. One objective in building the dataset is to support the investigation of how well large-vocabulary continuous sign language recognition/translation can be done for a single signer given a (relatively) large amount of his/her training data, which could potentially lead to the development of new modeling methods. Besides, most parts of the data collection pipeline are automated with little human intervention; we believe that our collection method can be scaled up to collect more sign language data easily for SLT in the future for any sign languages if such sign-interpreted videos are available. We also run a SOTA SLR/SLT model on the dataset and get a baseline SLR word error rate of 34.08% and a baseline SLT BLEU-4 score of 23.58 for benchmarking future research on the dataset.
Towards Online Sign Language Recognition and Translation
Jan 10, 2024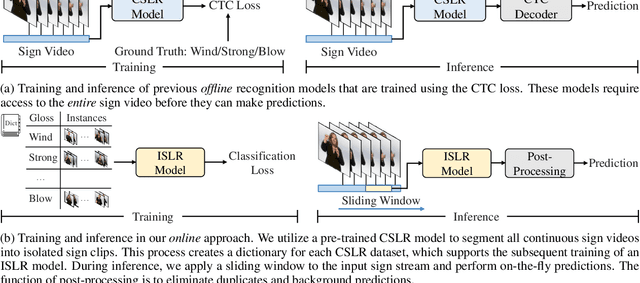
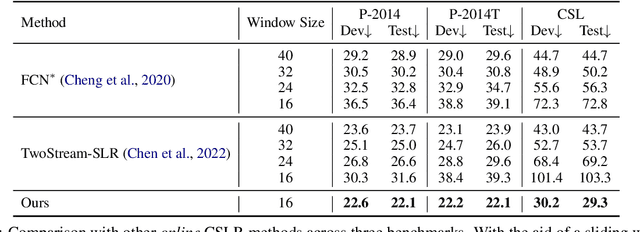
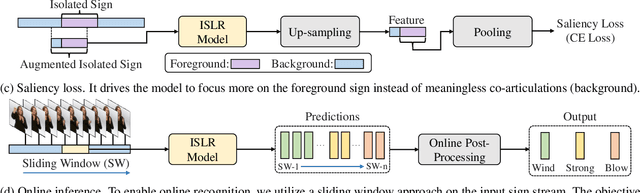
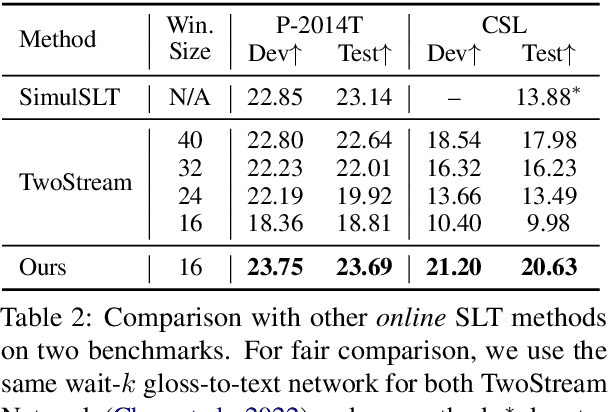
The objective of sign language recognition is to bridge the communication gap between the deaf and the hearing. Numerous previous works train their models using the well-established connectionist temporal classification (CTC) loss. During the inference stage, the CTC-based models typically take the entire sign video as input to make predictions. This type of inference scheme is referred to as offline recognition. In contrast, while mature speech recognition systems can efficiently recognize spoken words on the fly, sign language recognition still falls short due to the lack of practical online solutions. In this work, we take the first step towards filling this gap. Our approach comprises three phases: 1) developing a sign language dictionary encompassing all glosses present in a target sign language dataset; 2) training an isolated sign language recognition model on augmented signs using both conventional classification loss and our novel saliency loss; 3) employing a sliding window approach on the input sign sequence and feeding each sign clip to the well-optimized model for online recognition. Furthermore, our online recognition model can be extended to boost the performance of any offline model, and to support online translation by appending a gloss-to-text network onto the recognition model. By integrating our online framework with the previously best-performing offline model, TwoStream-SLR, we achieve new state-of-the-art performance on three benchmarks: Phoenix-2014, Phoenix-2014T, and CSL-Daily. Code and models will be available at https://github.com/FangyunWei/SLRT
A Simple Baseline for Spoken Language to Sign Language Translation with 3D Avatars
Jan 09, 2024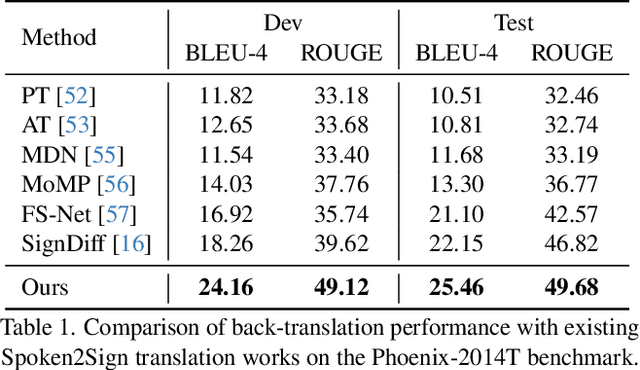
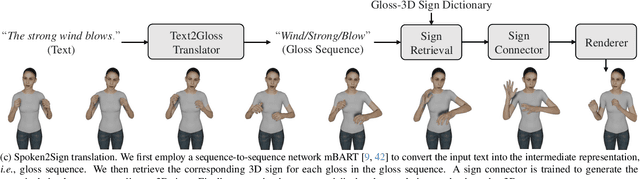
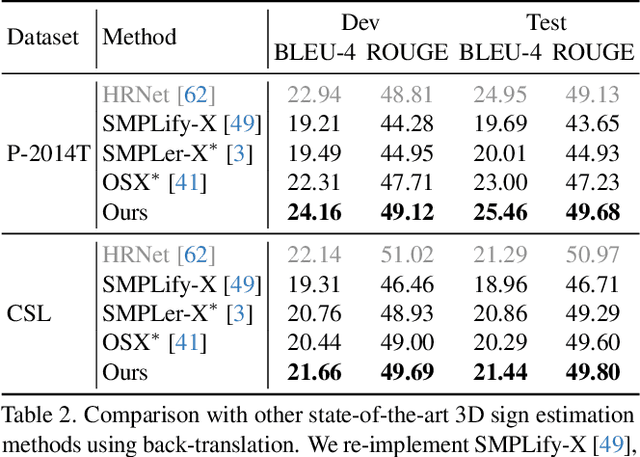
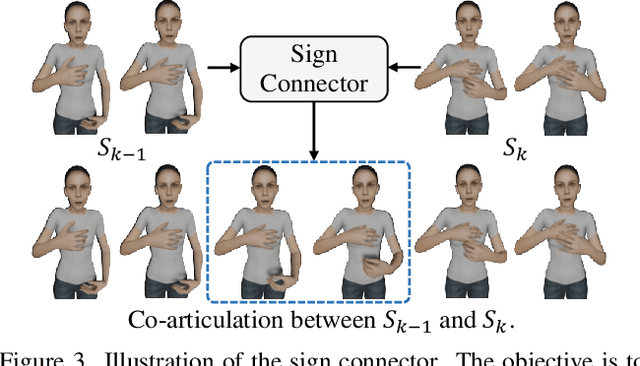
The objective of this paper is to develop a functional system for translating spoken languages into sign languages, referred to as Spoken2Sign translation. The Spoken2Sign task is orthogonal and complementary to traditional sign language to spoken language (Sign2Spoken) translation. To enable Spoken2Sign translation, we present a simple baseline consisting of three steps: 1) creating a gloss-video dictionary using existing Sign2Spoken benchmarks; 2) estimating a 3D sign for each sign video in the dictionary; 3) training a Spoken2Sign model, which is composed of a Text2Gloss translator, a sign connector, and a rendering module, with the aid of the yielded gloss-3D sign dictionary. The translation results are then displayed through a sign avatar. As far as we know, we are the first to present the Spoken2Sign task in an output format of 3D signs. In addition to its capability of Spoken2Sign translation, we also demonstrate that two by-products of our approach-3D keypoint augmentation and multi-view understanding-can assist in keypoint-based sign language understanding. Code and models will be available at https://github.com/FangyunWei/SLRT
Natural Language-Assisted Sign Language Recognition
Mar 21, 2023
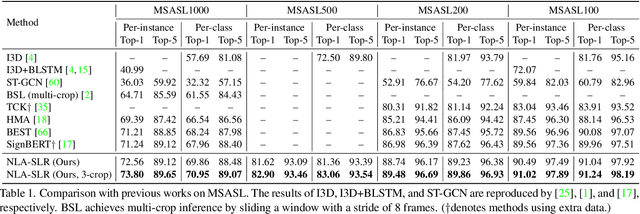
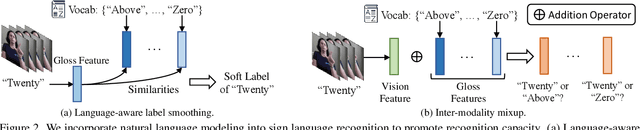
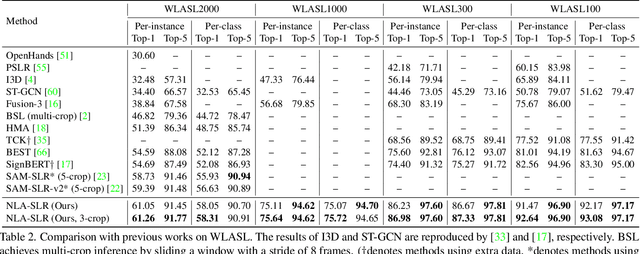
Sign languages are visual languages which convey information by signers' handshape, facial expression, body movement, and so forth. Due to the inherent restriction of combinations of these visual ingredients, there exist a significant number of visually indistinguishable signs (VISigns) in sign languages, which limits the recognition capacity of vision neural networks. To mitigate the problem, we propose the Natural Language-Assisted Sign Language Recognition (NLA-SLR) framework, which exploits semantic information contained in glosses (sign labels). First, for VISigns with similar semantic meanings, we propose language-aware label smoothing by generating soft labels for each training sign whose smoothing weights are computed from the normalized semantic similarities among the glosses to ease training. Second, for VISigns with distinct semantic meanings, we present an inter-modality mixup technique which blends vision and gloss features to further maximize the separability of different signs under the supervision of blended labels. Besides, we also introduce a novel backbone, video-keypoint network, which not only models both RGB videos and human body keypoints but also derives knowledge from sign videos of different temporal receptive fields. Empirically, our method achieves state-of-the-art performance on three widely-adopted benchmarks: MSASL, WLASL, and NMFs-CSL. Codes are available at https://github.com/FangyunWei/SLRT.
Improving Continuous Sign Language Recognition with Consistency Constraints and Signer Removal
Dec 26, 2022



Most deep-learning-based continuous sign language recognition (CSLR) models share a similar backbone consisting of a visual module, a sequential module, and an alignment module. However, due to limited training samples, a connectionist temporal classification loss may not train such CSLR backbones sufficiently. In this work, we propose three auxiliary tasks to enhance the CSLR backbones. The first task enhances the visual module, which is sensitive to the insufficient training problem, from the perspective of consistency. Specifically, since the information of sign languages is mainly included in signers' facial expressions and hand movements, a keypoint-guided spatial attention module is developed to enforce the visual module to focus on informative regions, i.e., spatial attention consistency. Second, noticing that both the output features of the visual and sequential modules represent the same sentence, to better exploit the backbone's power, a sentence embedding consistency constraint is imposed between the visual and sequential modules to enhance the representation power of both features. We name the CSLR model trained with the above auxiliary tasks as consistency-enhanced CSLR, which performs well on signer-dependent datasets in which all signers appear during both training and testing. To make it more robust for the signer-independent setting, a signer removal module based on feature disentanglement is further proposed to remove signer information from the backbone. Extensive ablation studies are conducted to validate the effectiveness of these auxiliary tasks. More remarkably, with a transformer-based backbone, our model achieves state-of-the-art or competitive performance on five benchmarks, PHOENIX-2014, PHOENIX-2014-T, PHOENIX-2014-SI, CSL, and CSL-Daily.
Two-Stream Network for Sign Language Recognition and Translation
Nov 02, 2022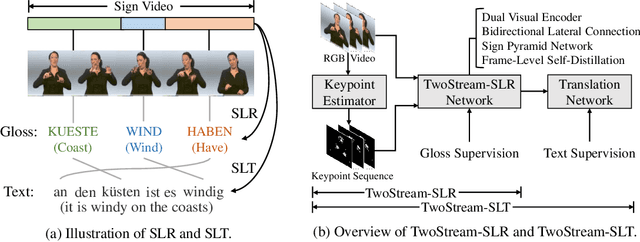
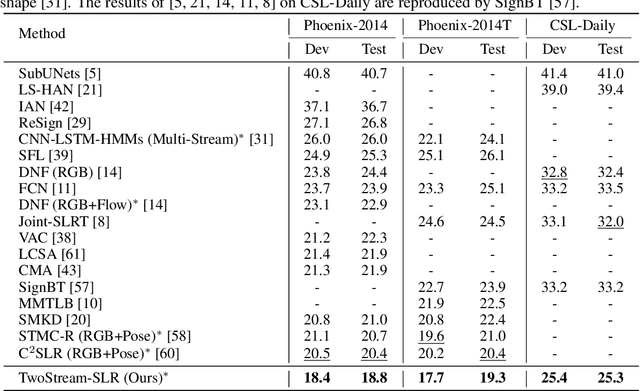
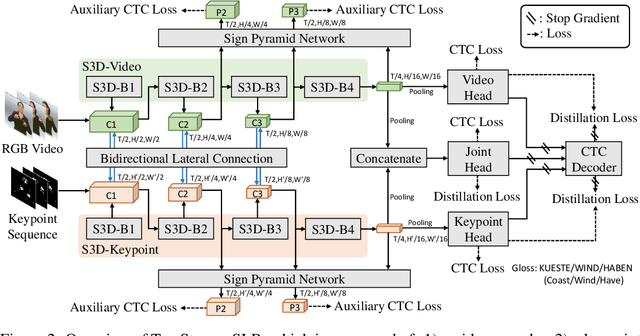
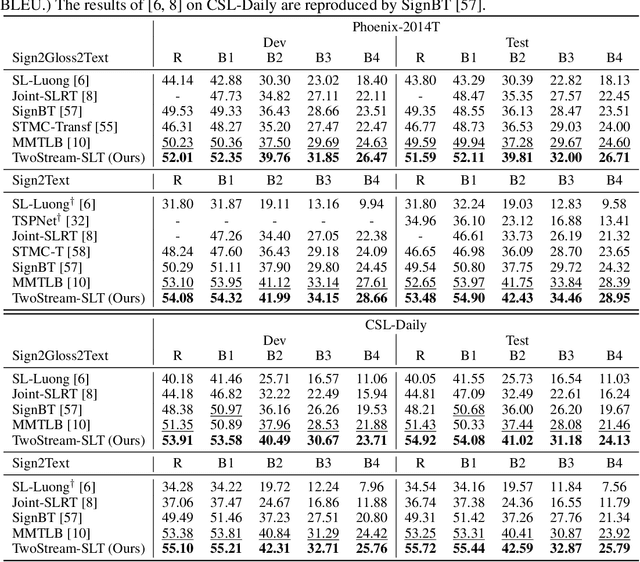
Sign languages are visual languages using manual articulations and non-manual elements to convey information. For sign language recognition and translation, the majority of existing approaches directly encode RGB videos into hidden representations. RGB videos, however, are raw signals with substantial visual redundancy, leading the encoder to overlook the key information for sign language understanding. To mitigate this problem and better incorporate domain knowledge, such as handshape and body movement, we introduce a dual visual encoder containing two separate streams to model both the raw videos and the keypoint sequences generated by an off-the-shelf keypoint estimator. To make the two streams interact with each other, we explore a variety of techniques, including bidirectional lateral connection, sign pyramid network with auxiliary supervision, and frame-level self-distillation. The resulting model is called TwoStream-SLR, which is competent for sign language recognition (SLR). TwoStream-SLR is extended to a sign language translation (SLT) model, TwoStream-SLT, by simply attaching an extra translation network. Experimentally, our TwoStream-SLR and TwoStream-SLT achieve state-of-the-art performance on SLR and SLT tasks across a series of datasets including Phoenix-2014, Phoenix-2014T, and CSL-Daily.